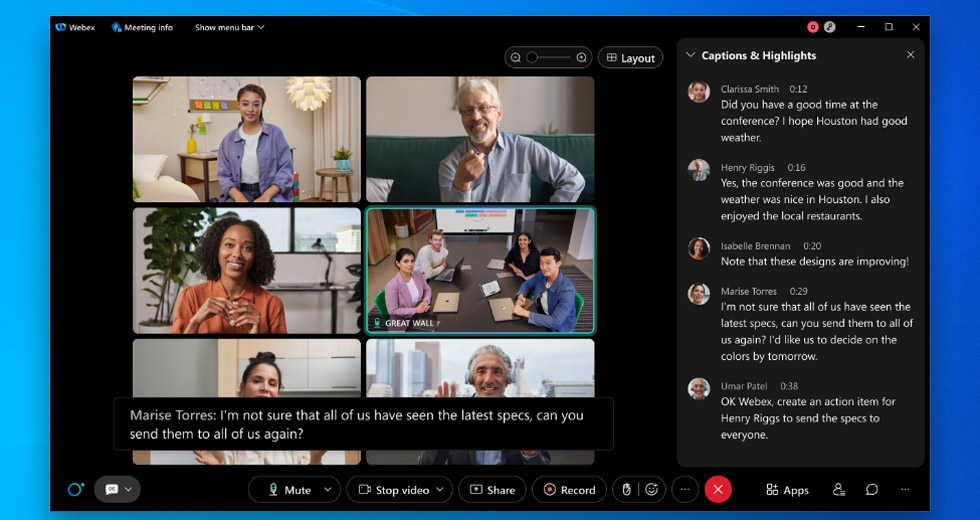
Seit wir 2020 Webex Assistant eingeführt haben, lautet die meistgestellte Frage unserer Kunden: „Ist er genau?“ Das ist nachvollziehbar. Kunden wollen sicherstellen, dass, wenn sie sich entscheiden, die KI-gesteuerte (Künstliche Intelligenz) automatische Transkriptions-Engine von Webex zu verwenden, diese ihr Versprechen hält. D. h. sie soll genaue Meetingaufzeichnungen vornehmen, es Mitarbeitern ermöglichen, sich auf das Gespräch zu konzentrieren, anstatt auf das Abtippen von Notizen und durch Funktionen für die Barrierefreiheit für mehr Inklusion in Meetings sorgen. Es gibt so viele Beispiele, in welchen künstliche Intelligenz zu viel verspricht und zu wenig liefert. Für unternehmenskritische Aufgaben hat Webex keine Mühen gescheut und sich unermüdlich darauf konzentriert an der Genauigkeit zu arbeiten. Während weltweit auf ein hybrides Arbeitsmodell umgestiegen wird, werden Funktionen wie Untertitel, Abschriften und das Erfassen von Aktionselementen wichtiger denn je, um gleichwertige, inklusive Meetingerfahrungen zu ermöglichen. Und das ganz unabhängig davon, welche Sprache Benutzer verwenden, welche Anforderungen sie im Bereich der Barrierefreiheit haben, oder ob sie sich entscheiden, ein Meeting auszulassen, um alle Termine unterzubekommen und sich auf eine Zusammenfassung von Webex Assistant verlassen. Unser Ziel ist es, KI und maschinelles Lernen zu nutzen, um alle Meetingerfahrungen für alle besser zu machen. Das Erschaffen von hochmodernen KI-gesteuerten Transkriptions-Engines ist eine Möglichkeit, dieses Ziel zu erreichen. Berücksichtigt man, was Webex investiert hat, um eine robuste Pipeline für die durchgängige Kennzeichnung, das Training und maschinelles Lernen zu erschaffen, sind wir stolz darauf, auf dieser Grundlage eine Transkriptions-Engine für die englische Sprache auf den Markt bringen zu können. Diese ist in Sachen Genauigkeit für die Webex Meetingerfahrung branchenführend, wenn man sie mit den besten Spracherkennungsengines auf dem Markt vergleicht. Mit dem Ziel, mehr als 98 % der Webex-Kunden Zugang zu unserer Technologie zu verschaffen, werden wir ASRs (Engines für die automatische Spracherkennung) für Spanisch, Französisch und Deutsch zur Verfügung stellen, die vollständig von uns entwickelt werden. Das Angebot ist in der ersten Hälfte dieses Jahres für alle Benutzer von Webex Assistant kostenlos. 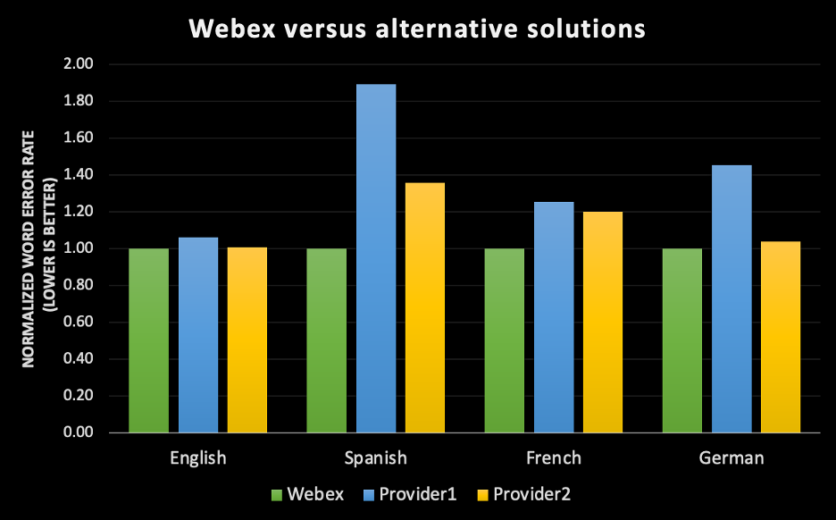


 Siehe folgendes Beispiel
Siehe folgendes Beispiel 





Was bedeutet „genau“ eigentlich wirklich?
Wenn wir über die genaue Transkription nachdenken, stellen wir uns häufig vor, dass ein menschlicher Zuhörer, der die Audiodatei transkribiert, exakt das wiedergibt, was gesagt wird. Allerdings muss man das ins Verhältnis setzen. Die Fehlerquote bei Menschen wurde in beliebten Datensätzen wie „CallHome“ gemessen und das beste Ergebnis liegt derzeit bei 6,8 %. D. h. bei einem Transkript mit 100 Wörtern, würden ca. 7 davon durch einen Menschen falsch übertragen werden. Es muss außerdem Erwähnung finden, dass „CallHome“ ein Datensatz ist, der aus 30-minütigen Telefongesprächen zwischen englischen Muttersprachlern mit spontanem Inhalt besteht. [1] Man kann davon ausgehen, dass die Fehlerquote bei Gesprächen von Personen, die verschiedene Akzente aufweisen, höher ist. Noch interessanter ist, dass die Übertragungsübereinstimmung von Transkriptoren laut des Linguistics Data Consortium (LDC) zwischen 4,1 % und 9,6 % liegt, abhängig davon, ob es sich um gewissenhafte Mehrfachabschriften oder eine Schnellabschrift handelt [2]. Das bedeutet, dass wenn 2 Personen die gleiche Audiodatei erhalten, trotzdem keine identischen Aufzeichnungen des Gesagten entstehen, selbst wenn die Umgebungsbedingungen perfekt sind. Unser Ziel ist es, dass die Abschrift von Webex nicht nur auf einem Niveau mit der Abschrift durch Menschen, sondern dass sie besser ist. Wir möchten in jeder Sprache, die wir anbieten erstklassige Genauigkeit erzielen, unabhängig von Akzent, Geschlecht oder Umgebung. Um also die Frage „Ist er genau?“ beantworten zu können, müssen wir zuerst die verschiedenen Dimensionen der Genauigkeit in der automatischen Spracherkennung darlegen:1. Genauigkeit wird unter Verwendung einer gängigen Metrik gemessen, der Wortfehlerrate (Word Error Rate, WER)
- WER misst die Leistung der Maschine in Bezug auf die Transkription des Gesagten.
- Dieselbe Audioaufnahme, die das Modell für maschinelles Lernen (ML) übertragen hat, erhalten Personen, um eine inhaltliche Grundwahrheit für die Abschrift zu schaffen.
- Die Wortfehlerrate (WER) berechnet sich aus der Anzahl der Fehler dividiert durch die Gesamtanzahl der Wörter. Beginnen Sie die Berechnung der WER, indem Sie Ersetzungen, Einfügungen und Streichungen addieren, die in einer Sequenz erkannter Wörter vorkommen. Teilen Sie diese Zahl durch die Gesamtanzahl der Wörter, die durch die inhaltliche Grundwahrheit ermittelt wurde. Das Ergebnis ist dann die WER. Als einfache Formel dargestellt: Wortfehlerrate WER = (Ersetzungen + Einfügungen + Streichungen) / Anzahl der gesprochenen Wörter. [3]
- Eine Ersetzung erfolgt, wenn ein Wort ersetzt wird (z. B. wird aus dem Namen „Willi“, die Verbform „will“).
- Eine Einfügung ist, wenn ein Wort, das im Gesagten nicht vor kam, hinzugefügt wurde (z. B. wird „mittendrin“ zu „mitten in“).
- Eine Streichung erfolgt, wenn ein Wort im Transkript komplett fehlt (z. B. wird „ich kann nicht mit“ zu „ich kann mit“).
- Je niedriger die WER; desto höher ist die Genauigkeit der Transkriptions-Engine, d. h. desto weniger Fehler treten auf.
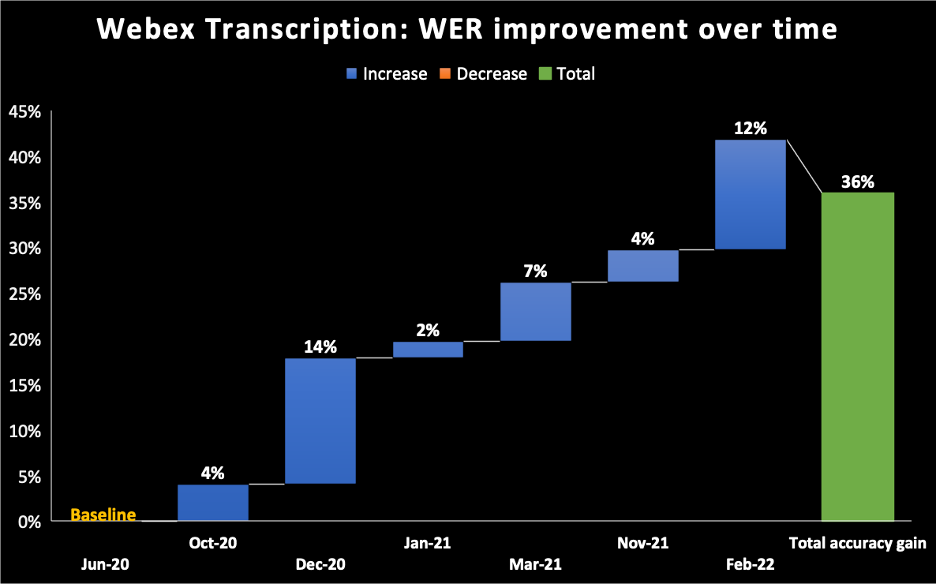
- Im folgenden Diagramm dient Juni 2020 als Basis für das Modell, das wir für die KI-gesteuerte Transkriptions-Engine von Webex Assistant geliefert haben. Man sieht, dass wir die WER im Verlauf der Zeit verbessert haben und bis Februar 2022 schrittweise Verbesserungen von 36 % erreicht haben.
2. Alles hängt vom Datensatz ab
- Die WER einer beliebigen Spracherkennungsengine ist nicht allgemeingültig messbar. Jeder Datensatz verfügt über verschiedene Attribute wie die Verteilung von Dialekten, Geschlechtern, der akustischen Umgebung und Domänen. D. h. der Einsatz der Transkriptions-Engine von Webex bei einem Datensatz, der aus Hörbüchern besteht, würde eine andere WER ergeben als bei Webex Meetings und wieder eine andere bei Telefongesprächen. Genauso käme die Transkriptions-Engine bei einem Webex Meeting, an welchem ausschließlich englische Muttersprachler teilnehmen zu einer anderen Fehlerrate, als bei einem Webex Meeting, bei welchem Teilnehmer unterschiedliche Akzente aufweisen.
- Um eine erstklassige Genauigkeit aufweisen zu können, konzentrieren wir uns ausschließlich auf Anwendungsfälle bei Videokonferenzen. Es gibt viele Unterschiede in der Sprechweise von Menschen in Videokonferenzen, verglichen mit Telefongesprächen oder Sprachbefehlen an Alexa. Unsere Spracherkennungsengines nehmen diese besonderen Muster wahr und optimieren sie für Videokonferenzen. Wenn wir eine ASR-Engine bei uns im Haus fertigen, anstatt uns auf Drittanbieter zu verlassen, können wir unsere Modelle für maschinelles Lernen anhand dieser Attribute1 trainieren, die speziell auf die Webex-Meetingerfahrung zutreffen.
3. Die Genauigkeit wird im Meetingverlauf größer
- Unsere automatische Spracherkennung (ASR) schafft während des gesamten Meetingverlaufs drei Arten von Abschriften.
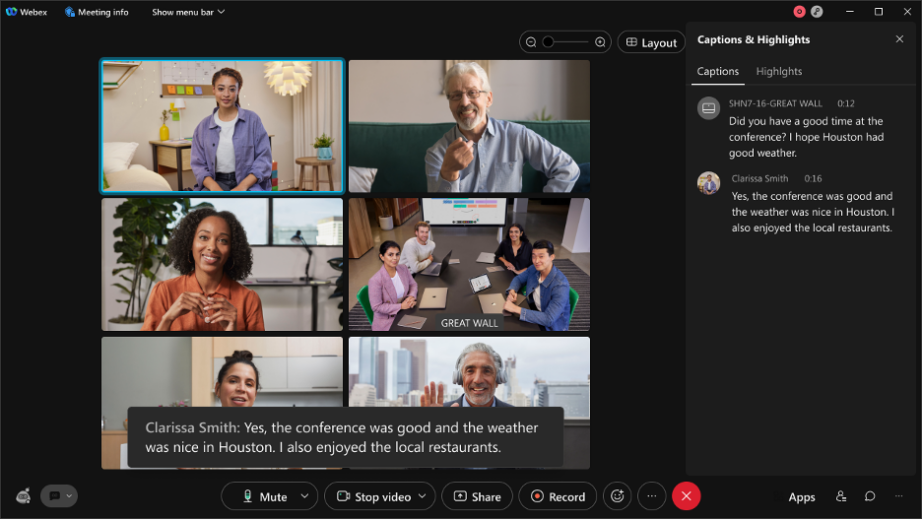
- Äußerungsentwurf/vorläufige Äußerung: der Äußerungsentwurf ist das, was Sie in Echtzeit sehen. Wenn Sie sich die Untertitel in einem Webex-Meeting ansehen [schwarzes Kästchen im folgenden Screenshot], während Sie sprechen, entsteht in den ersten Millisekunden des Transkribierens eine Entwurfsabschrift. Das ist die erste Abschrift, die Sie sehen können. Wir nennen sie Online-/Streaming-Audioabschrift.
- Finale Äußerung: Nach ein paar Millisekunden entsteht eine Abschrift mit einer höheren Genauigkeit. All das geschieht in Echtzeit und lässt sich mit dem bloßen Auge kaum unterscheiden.
Siehe folgendes Beispiel - In diesem Beispiel wurden für eine Äußerung in einem unserer Team-Meetings 13 Entwürfe erstellt. All das geschieht in Echtzeit, um im letzten Satz die höchste Genauigkeit aufzuweisen und gleichzeitig die Echtzeit-Erfahrung für den Benutzer zu sichern.
- Verbesserte Abschrift: Nachdem das Meeting zu Ende ist, wenden wir eine Reihe weiterer Transkriptions-Engines an, um die Genauigkeit der Abschrift weiter zu erhöhen. Verbesserte Abschriften sind unabhängig von der Dauer des Meetings innerhalb von durchschnittlich 10 Minuten verfügbar. Diese Abschrift ist dann die Version mit der höchsten Genauigkeit.
4. Weitere Themen, die sich auf die Wahrnehmung der Genauigkeit von Abschriften auswirken
- Zeichensetzung und Großschreibung:
- Obwohl die Abschrift genau ist, besteht die Möglichkeit, dass die Zeichensetzung oder Groß- und Kleinschreibung fehlerhaft ist. In jeder Sprache gibt es unterschiedliche Regeln in Bezug darauf und wir müssen unsere Modelle so trainieren, dass sie dazu in der Lage sind, diese Regeln zu berücksichtigen, sodass die Abschrift gut lesbar ist.
- Zeichensetzung und Großschreibung:

- Zuordnung zum Sprecher:
- Die Zuordnung zum Sprecher ordnet einen Textabschnitt einer Person zu und identifiziert, wer wann während eines Meetings gesprochen hat. Wenn eine Äußerung der falschen Person zugeordnet wird, sinkt die wahrgenommene Qualität. Die Zuordnung zum Sprecher ermöglicht uns, interessante Funktionen zu erstellen, wie Meetinganalysen in Bezug auf die Sprechzeiten der Teilnehmer.
- Umgang mit Abkürzungen und Namen:
- Spracherkennungsengines werden in der Regel mit Wörtern des gängigen Vokabulars trainiert. Dieses beinhaltet keine Namen von Personen, Abkürzungen von Unternehmensnamen, medizinische Fachsprache usw. Beispielsweise war das Akronym „COVID-19“ für die Menschen in der Zeit vor 2020 ein neuer Begriff. Unsere ASR wäre nicht dazu in der Lage gewesen, ihn zu erkennen, da er nicht zum gängigen Vokabular gehörte. Unser Team verfolgt verschiedene Ansätze, um eine genauere Abschrift von Wörtern, die nicht zum Vokabular gehören, zu gewährleisten, wie z. B. das Erlernen der Namen von Meetingteilnehmern während eines Meetings oder visuelle Verarbeitung, um Abkürzungen aus einer Präsentation, die im Meeting freigegeben wird, zu erlernen.
- Umgang mit Abkürzungen und Namen:
- Der Umgang mit Zahlen und besonderen Formaten:
- Manche Zahlen bedürfen einer besonderen Formatierung, wie z. B. Telefonnummern (+1 203 456 7891), E-Mails (jemand@email.com), Datumsangaben (15. April 2021). Modelle für maschinelles Lernen, die mit diesen besonderen Formaten trainiert wurden, erkennen gesprochene Wörter und verarbeiten den Text im Nachhinein, damit er im richtigen Format angezeigt wird. All das geschieht in Echtzeit.
- Der Umgang mit Zahlen und besonderen Formaten:
- Überlagerung von Gesprächen:
- Wenn Personen gleichzeitig sprechen oder einander unterbrechen, kann es passieren, dass die Abschrift unlesbar wird (selbst, wenn sie genau ist), wodurch die Qualitätswahrnehmung beeinflusst wird. Um dieses Problem zu lösen, erstellen wir Funktionen, die die Gesichts- und Stimmerkennung nutzen, um verschiedene Personen im Gespräch zu unterscheiden.
Haben wir unser Ziel schon erreicht?
Nicht ganz. Allerdings ist das ein Dauerlauf und kein Sprint. Wir sind überzeugt, dass das Fortsetzen des Trainings mit domänenspezifischen Daten, während wir danach streben, Abweichungen zu minimieren und Datenschutz und -sicherheit unserer Kunden zu gewährleisten dazu führen wird, dass die von uns entwickelte KI-gestützte Transkriptions-Engine von Webex bei der durch Menschen verursachten Wortfehlerrate mithalten können bzw. diese sogar übertreffen wird.
Weitere Informationen Der Beitritt zu Webex als Machine Learning Engineer: Ein Interview mit Ritvik Shrivastava Wie unser Streben nach inklusivem Audio/Video die Zukunft der Zusammenarbeit antreibt Die Neugestaltung des Arbeitens mit WebexWenn Sie es selbst ausprobieren möchten, registrieren Sie sich jetzt für eine kostenlose Testversion
About The Author

Mayada Abdelrahman Director of Product Management, AI/ML Cisco
Mayada Abdelrahman, leads product management for Speech AI/ML features designed for Webex including Cisco’s Webex Assistant, the first-of-its-kind enterprise digital meeting assistant.
In this role, Mayada drives the strategy and roadmap for speech AI/ML features for Webex with the goal of transforming the meeting experience and revolutionizing the way we work providing an inclusive meeting experience for everyone.
Prior to joining Cisco, Mayada led product and program management at Voicea, an AI/ML startup that built “Eva” the meeting assistant which was later acquired by Cisco in 2019.
Learn more


