
Introduzione
I sistemi di riconoscimento vocale automatico forniscono trascrizioni di testo. Di solito, si tratta di una sequenza di parole. Cisco utilizza sistemi ASR per fornire sottotitoli codificati in tempo reale nelle riunioni Webex. Un problema tipico è che potrebbe essere difficile leggere i sottotitoli senza punteggiatura e maiuscole/minuscole. Il modo in cui si comprende il significato di un testo può cambiare in base alla punteggiatura. Immagina la seguente sequenza di parole con due opzioni per la punteggiatura:“grazie hai fatto una donazione a qualcuno e ora lavora”
Opzione A: “Grazie! Hai fatto una donazione a qualcuno e ora lavora.”
Opzione B: “Grazie! Hai fatto una donazione a qualcuno. E ora lavora!”
Un solo segno di punteggiatura fa una grande differenza.
Di seguito alcuni aspetti che vengono considerati durante lo sviluppo di un sistema di post-elaborazione:- Modelli di alta precisione per ripristino di punteggiatura e maiuscole/minuscole da testo non elaborato. Inferenza veloce su risultati temporanei: per mantenere l’allineamento a sottotitoli in tempo reale.
- Utilizzo risorse ridotto: il riconoscimento vocale consuma molte risorse informatiche; non abbiamo bisogno che anche i nostri modelli di punteggiatura consumino un numero elevato di risorse informatiche.
- Possibilità di elaborare termini non inclusi nel vocabolario: a volte, dobbiamo inserire punteggiatura o parole in maiuscolo/minuscolo che il nostro modello non ha mai visto prima.
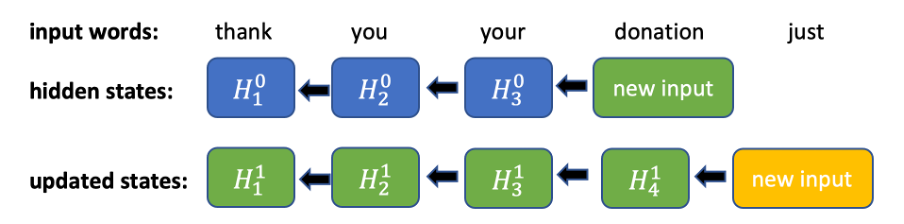
Figura 1. Calcoli sul passaggio indietro di una RNN bidirezionale. Per ogni nuovo input, tutti i precedenti stati nascosti devono essere aggiornati sequenzialmente.
TruncBiRNN
Intuizione e sperimentazioni dimostrano che è fondamentale disporre del contesto futuro quando si crea un modello di punteggiatura, perché è più difficile determinare i segni di punteggiatura in una posizione corrente senza conoscere le parole successive. Per utilizzare informazioni sui successivi token e non essere obbligati ad aggiornare tutti gli stati nascosti di tutti i token precedenti, abbiamo deciso di troncare la direzione indietro a una finestra fissa. In direzione avanti, è semplicemente una RNN regolare. In direzione indietro, consideriamo solo una finestra fissa in ciascun token, eseguendo l’RNN su questa finestra (figura 2). L’uso di questa finestra consente di ottenere inferenza a tempo costante per un nuovo token di input (sarà necessario calcolare un solo stato nascosto in direzione avanti e n+1 in direzione indietro).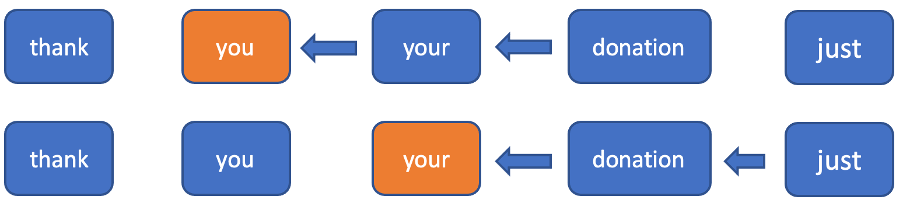
Figura 2. In questo esempio, per ogni token corrente, solo i successivi due vengono considerati per calcolare lo stato nascosto in direzione indietro.
Architettura
L’architettura consiste di strato di incorporamento, TruncBiGRU e strato GRU unidirezionale, e strato completamente connesso. Per l’output, utilizziamo due strati softmax per punteggiatura e maiuscole/minuscole, rispettivamente (figura 3).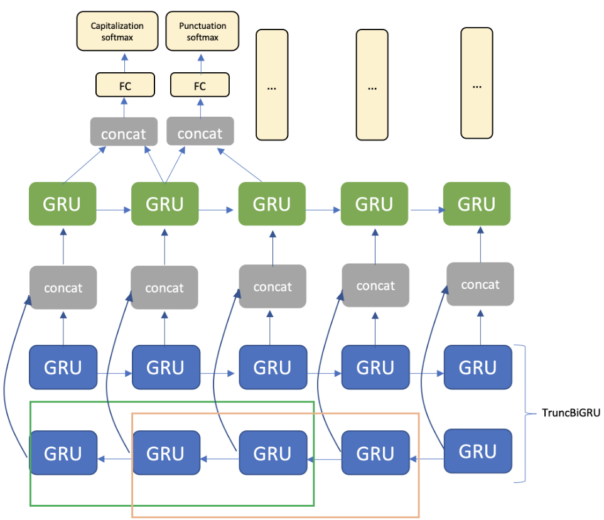
Figura 3. Architettura di modelli con dimensione finestra uguale a due token per TruncBiGRU.
punto: un punto al centro di una frase che non implica necessariamente che la parola seguente debba essere in maiuscolo (“a.m.”, “D.C.”, ecc.)
virgola
punto interrogativo
ellissi
due punti
trattino
punto di fine: un punto alla fine di una frase
Per maiuscole/minuscole, sono disponibili quattro classi:minuscolo
tutto maiuscolo: tutte le lettere vengono scritte in maiuscolo (“IEEE”, “NASA”, ecc.)
maiuscole
maiuscole_minuscole: per parole come “iPhone”
maiuscola iniziale: parole che iniziano una frase
Le classi aggiuntive, “maiuscola iniziale” e “punto di fine” possono sembrare ridondanti a prima vista, ma aiutano ad aumentare la coerenza di risposte correlate a maiuscole/minuscole e punteggiatura. Il “punto di fine” implica che la successiva risposta di maiuscole/minuscole non possa essere “minuscolo”, mentre “maiuscola iniziale” significa che il segno di punteggiatura precedente è un “punto di fine” o un punto interrogativo. Queste classi svolgono un ruolo importante nella funzione di perdita. Funzione di perdita: Dobbiamo ottimizzare entrambi, maiuscole/minuscole e punteggiatura. Per raggiungere questo obiettivo, utilizziamo una somma della funzione di perdita logloss con un coefficiente: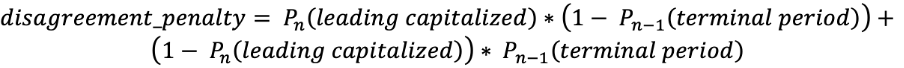 Il primo termine corrisponde alla probabilità di avere la “maiuscola iniziale” dopo un “punto non di fine” e il secondo corrisponde alla probabilità di non avere una “maiuscola iniziale” dopo il “punto di fine”. Questa penalità si somma nei token in cui si verifica questo errore. Inoltre, passiamo due tensori consecutivi dallo strato precedente agli strati softmax. Con questi presupposti, possiamo ridurre in modo efficiente i termini di penalità. Infine, abbiamo la funzione di perdita:
Il primo termine corrisponde alla probabilità di avere la “maiuscola iniziale” dopo un “punto non di fine” e il secondo corrisponde alla probabilità di non avere una “maiuscola iniziale” dopo il “punto di fine”. Questa penalità si somma nei token in cui si verifica questo errore. Inoltre, passiamo due tensori consecutivi dallo strato precedente agli strati softmax. Con questi presupposti, possiamo ridurre in modo efficiente i termini di penalità. Infine, abbiamo la funzione di perdita: 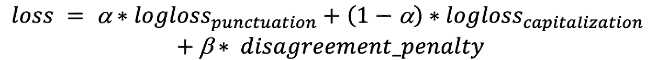
Training
Per l’addestramento, utilizziamo trascrizioni di testo di un set di riunioni Webex interne e dati di testo di Wikipedia. In primo luogo, i dati di addestramento vengono puliti e suddivisi in frasi. Durante l’addestramento, ogni esempio viene generato da frasi consecutive e viene troncato a una lunghezza casuale da una distribuzione fissa. Ciò consente al modello di vedere frasi tagliate durante l’addestramento e di gestire risultati temporanei durante l’inferenza. Quindi, addestriamo il modello su circa 300 megabyte di testo Wikipedia e lo perfezioniamo su trascrizioni di riunioni Webex. Il pre-addestramento su Wikipedia aiuta a migliorare tutte le classi di punteggiatura, ma è particolarmente utile su classi di maiuscole/minuscole. Sospettiamo che questo sia dovuto al grande numero di nomi propri presenti in Wikipedia. Applichiamo la stessa preparazione di dati ai nostri set di valutazione concatenando frasi e troncandole in modo casuale. Ciò ci consente di misurare la precisione che vorremmo vedere negli stati di trascrizione temporanei.Conclusione
Utilizzando tecniche relativamente semplici con personalizzazioni dell’architettura, come GRU troncato e una penalità aggiuntiva in una funzione di perdita, abbiamo costruito un modello che può essere eseguito online. L’esperienza di lettura di sottotitoli in diretta è significativamente migliorata con segni di punteggiatura e maiuscole/minuscole in tempo reale. Riferimenti [1] A. Gravano, M. Jansche e M. Bacchiani, “Restoring punctuation and capitalization in transcribed speech” in ICASSP 2009, 2009, pp. 4741–4744. [2] Monica Sunkara, Srikanth Ronanki, Kalpit Dixit, Sravan Bodapati, Katrin Kirchhoff, “Robust Prediction of Punctuation and Truecasing for Medical ASR” [3] Tilk, Ottokar & Alumäe, Tanel. (2016). Bidirectional Recurrent Neural Network with Attention Mechanism for Punctuation Restoration. 3047-3051. 10.21437/Interspeech.2016-1517. [4] Vardaan Pahuja, Anirban Laha, Shachar Mirkin, Vikas Raykar, Lili Kotlerman, Guy Lev “Joint Learning of Correlated Sequence Labelling Tasks Using Bidirectional Recurrent Neural Networks” [5] Wang, Peilu & Qian, Yao & Soong, Frank & He, Lei & Zhao, Hai. (2015). Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Recurrent Neural Network. [6] Lita, Lucian & Ittycheriah, Abe & Roukos, Salim & Kambhatla, Nanda. (2003). tRuEcasIng. 10.3115/1075096.1075116. [7] https://github.com/google/sentencepiece Iscriviti a Webex Visita la nostra home page o contattaci direttamente per assistenza. Fai clic qui per ulteriori informazioni sulle offerte di Webex e per eseguire l’iscrizione a un account gratuitoAbout The Author


