
Last month our team celebrated the release of Webex Assistant for Devices in our fifth language, Japanese. Just three years ago, Webex Assistant was released in English, enabling users to control Webex Board, Room and Desk Series devices by voice command, simplifying common tasks like joining a scheduled meeting, calling a coworker for an impromptu huddle, adjusting the sound and camera, or checking the room schedule. Our team has worked diligently to add the same functionality in Spanish, French, German and now Japanese, and we are planning to release Italian and Portuguese this summer.
English is often treated as the assumed default in language technology, and it does function as the language of business communication in many contexts around the world among people who speak other languages in other public settings or at home. But the economies of English-dominant regions only account for about 30% of global GDP, and only about 25% of internet users prefer English content. A language-dependent product is doing a poor job of serving most of its potential users if the product and supporting documentation are not well-adapted to multiple languages. This is especially true for a voice interface, where user dialects and speech accents can easily affect the experience. Since Webex is a global brand with customers all over the world, delivering reliable smart interfaces in many languages is essential to fulfilling our commitment to inclusive experiences.
Internationalization is not translation
Internationalization is the process of adapting a product to make it amenable to new languages. It allows flexibility for text direction, measurement units, different writing systems, etc. Localization adapts a product to a specific language. These two concepts are strongly related, and one process feeds the other in a circular and iterative way. To avoid confusion, we will use internationalize and its derivatives to encompass both concepts.
On one hand, internationalization of a voice interface is much more complicated than internationalization of graphical UIs or of documentation (which are also essential to Webex’s mission). Yet adding support for more languages is much easier than the initial groundwork of developing Webex Assistant in the first language. There are, broadly, three kinds of challenges in internationalization of a natural language app like Webex Assistant.
First, there are the challenges typical of project management, matching resources with the work that needs to be done. This includes identifying and onboarding people who have both the linguistic expertise to have intuitive and explicit knowledge of possible language structures and their connections to meaning, as well as the computational expertise to efficiently search, generate, manipulate and annotate the variety of language structures, and to recognize what part of the NLP pipeline is responsible for outstanding error patterns. And then, successful delivery requires coordinating the work streams so that time is spent productively, and work builds on completed data while leaving flexibility to rework the data as understanding of the product evolves.
Second, there is the kind of challenge that comes from any machine learning data development, such as data collection, synthesis, annotation, and curation — evolving data at the same time as your understanding of the user and product develops. Despite the popular attention to the models in a machine learning system, the time and effort to develop, evaluate and deploy the models is usually dwarfed by the time and effort involved in developing the data necessary for training and evaluation of the models. At each step of the process, the team must draw from tentative intuitions and possibly unreliable data to decide the details of the next development step: When should we annotate one label instead of these similar labels? Should this kind of pattern be excluded from the data as out of scope or boosted in the data through further data collection or synthesis?
Finally, there are differences from language to language that require adapting the data process or algorithms to suit the language. At the same time, you need to maintain a common infrastructure and interface design that accommodates those differences. This encompasses the kinds of changes necessary for internationalization of a graphical UI, such as string length and script directionality, while extending beyond that to considerations of typical speech recognition errors, the grammatical flexibility of voice commands, the reliability of script-to-sound correspondences in the writing system, the “personality” of the voice replies, and natural conversation styles in each culture.
App development process
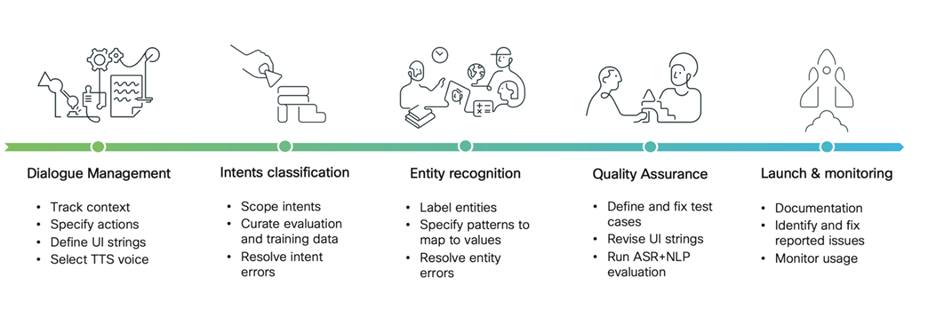
There are five broad phases to internationalizing the Webex Assistant, which are outlined in the diagram above, each of which brings their own unique challenges.
1. Dialogue Management
The first step is to define the dialogue management components. Voice is the main mode users have for interacting with the assistant. Thus, it is crucial to accurately define the flow of conversational interactions. Conversations tend to be much more intuitive and simpler for users than point-and-click graphical interfaces, but it creates challenges for the developer that don’t necessarily arise for other types of internationalization projects. Language use in context is strongly tied to the cultures, societal norms, and practices that they are a part of, and introducing a conversational component to a user interface brings with it many sociolinguistic and sociopolitical considerations that static internationalized content generally relies on much less.
The Webex Assistant in English maintains a relatively casual relationship with its users. It is friendly but not too colloquial, and it maintains a positive and upbeat tone. Designing conversations with the assistant in English uses fairly straightforward language, and English does not generally have to use special verb or noun forms when talking one-on-one with someone. There are no required markers of formality, and no need to refer to a person with gendered language. But in other languages, grammatical gender agreement is necessary, changing the form of a word according to the noun it refers to. In French and Italian, for example, the grammar can constrain the speaker into specifying the gender of the addressee whether it is relevant to the context or not:
French Italian
(1) Tu es occupé (3) Sei occupato
You (male) are busy You (male) are busy
(2) Tu es occupée (4) Sei occupata
You (female) are busy You (female) are busy
Using the wrong gender marker is the equivalent of being called “mister” for someone who identifies as a woman. It does not respect the grammatical rules of the language and can feel awkward, to say the least.
Similarly, many languages have grammatical markers of formality, indicating how well the speaker and the listener know each other. You might use the familiar form of address with family members and friends, but with colleagues, you would switch to a more formal style. Conversations in English generally have optional and more subtle style choices, while in another language, not being attuned to who your conversations are directed toward could lead to poor user experiences, with the possibility of your users feeling as though they were talked down to, or not respected by your product. Since we can’t know the gender of the user, or the level of formality that they assume when talking to a voice assistant, much of the dialogue management phase requires working with native-speaker linguists who are sensitive to these facts, and who can help craft dialogues that are accessible to anyone who wants to use the product.
2. Intent Classification
The second step in the internationalization process is intent classification. The MindMeld platform powering the Webex Assistant uses a supervised machine learning model to learn from thousands of training examples. But crucially, those thousands of training examples must first be carefully selected and classified into distinct categories. These examples have to be representative of the language usage of its users as a whole. Training examples are sorted into Domains, which serve as a first pass to identify the relevant topic of a user’s utterance, and then into English-centric Intents, which further subcategorize what action the user is asking for.
When building our training data, we need to anticipate how our users will address the assistant and adapt our data accordingly. We want examples that are representative of the way people will actually speak to the assistant, so that the model can learn to predict the kinds of patterns that are typical in the language. For example, there are a few different ways that English can express a simple command to turn on the device’s audio:
Variations in English syntax and word forms:

In English, we find we can produce 4 sentences with 6 different word forms. But English has relatively little inflectional morphology, meaning that word forms may vary depending on things like plurality (cat vs cats), on subject agreement (I walk vs she walks), and on verb tense or aspect (It breaks, it is breaking, it broke, it has broken). English also has a fairly consistent word order, which makes coming up with training examples that are representative of how real users might speak into a fairly straightforward task. But for German, which has much richer inflectional morphology and a freer word order than English, the same simple sentence can be expressed in 24 different ways, with 17 possible distinct word forms, and varying word order:

Each of these ways of expressing this simple command is representative of what an actual user might say. To capture all of this variation in German means collecting many more training examples and being especially attuned to these linguistic differences.
3. Entity Recognition
Once utterances have been categorized into semantic classes, we start the process of entity recognition to find and label key information in the training data. For the Webex Assistant, we want to tag entities like person names and their titles, “Call Puja, the product manager,” times and dates, “Schedule a meeting from 2pm to 4pm” or even help categories, “Can you help me with device controls?” so that we can ingest this information and map this text to an action that the assistant can take. In languages like English, Spanish, and French, the indicators of an entity’s role in the command are mostly at the beginning of the entity. This means that for most command types, the entity recognition algorithm can efficiently assign words to entities in a greedy left-to-right process. But in other languages, like Japanese, much of the information that signals the entity’s role appears at the end of the entity. For example, in the example below, which translates as “Reserve a meeting in 30 minutes,” the clearest indicator that the meeting starts in 30 minutes rather than ends in 30 minutes (から) comes after a greedy algorithm would decide what “30” is.
| 30分 | 後 | から | 会議 | お | 予約 |
| 30 minutes | after | from | meeting | [object] | reserve |
| start_time | |||||
| Reserve a meeting in 30 minutes | |||||
Similarly, in the next example, which means about the same as “Make contact with Director Motohashi,” the clearest signal that the first character of the person name (本) is part of a person name, and not part of a job title as in “director,” is the following words (さんに). The architecture of the entity recognizers must support both directions of information packaging equally well.
| 本部長 | の | 本橋 | さん | に | 連絡 | する |
| Director | of | Motohashi | Mx. | to | contact | do |
| job_title | person_name | |||||
| Make contact with Director Motohashi | ||||||
4. Quality Assurance
The Quality Assurance step is where the initial decisions about the language development are tested and refined. At this point, models have been built, and there is a minimally working app. This stage of the process allows us to test the conversation flows end-to-end, to monitor domain and intent classification as well as entity recognition. We also build audio data sets and perform checks on how well speech recognition transcripts integrate into the process. This is also where linguistic decisions made in previous stages of the process can be tested and refined.
5. Launch and Monitoring
Once the Webex Assistant is launched in a new language, the internationalization process is not over. After external users interact with the Webex Assistant, we can gather data about successful and unsuccessful interaction patterns, and find and fix bugs that did not surface during the Quality Assurance phase of the process. Regular analysis of logs data can alert us to areas where the assistant might be underperforming, which then are subject to further scrutiny.
Takeaways
Internationalization of a voice-driven application requires a much broader scope than internationalization of static text. But being aware of these linguistic differences throughout the development process is crucial for streamlined project implementation and thoughtful product design. Designing an application with an international and multilingual audience in mind allows your platform and your process to have the necessary flexibility that might otherwise be overlooked. Having the right resources and people who are attuned to these linguistic subtleties is also a crucial part of a successful internationalization process.
Acknowledgement
We gratefully recognize the insights of all our contractor analysts from Telus International, who have greatly helped us in developing our understanding of the issues described here: Lindsey Fiedler, Daniel Galarreta-Piquette, Jutta Romberg, Andreas Haida, Hiroshi Sasaki, and Masa Ide.
About The Author




