
Introduction
Automatic Speech Recognition (ASR) systems provide text transcriptions. Usually, it’s a sequence of words. Cisco uses ASR systems to provide real-time closed captioning in Webex meetings. One problem that arises is that it may be difficult to read captions without punctuation and capitalization. The ability to understand the meaning of text can change based on punctuation. Imagine the following word sequence with two options for punctuation:“thank you your donation just helped someone get a job”.
Option A: “Thank you! Your donation just helped someone get a job.”
Option B: “Thank you! Your donation just helped someone. Get a job.”
One punctuation mark makes a big difference.
We’ll walk through several considerations when building a post-processing system:- High-accuracy models for punctuation restoration and capitalization from raw text. Fast inference on interim results: to keep up with real-time captions.
- Small resources utilization: speech recognition is computationally intensive; we don’t need our punctuation models to be computationally intensive as well.
- Ability to process out-of-vocabulary words: sometimes, we’ll need to punctuate or capitalize words that our model hasn’t seen before.
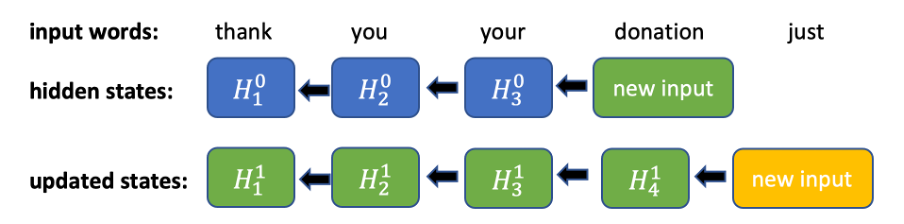
Figure 1. Computations on the backward pass of a bi-directional RNN. For every new input, all previous hidden states must be sequentially updated.
TruncBiRNN
Intuition and experiments show that it’s essential to have future context when building a punctuation model because it’s harder to determine punctuation marks in a current position without knowing the next several words. To use information about the next tokens and not be forced to update all hidden states for all tokens in the backward direction, we decided to truncate the backward direction to a fixed window. In the forward direction, it’s just a regular RNN. In the backwards direction, we only consider a fixed window at each token, running the RNN over this window (figure 2). Using this window, we can achieve constant time inference for a new input token (we’ll need to compute one hidden state in the forward direction and n+1 in the backward direction).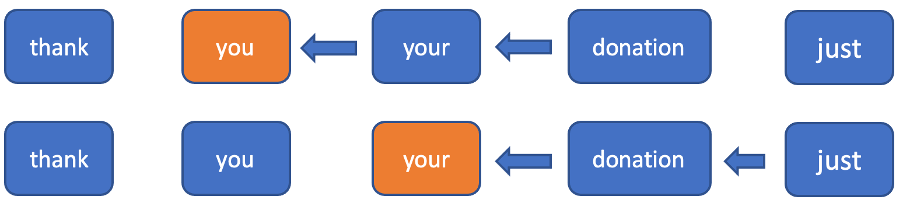
Figure 2. In this example, for each current token, only the next two are considered to compute the hidden state in the backward direction.
Architecture
The architecture consists of embedding layer, TruncBiGRU and unidirectional GRU layer, and fully connected layer. For the output, we use two softmax layers for punctuation and capitalization, respectively (figure 3).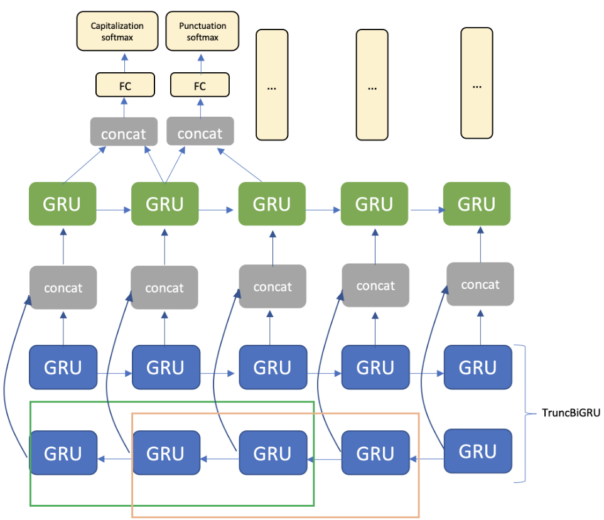
Figure 3. Model architecture with window size equal to two tokens for TruncBiGRU.
period – a period in the middle of a sentence that doesn’t necessarily imply that the next word should be capitalized (“a.m.,””D.C.,” etc)
comma
question mark
ellipsis
colons
dash
terminal period – a period at the end of a sentence
For capitalization, we have four classes:lower
upper – all letters are capitalized (“IEEE,” “NASA,” etc.)
capitalized
mix_case – for words like “iPhone”
leading capitalized – words that start a sentence
The additional classes, “leading capitalized” and “terminal period,” may seem redundant at first glance, but they help increase the consistency of answers related to capitalization and punctuation. The “terminal period” implies that the next capitalization answer can’t be “lower,” while “leading capitalized” means that the previous punctuation mark is a “terminal period” or question mark. These classes play an important role in the loss function. Loss Function: We need to optimize both capitalization and punctuation. To achieve this, we use a sum of log loss function with a coefficient: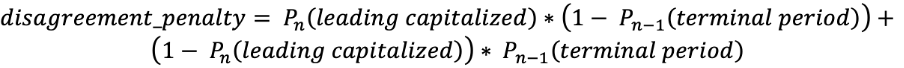 The first term corresponds to the probability of having “leading capitalized” after non “terminal period,” and the second to the probability of not having “leading capitalized” after “terminal period.” This penalty sums over tokens where this error occurs. Additionally, we pass two consecutive tensors from the previous layer to softmax layers. Given that, we can efficiently reduce penalty terms. Finally, we have the loss function:
The first term corresponds to the probability of having “leading capitalized” after non “terminal period,” and the second to the probability of not having “leading capitalized” after “terminal period.” This penalty sums over tokens where this error occurs. Additionally, we pass two consecutive tensors from the previous layer to softmax layers. Given that, we can efficiently reduce penalty terms. Finally, we have the loss function: 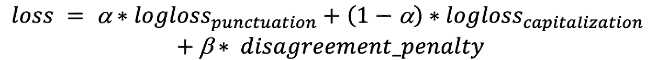
Training
For training, we use text transcripts from a set of internal Webex meetings and text data from Wikipedia. First, the training data is cleaned up and split into sentences. During training, each sample is generated from consecutive sentences and is truncated to a random length from a fixed distribution. This allows the model to see cropped phrases during training which allows the model to deal with interim results during inference. Next, we train a model on approximately 300 megabytes worth of Wikipedia text, then fine-tune it on Webex meeting transcripts. Pre-training on Wikipedia helps improve all punctuation classes but is especially useful on capitalization classes. We suspect this is due to the large number of proper nouns in the Wikipedia corpus. We apply the same data preparation on our evaluation sets by concatenating sentences and truncating them to random lengths. This allows us to measure the accuracy for what we would likely see in interim transcript states.Conclusion
Using relatively easy techniques with some customizations of the architecture, such as truncated GRU and an additional penalty in a loss function, we have built a model that can be run online. The reading experience of live captions is significantly improved with real-time punctuation marks and capitalization. References [1] A. Gravano, M. Jansche, and M. Bacchiani, “Restoring punctuation and capitalization in transcribed speech,” in ICASSP 2009, 2009, pp. 4741–4744. [2] Monica Sunkara, Srikanth Ronanki, Kalpit Dixit, Sravan Bodapati, Katrin Kirchhoff, “Robust Prediction of Punctuation and Truecasing for Medical ASR” [3] Tilk, Ottokar & Alumäe, Tanel. (2016). Bidirectional Recurrent Neural Network with Attention Mechanism for Punctuation Restoration. 3047-3051. 10.21437/Interspeech.2016-1517. [4] Vardaan Pahuja, Anirban Laha, Shachar Mirkin, Vikas Raykar, Lili Kotlerman, Guy Lev “Joint Learning of Correlated Sequence Labelling Tasks Using Bidirectional Recurrent Neural Networks” [5] Wang, Peilu & Qian, Yao & Soong, Frank & He, Lei & Zhao, Hai. (2015). Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Recurrent Neural Network. [6] Lita, Lucian & Ittycheriah, Abe & Roukos, Salim & Kambhatla, Nanda. (2003). tRuEcasIng. 10.3115/1075096.1075116. [7] https://github.com/google/sentencepiece Sign up for Webex Visit our home page or contact us directly for assistance. Click here to learn more about the offerings from Webex and to sign up for a free accountAbout The Author




