
In this post, we’re going to explore how chaos engineering helped us to ensure the resiliency of the Cisco Webex Contact Center (Webex CC) platform, share some of the tools and issues we’ve learned along the implementation journey, and why we believe our product has industry-leading resiliency.
Webex CC is a Contact Center as a Service (CCaaS) offering, that enables smart, proactive, and personalized interactions across the customer journey.
Webex CC is architected, designed, and developed, from the ground up, as a cloud-native solution, with the following core architectural principles.
- Services: A set of independent services, each of which supply a small cohesive set of capabilities to its users.
- Event Driven: All the services communicate to each other using messaging, except in web applications where the application uses https interfaces (REST APIs and Push Data via WebSocket interface) for specific use cases.
- Stateless/Externalized State: The services are deployed in Kubernetes, running in docker containers, with the ability to automatically scale and be resilient to failures of one or more instances of the services.
- Observable: All the services, and the infrastructure components that enables the deployment of such services, are observable with standard mechanisms to measure, detect and prevent situations affecting contact center capabilities as well as quickly troubleshoot and restore services in case of outages.
- Isolated/Loosely Coupled: Every service can be built, confirmed, and deployed/updated independently with no downtime for contact center capabilities.
At Webex CC, we understand that the reliability and availability of our platform are critical to our customer’s success. That’s why we’ve invested in designing and implementing robust systems and processes that enable us to detect and mitigate potential failures before they impact our users.
Architecture Considerations for Platform Resiliency
The Webex CC platform employs infrastructure-as-code and modern GitOps practices, where Git repositories serve as the authoritative source for delivering infrastructure-as-code methodologies. It incorporates high availability through the utilization of state-of-the-art technologies such as Kubernetes, Kafka Messaging, Istio Service mesh, and secrets management, in conjunction with Amazon Web Services (AWS) managed services including Relational Database Service (RDS)and OpenSearch.
This has been achieved through the utilization of clustered services that are spread across multiple Availability Zones (AZs) as illustrated in the accompanying figure.
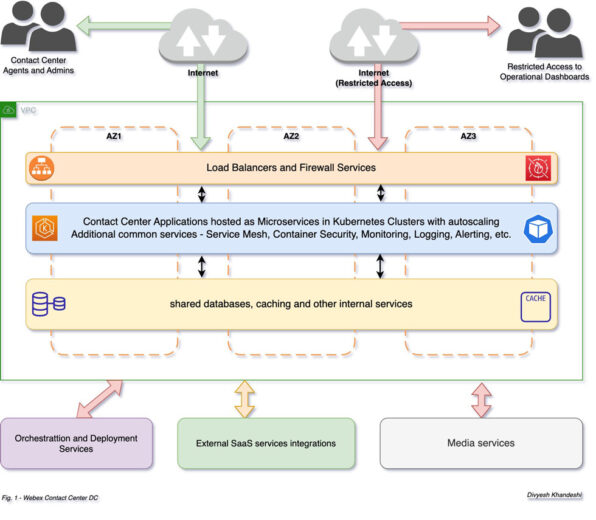
- Webex CC infrastructure services are clustered and spread across multiple AZs to achieve
high availability. - Cross-zone load balancing is utilized for cross-zone load balancing, ensuring service availability even in the event of an AZ outage.
- Usage of service mesh for improved security and resiliency.
- Automated monitoring and alerting for detection and notification of any issues at various levels from node layers to microservices.
- Auto-scaled node pools to automatically adjust the number of nodes based on workload.
One of the key practices we’ve adopted to achieve this level of resiliency is chaos engineering. Chaos engineering is a methodology that helps us identify and address potential weaknesses in our systems by intentionally introducing failures in a controlled and safe manner.
Chaos Test Methodology
Chaos testing (also known as chaos engineering) is a method of testing software systems and infrastructure by intentionally introducing failures or disruptions to see how the system responds.
The service disruption scenarios are designed based on system analysis and learnings from previous incidents where Webex CC applications interact with external or platform services that it depends on.
The service disruptions scenarios include:
- Relational Database Service (RDS) Primary Database Failover
- S3 Access Failures
- Zookeeper Failure
- Outbound Access Failure
- Message Brokers Failure
- In-Memory Cache Failures
- Voice Point of Presence (vPOP) Gateway Failover
- Elastic Search Out of Memory (OOM) Error Crash
- Webex Contact Center Media Streaming Stack Failures
- Logging Failure with FluentD and Kibana down
- Availability Zone Failure
- Network Faults
- Loss of Metrics
- Load Balancer Failure
These test scenarios are based on the high-level system view which is depicted in the diagram below.
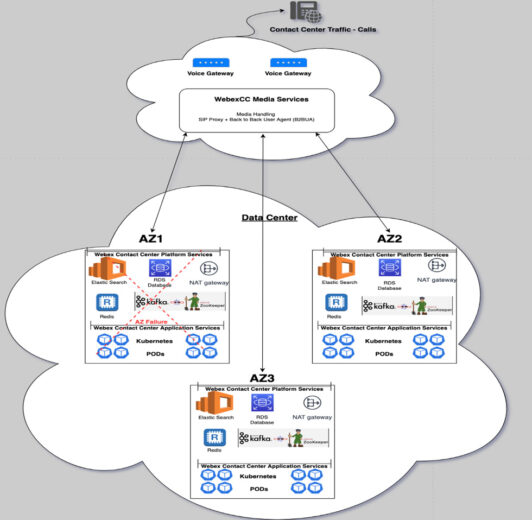
During periodic meetings with the AWS Technical Account team, the Webex CC engineering teams were provided suggestions on how to conduct chaos testing.
As part of these discussions, AWS suggested leveraging their AWS Fault Injection Simulator (FIS) for certain tests, while recommending that other tests (which required removing routes from Security Groups and S3 Access Denials) be done manually. Furthermore, for injecting failures at the Kubernetes Pod level, an open-source tool called Chaos Mesh was also recommended.
To achieve better control over manual service disruptions during the Webex CC chaos tests, various methods were utilized, including:
- Implementing security group-level access denial to application subnets,
- Creating custom scripts to simulate OOM crashes and segmentation faults
- Performing rolling restarts of Kubernetes PODs
- Denying access for specific applications to S3 buckets
- Restarting gateways and EC2 instances
These methods were employed to create disruptions intentionally and manually for the scenarios mentioned earlier, thus avoiding the need for multiple tools to perform the tests comprehensively.
Observations
Chaos tests identified call failures, agent login failures, and reporting failures that have since been addressed to improve the resiliency of Webex CC.
Some highlights include:
- Network Disruptions impacted agent logins due to long reconnect times with the in-memory data stores. The performance was improved through timely re-initialization where network faults are detected.
- Apache Zookeeper faults impacted Webex CC Reporting services. Apache Flink, used to handle tasks such as managing commit offsets and rebalancing, failed to recover when the tests introduced a fault with Apache Zookeeper. Quick Apache Flink recovery strategies were deployed to ensure the reporting SLAs.
- The switchover of the writer and reader roles in AWS Relational Database (Aurora) resulted in the Contact Center administrator being unable to perform configuration tasks for at least 30 minutes. This issue was resolved by switching from MySQL JDBC (Java Database Connectivity) driver to AWS JDBC driver version that supports fast failover.
- The Kafka brokers are only operational in one of Availability Zone, while the brokers in other Availability Zones were down. This resulted in call failures, and upon analysis, it was determined that the stream thread was down due to the transient unavailability of a Kafka broker in one of the Availability Zones.
To address this issue, Webex CC had to implement a retry mechanism for the stream thread, which has been available in the Kafka library since version 2.8.0. - Kafka rebalancing issues resulted in call failures across several components when Webex CC Kubernetes PODs were scaled up dynamically during live traffic. Software changes were implemented across various components to address this.
We are currently in the process of expanding our Webex CC chaos test coverage. We are also exploring the potential for automating these tests, including post-recovery actions, as part of our regression tests. This will allow us to execute chaos tests automatically when needed, eliminating the need for manual execution after the initial setup, similar to our automated and load tests.
Conclusion
Webex CC Engineering teams have seen how chaos engineering can be a powerful tool for improving system resilience by proactively identifying and addressing potential failure scenarios. As with any new testing methodology, it can be challenging to know where to start. Therefore, our team recommends starting small and gradually increasing complexity to avoid being overwhelmed by the process. This approach will help to identify any weaknesses in the testing methodology and allow for iterative improvements.
Furthermore, it’s crucial to keep in mind that the primary objective of chaos engineering is not to deliberately induce chaos without purpose. Rather, it is to utilize the insights gained from testing to enhance resilience, and concurrently improve monitoring and alerting systems for more efficient issue detection and response.
Implementing chaos engineering can be a valuable way to improve your system’s resilience. Start small, iterate, and use the insights gained. By doing so, you will be better equipped to handle any unexpected events that may arise in the future.
Acknowledgment
We would like to extend our heartfelt thanks and appreciation to Anuj Butail, Nikola Bravo, and Neelesh Adam from AWS who worked closely with us to understand our testing objectives and provided us with a clear roadmap for executing chaos testing.
Additional Reading:
About The Authors





