
Introducción
Los sistemas de reconocimiento automático del habla (ASR, por sus siglas en inglés) proporcionan transcripciones de texto. Normalmente, se trata de una secuencia de palabras. Cisco utiliza sistemas ASR para proporcionar subtítulos en tiempo real en las reuniones de Webex. Uno de los problemas que surgen es que puede resultar difícil leer los subtítulos sin puntuación ni mayúsculas. La capacidad de entender el significado del texto puede cambiar en función de la puntuación. Imagine la siguiente secuencia de palabras con dos opciones de puntuación:“gracias su donación acaba de ayudar a alguien a conseguir un trabajo”.
Opción A: “¡Gracias! Su donación acaba de ayudar a alguien a conseguir un trabajo”.
Opción B: “¡Gracias! Su donación acaba de ayudar a alguien. ¡A conseguir trabajo!”.
Los signos de puntuación marcan una gran diferencia.
Repasaremos varias consideraciones a la hora de desarrollar un sistema de posprocesamiento:- Modelos de alta precisión para la restauración de los signos de puntuación y el uso de mayúsculas a partir del texto sin formato. Inferencia rápida sobre los resultados provisionales: para seguir el ritmo de los subtítulos en tiempo real.
- Utilización de pocos recursos: el reconocimiento del habla es intensivo desde el punto de vista computacional; no necesitamos que nuestros modelos de puntuación también lo sean.
- Capacidad para procesar palabras no incluidas en el vocabulario: a veces, necesitaremos asignar puntuación o poner en mayúsculas palabras que nuestro modelo no ha visto antes.
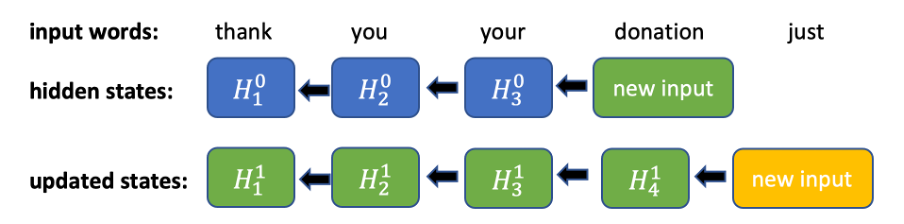
Figura 1. Cálculos en el paso hacia atrás de una RNN bidireccional. Para cada nueva entrada, todos los estados ocultos anteriores deben actualizarse secuencialmente
TruncBiRNN
La intuición y los experimentos demuestran que es imprescindible contar con el contexto futuro al desarrollar un modelo de puntuación, ya que es más difícil determinar los signos de puntuación en una posición actual sin conocer las siguientes palabras. Para utilizar la información sobre los próximos tokens y no tener que actualizar todos los estados ocultos para todos los tokens en la dirección hacia atrás, decidimos truncar la dirección hacia atrás en una ventana fija. En la dirección hacia delante, es solo una RNN normal. En la dirección hacia atrás, solo consideramos una ventana fija en cada token y ejecutamos la RNN sobre esta ventana (figura 2). Usando esta ventana, podemos lograr una inferencia en tiempo constante para un nuevo token de entrada (debemos calcular un estado oculto en la dirección hacia adelante y n+1 en la dirección hacia atrás).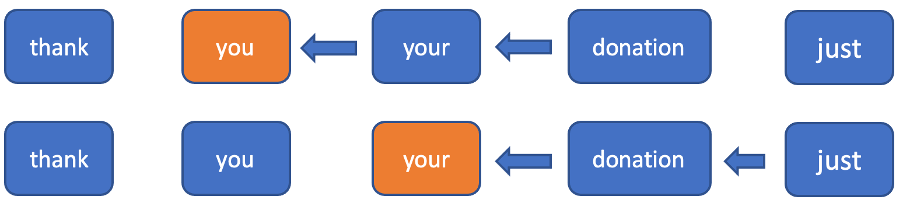
Figura 2. En este ejemplo, para cada token actual, solo se consideran las dos siguientes para calcular el estado oculto en la dirección hacia atrás.
Arquitectura
La arquitectura consta de una capa de incrustación, una capa TruncBiGRU y una capa de GRU unidireccional, y un nivel totalmente conectado. Para la salida, utilizamos dos capas softmax para la puntuación y el uso de mayúsculas, respectivamente (figura 3).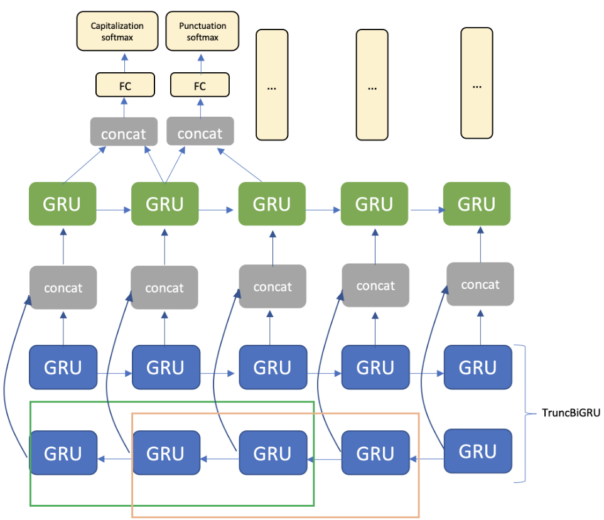
Figura 3. Arquitectura del modelo con tamaño de ventana igual a dos tokens para TruncBiGRU.
punto: un punto en medio de una oración que no implica necesariamente que la siguiente palabra deba ir en mayúscula (“a. m”., “D.C.”, etc.)
coma
signo de interrogación
puntos suspensivos
dos puntos
guion
punto final: un punto al final de una oración
Para el uso de mayúsculas, tenemos cuatro clases:minúsculas
mayúsculas: todas las letras se escriben en mayúsculas (“IEEE”, “NASA”, etc.)
mayúsculas
mix_case: para palabras como “iPhone”
mayúscula inicial: palabras que comienzan una oración
Las clases adicionales, “mayúscula inicial” y “punto final”, pueden parecer redundantes a primera vista, pero ayudan a aumentar la coherencia de las respuestas relacionadas con el uso de mayúsculas y la puntuación. El “punto final” implica que la siguiente respuesta de asignación de mayúsculas no puede ser “minúscula”, mientras que “mayúscula inicial” significa que el signo de puntuación anterior es un “punto final” o un signo de interrogación. Estas clases desempeñan un papel importante en la función de pérdida. Función de pérdida: Tenemos que optimizar tanto el uso de mayúsculas como la puntuación. Para lograrlo, utilizamos una función de pérdida de suma de logaritmos con un coeficiente: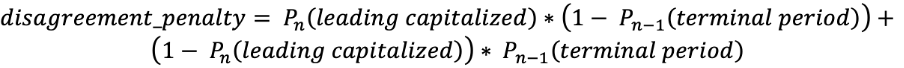 El primer término corresponde a la probabilidad de tener “mayúscula inicial” después de un elemento que no es un “punto final”, y el segundo a la probabilidad de no tener “mayúscula inicial” después de un “punto final” Esta penalización se suma sobre los tokens en los que se produce este error. Además, pasamos dos tensores consecutivos de la capa anterior a las capas softmax. Con esto, podemos reducir eficientemente los términos de penalización. Por último, tenemos la función de pérdida:
El primer término corresponde a la probabilidad de tener “mayúscula inicial” después de un elemento que no es un “punto final”, y el segundo a la probabilidad de no tener “mayúscula inicial” después de un “punto final” Esta penalización se suma sobre los tokens en los que se produce este error. Además, pasamos dos tensores consecutivos de la capa anterior a las capas softmax. Con esto, podemos reducir eficientemente los términos de penalización. Por último, tenemos la función de pérdida: 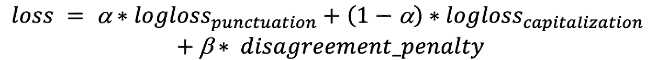
Entrenamiento
Para el entrenamiento, utilizamos transcripciones de texto de un conjunto de reuniones internas de Webex y datos de texto de Wikipedia. En primer lugar, los datos de entrenamiento se limpian y se dividen en oraciones. Durante el entrenamiento, cada muestra se genera a partir de oraciones consecutivas y se trunca con una longitud aleatoria a partir de una distribución fija. Esto permite que el modelo vea las frases recortadas durante el entrenamiento, lo que permite al modelo lidiar con los resultados intermedios durante la inferencia. A continuación, entrenamos el modelo con unos 300 megabytes de texto de Wikipedia y luego lo ajustamos con las transcripciones de las reuniones de Webex. El entrenamiento previo en Wikipedia ayuda a mejorar todas las clases de puntuación, pero es particularmente útil en las clases de uso de mayúsculas. Sospechamos que esto se debe al gran número de nombres propios del corpus de Wikipedia. Aplicamos la misma preparación de datos a nuestros conjuntos de evaluación concatenando oraciones y truncándolas a longitudes aleatorias. Esto nos permite medir la precisión para lo que probablemente veríamos en los estados intermedios de la transcripción.Conclusión
Utilizando técnicas relativamente sencillas con algunas personalizaciones de la arquitectura, como la GRU truncada y una penalización adicional en una función de pérdida, hemos desarrollado un modelo que puede ejecutarse en línea. La experiencia de lectura de los subtítulos en directo mejora notablemente con los signos de puntuación y el uso de mayúsculas en tiempo real. Referencias [1] A. Gravano, M. Jansche y M. Bacchiani, “Restoring punctuation and capitalization in transcribed speech,” en ICASSP 2009, 2009, pp. 4741–4744. [2] Monica Sunkara, Srikanth Ronanki, Kalpit Dixit, Sravan Bodapati, Katrin Kirchhoff, “Robust Prediction of Punctuation and Truecasing for Medical ASR” [3] Tilk, Ottokar y Alumäe, Tanel. (2016). Bidirectional Recurrent Neural Network with Attention Mechanism for Punctuation Restoration. 3047-3051. 10.21437/Interspeech.2016-1517. [4] Vardaan Pahuja, Anirban Laha, Shachar Mirkin, Vikas Raykar, Lili Kotlerman, Guy Lev “Joint Learning of Correlated Sequence Labelling Tasks Using Bidirectional Recurrent Neural Networks” [5] Wang, Peilu & Qian, Yao y Soong, Frank y He, Lei y Zhao, Hai. (2015). Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Recurrent Neural Network. [6] Lita, Lucian y Ittycheriah, Abe y Roukos, Salim y Kambhatla, Nanda. (2003). tRuEcasIng. 10.3115/1075096.1075116. [7] https://github.com/google/sentencepiece Regístrese en Webex Visite nuestra página de inicio o póngase en contacto con nosotros directamente para obtener ayuda. Haga clic aquí para obtener más información sobre las ofertas de Webex y para inscribirse en una cuenta gratuita.About The Author


