
Welcome to a world where innovation knows no bounds, and the limits of large artificial intelligence (AI) models are pushed beyond imagination. In this world, anyone with a novel idea poses a serious threat to upend your industry, and the list of your adversaries only grows with time. It’s crucial that you stay ahead of this curve with novel and innovative solutions of your own, and at a cheaper cost than your adversaries.
Picture yourself at the forefront of this quest for excellence, where your dedication and expertise fuel the creation of an automatic speech recognition (ASR) model that defies expectations, unleashing a level of quality and performance that leaves your adversaries in awe. As your model takes center stage in production, users are swept away by the transformative value it brings to their online meetings.
Within a matter of months, your ASR model becomes a phenomenon, captivating users far and wide, igniting an unprecedented demand that surges like wildfire. The challenge now lies in meeting this surge with consistent quality while ensuring that costs remain firmly under control. While ASR models are impressive, they are not tiny, and there are unique challenges with serving larger AI models which lesser models need not heed.
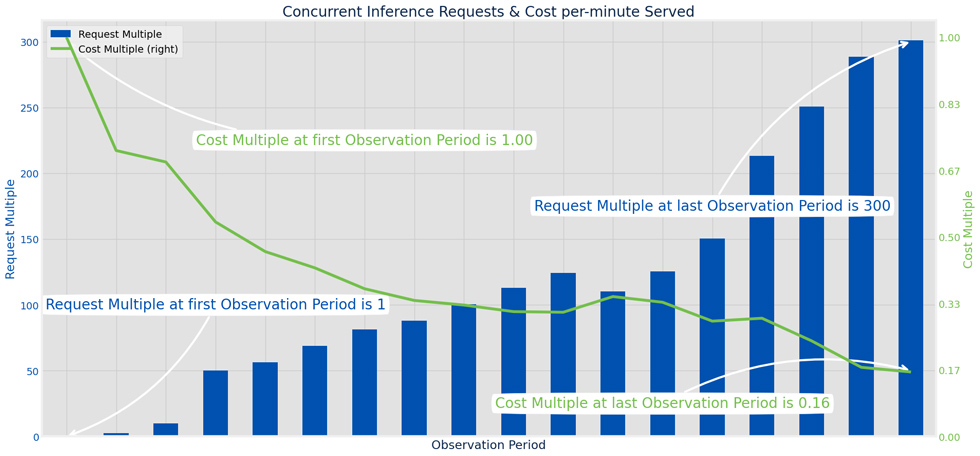
The above scenario you just pictured is what our team experienced in the last 18 months. Allow us to share the captivating journey our team experienced with our ASR model, where cutting-edge technology, resource optimization, and visionary thinking converge to create a magnificent tapestry of success. You’ll learn how our team rose to the occasion in hosting our large AI model, seamlessly handling the 300x surge in demand while reducing the cost-to-serve by 84%!
In this thrilling tale, you’ll meet an extraordinary cast of characters who join forces to overcome key hurdles in order to reach such impressive cost savings:
- Slotty: the master of resource optimization and scalability
- Capacity Manager: the brilliant strategist balancing cost savings with performance
- Trainable and Manuscript: the data experts fueling model training
- Evaluation Pipeline: the rigorous proctor of model performance
- K2: the audacious challenger revolutionizing audio processing
- Sherpa: the intrepid guide through real-time inference
Real-time Inference at Scale
In the realm of AI research, the trail from theory to practical application is full of obstacles to be conquered. The initial hurdle of proving our model offered measurable value to solve real-world problems was relatively easy, but this only presented more daunting challenges to overcome: How can we take our model beyond the boundaries of a controlled lab environment and unleash its power to serve real-time traffic at scale?
It is tempting to pull the most popular off-the-shelf tools that promise a Serverless interface for hosting models. Our experience discovered that none of these tools were optimized for hosting models of our size, at the volume we encountered, while also minimizing costs. We needed more than just a pre-packaged solution to serve our models. The challenges looming over us required a sophisticated understanding of the underlying complexities through the entire inference stack, and the ability to unravel the intricacies of hosting large models that scale into the millions of inference calls per day.
In our research, the primary drivers of cost and inference delay, or latency, is the sheer size of the models themselves and compute resources required to run inference on them. For language models, like our ASR, they often measure in gigabytes, and it is this large vector space that plays a vital role in delivering accurate and high-quality results. As the field advances and other large language models (LLM) continue to grow in size, their impact on cost and latency becomes increasingly pronounced; no matter how much you can prune or quantize them.
A naive solution to this is to simply pre-allocate a swarm of On-Demand servers to host our model, but at our scale this would get prohibitively expensive. Most cloud providers will offer discounts for long-term commitments and reservations which help ease the heavy burden of hosting compute intensive workloads. However, such commitments do not align with the demand curve of our AI workloads. Our demand adjusts dramatically with the working hours of each day, and end-user preferences are notoriously difficult to accurately forecast months in advance.
Cloud providers also offer Spot Instances which present an intriguing opportunity for substantial cost savings, with discounts up to 90%, where the compute resources are only started after a request is initiated. Spot Instances are amazing for asynchronous workloads, but horrible for stateful workloads like audio streaming and speech transcription. The unique challenges posed by our large models and latency requirements demand a more tailored approach.
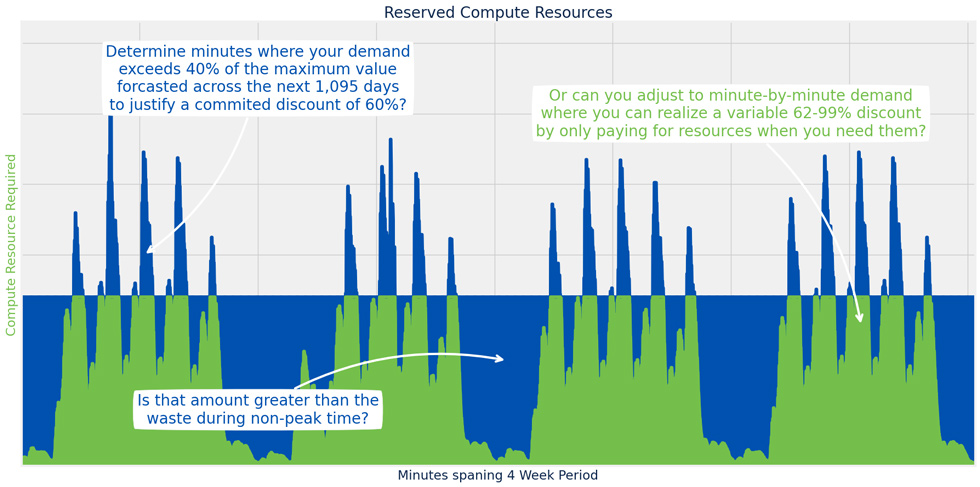
To meet the demanding low-latency requirements of our ASR model, the ability to predict and dynamically scale each component became crucial. As the popularity of AI applications soars, the need for low-latency inference and dynamic resource provisioning becomes increasingly vital. It is in the face of this challenge that our hero, Slotty, emerges.
Intelligent Resource Scaling
Armed with unparalleled expertise in resource optimization and orchestration, Slotyy is the embodiment of ingenuity and adaptability. As the demand for our AI model grew exponentially, Slotty was the first character to join our party to help seamlessly navigate the complex landscape of compute resources and scaling capabilities Slotty is a homegrown Kubernetes Controller, which seamlessly interacts with the containerized environment, providing a robust foundation for managing stateful AI inference workloads like our ASR model.
Within the Slotty framework, multiple models are orchestrated and hosted on dedicated AI Servers, called Slot Groups, ensuring efficient processing of requests with sub-millisecond latency through a standardized gRPC interface.
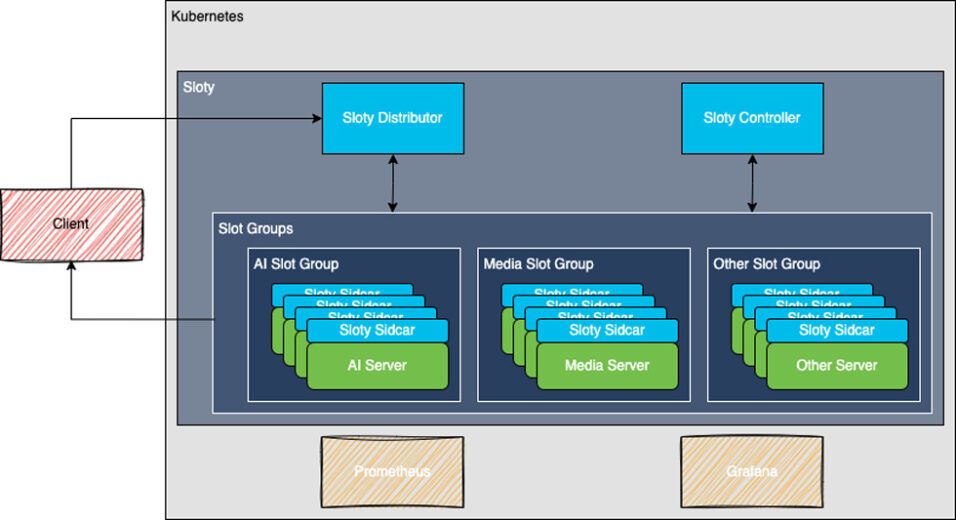
Slotty empowers our developers to harness resources with unmatched precision while also adding fault tolerance to the AI workload. By deftly separating the concerns of each step in the AI workload into individual Slot Groups, we can automatically scale each of the components based on their specific resource requirements and request volume in real-time. The reality is that some services handle parallelism and concurrent requests better than others. The mighty AI Server is a voracious consumer of compute resources, which stands apart from the likes of the Custom Dictionary, Highlights, Translation, and Keyword triggers, which do not demand the same level of computational might. Through this strategic resource allocation and bin-packing of requests on a per component level, Slotty has enabled us to achieve unparalleled efficiency, unlocking the true potential of our AI workloads.
Accompanying our hero Slotty, is a steadfast companion known as the Capacity Manager, endowed with the wisdom of a prophet. With unwavering vigilance, the Capacity Manager continually monitors the availability of capacity, quota, price, and other custom metrics from Slotty across each Data Centers, to intelligently shape the traffic of incoming requests offering prophetic insights into the anticipated demand in the forthcoming minutes. This matchmaking happens for each inference call in sub-millisecond speed across the entire planet. It’s also possible to retain the state of each inference call, to ensure it’s routed to the same inference server for a set period of time when required.
These visions for the next few minutes of forthcoming demand are shared with Slotty to execute on the scale for each component dynamically, ensuring an optimal balance of workload distribution and resource utilization. Slotty will spawn the creation of new compute resources only a few minutes before they are needed and scale them down during idle periods. This ensures the resource hungry workloads, like our AI Server, are never late, nor are they early. The AI Server arrives precisely when they are needed, optimizing resource utilization, eliminating unnecessary delays in repeated resource provisioning, and minimizing the costs from significant compute resources.
Understanding the fallibility of even the most experienced prophets, Slotty takes a cautious approach, favoring the availability of resources over risking an embarrassing shortfall. It gracefully handles the inevitable errors in capacity predictions, swiftly scaling up when it reaches a predetermined buffer threshold to detect low capacity. Moreover, Slotty continually monitors each inference call to identify idle or underutilized resources, re-allocating inference calls to optimize bin-packing across resources before gracefully terminating unused resources for each Slot Group.
In this sense, we get the reliability of hosting our AI workloads with On-Demand resources but at the prices closer to that of Spot Instances. Slotty has helped us to achieve an average realized savings of 75% in compute resources when compared to traditional capacity planning. This agile approach allows us to adapt to fluctuating demand and optimize resource allocation based on real-time needs.
Robust Model Lifecycle Management
Infrastructure optimizations only took us so far. As shown in the first figure in the blog, our cost optimization journey was a gradual one. The last significant item we had to vanquish was the fundamentals of the model itself, which leads us back to machine learning research.
To aid the researchers, we crafted the helpful trio of Trainable, Manuscript, and Evaluation Pipeline. These sister services are designed to close the feedback loop, from models running in production, to new challenger models in development. Making it simple to rapidly iterate on new hypotheses and model architectures, without having to worry about affecting end-user experience or model performance.
The feedback loop begins with our current model in production, talking to Trainable. With a strong emphasis on end-user security and privacy, Trainable allows end-users from a variety of applications to seamlessly volunteer anonymized short audio chunks. The next link in the loop is Manuscript, which is optimized to prioritize and distribute these audio chunks to an esteemed network of professional data annotators under non-disclosure agreements to label them. Once cross validated, these audio chunks are incorporated into our treasure hoard of golden data.
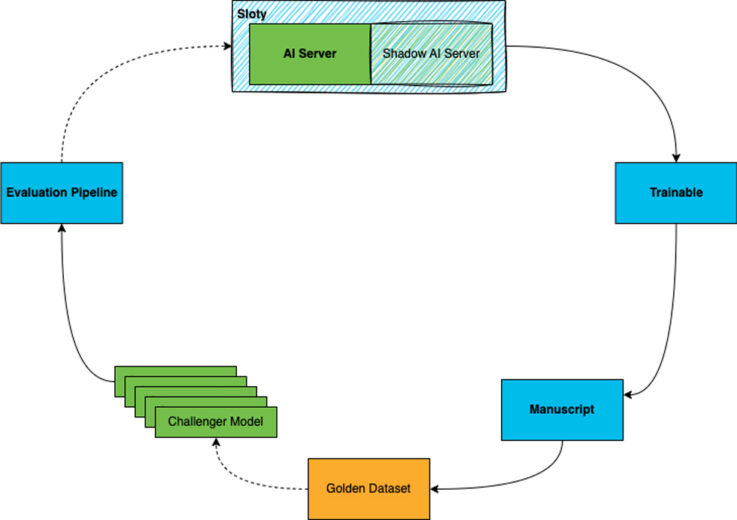
Before any model can be released into the wild, it must undergo rigorous assessment in our Evaluation Pipeline. But the battle is not finished there, each challenger must remain vigilant to defend their performance and vanquish the reigning champions from each of our adversaries to become victorious. You could view this as an arms race to build the ultimate champion. It is under this light that our pipeline supplies meticulous visibility into the model’s performance across a vast range of metrics. Think of it as an unforgiving gauntlet through which challenger models must not only pass, but prove it has measurable gains over its predecessors and adversaries.
There are many challengers which approach the Evaluation Pipeline, but only a few will reach production. Some excelled in accuracy metrics but couldn’t keep up with the demanding scale required of them. Others would scale efficiently but couldn’t move the needle when it came to reducing compute resources and costs. Then one day, a different class of challenger model arrived to prove it was worthy.
Emergence of new challenger K2
Compared to its predecessors, K2 is simpler, more accurate, and more efficient, allowing it to learn directly from the audio signal. This approach was also extendable to act as a backbone for other audio-related models in a single pass, such as Punctuation, Capitalization, Multiple Language, Language Detection, Translation, Audio Style Transfer, Audio Super Resolution, Audio Embeddings, and more.
K2 was perfected to integrate deeply with Slotty for real-time inference through a service called Sherpa. Sherpa is the enhanced buffer which supports dynamic micro-batching to parallelize inference across enhanced worker threads in an asynchronous loop across a horde of AI Servers controlled by Slotty. It also used a pioneering data structure called RaggedTensor, which was optimized for spare data and efficiently performs the beam search during decoding on GPUs. K2, along with Slotty and Sherpa, blew past all expectations.
Not only did K2 exceed all predecessors performance metrics, and rapidly vanquish the best champions from our advisories, with the aid of Slotty and Sherpa, it could also perform the speech to text transcriptions at a 6:1 ratio! That is to say, this challenger could slay six times more requests than its predecessors with the same compute resources when orchestrated through Slotty and Sherpa! This realized cost savings of around 83%. Behold! A new champion has emerged!
With our model’s newfound abilities, it has become a versatile polyglot, capable of dynamically adjusting its optimizations based on the available compute resources in each environment. Whether we have powerful GPUs or limited CPU resources, it collaborates with Slotty to dynamically adapt the AI workload strategies accordingly, at a fraction of its predecessor’s cost.
This level of interoperability allows our infrastructure stack to be highly flexible, enabling smooth migration across different cloud providers while keeping a standardized core AI workload for external clients to connect through a standardized gRPC interface.
Conclusion
In the world of AI-driven innovation, the pursuit of excellence requires a team that has unwavering dedication, visionary thinking, and a relentless commitment to pushing the boundaries of what is possible. The journey we just shared showcases the extraordinary achievements made possible by our exceptional team. I am truly privileged to stand among their ranks.
Alas, our journey does not end here. In addition to the quantization mentioned earlier, we’re also elbow deep exploring the ingredients and alchemy needed to effectively combine multiple large models, LLM and ASR, to improve the performance of each.
Come join us on this new adventure and uncover the untold trails that lie ahead, we invite you to leave a comment on this blog. Engage with our team of experts and fellow enthusiasts to explore the uncharted territories of large-scale AI innovation together.



