
Einführung
Systeme für die automatische Spracherkennung (Automatic Speech Recognition, ASR) erstellen Abschriften von Texten. In der Regel sind das Abfolgen von Wörtern. Cisco setzt ASR-Systeme ein, um in Webex Meetings in Echtzeit Untertitel zu erstellen. Ein Problem besteht darin, dass es schwierig sein kann, Untertitel zu lesen, in denen weder Interpunktion noch Groß- und Kleinschreibung verwendet wird. Die Verständlichkeit der Bedeutung eines Textes hängt von der Interpunktion ab. So gibt es bei der englischen Wortfolge:„thank you your donation just helped someone get a job“ zwei unterschiedliche Interpunktionsmöglichkeiten.
Option A: „Thank you! Your donation just helped someone get a job.“ Das bedeutet auf Deutsch: „Vielen Dank! Mit Ihrer Spende haben Sie gerade jemandem geholfen, einen Job zu finden.“
Option B: „Thank you! Your donation just helped someone. Get a job.“ Das hat auf Deutsch allerdings eine ganz andere Bedeutung, nämlich: „Vielen Dank! Mit Ihrer Spende haben Sie gerade jemandem geholfen. Suchen Sie sich einen Job.“
Ein einziges Satzzeichen macht einen gewaltigen Unterschied.
Wir stellen einige Überlegungen an, die bei der Entwicklung eines Systems für die Nachbearbeitung berücksichtigt werden müssen:- Hochgradig präzise Modelle für die Wiederherstellung von Satzzeichen und Groß-/Kleinschreibung aus Rohtexten. Schnelle Schlussfolgerungen anhand von Zwischenergebnissen, um mit den Untertiteln in Echtzeit Schritt zu halten.
- Geringe Ressourcennutzung: Spracherkennung benötigt viel Rechenleistung. Deswegen dürfen die Interpunktionsmodelle nicht auch noch rechenintensiv sein.
- Fähigkeit, Wörter zu verarbeiten, die nicht im Vokabular enthalten sind: Manchmal muss die Groß- und Kleinschreibung oder Interpunktion für Wörter festgelegt werden, die das Modell noch nicht kennt.
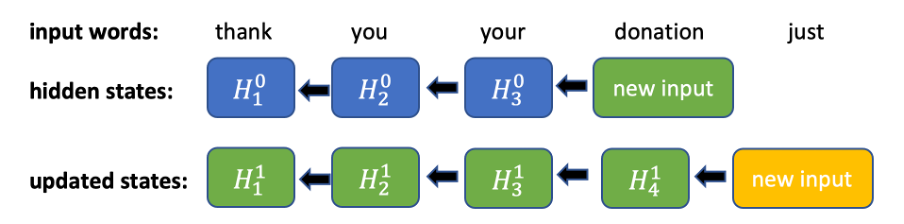
Abbildung 1. Berechnungen zur Rückwärtsberechnung eines bidirektionalen RNN. Bei jeder neuen Eingabe müssen alle vorherigen verborgenen Zustände der Reihe nach aktualisiert werden.
TruncBiRNN
Intuition und Experimente zeigen, dass es unabdingbar ist, den zukünftigen Kontext zu kennen, wenn man ein Interpunktionsmodell entwickelt, weil es schwieriger ist, die Interpunktion an einer bestimmten Position zu bestimmen, wenn man die folgenden Wörter nicht kennt. Damit wir Informationen über die nächsten Token nutzen können und nicht alle verborgenen Zustände aller Token rückwärts aktualisieren müssen, haben wir beschlossen, die Bearbeitung in Rückwärtsrichtung zu beschränken und auf ein festes Fenster zu kürzen. In Vorwärtsrichtung handelt es sich lediglich um ein normales RNN. In Rückwärtsrichtung berücksichtigen wir bei jedem Token nur ein festes Fenster und wenden das RNN auf dieses Fenster an (Abbildung 2). Mithilfe dieses Fensters können wir eine konstante Zeitinferenz für neue Eingabetoken erhalten (wir müssen einen verborgenen Zustand in Vorwärtsrichtung berechnen und n+1 in Rückwärtsrichtung).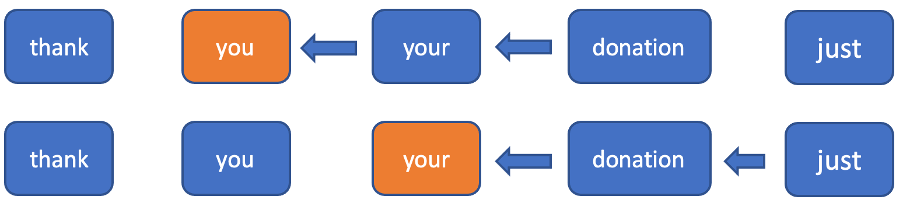
Abbildung 2. In diesem Beispiel werden bei der Rückwärtsberechnung des verborgenen Zustands für jeden aktuellen Token jeweils nur die beiden folgenden berücksichtigt.
Architektur
Die Architektur besteht aus Einbettungsebene, TruncBiGRU- und unidirektionaler GRU-Ebene und vollständig vernetzter Ebene. Für die Ausgabe verwenden wir zwei Softmax-Ebenen, je eine für die Interpunktion und die Groß- und Kleinschreibung (Abbildung 3).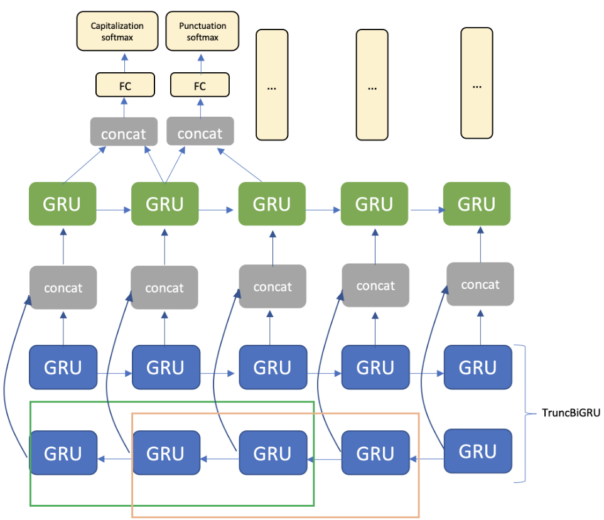
Abbildung 3. Modellarchitektur mit einer Fenstergröße von zwei Token für TruncBiGRU.
Punkt – Punkt in der Mitte eines Satzes, der nicht zwangsläufig darauf hinweist, dass das nächste Wort groß geschrieben werden sollte („z. B., „d. h.“ usw.)
Komma
Fragezeichen
Auslassungszeichen
Doppelpunkt
Bindestrich
abschließender Punkt – Punkt am Satzende
Für die Groß- und Kleinschreibung verwenden wir vier Klassen:Kleinbuchstaben
Großbuchstaben – alle Buchstaben werden groß geschrieben („IEEE“, „NASA“, usw.)
Großbuchstabe am Wortanfang
Mischform – Wörter wie „iPhone“
Großbuchstabe am Satzanfang – Wörter, die einen Satz einleiten
Die zusätzlichen Klassen „Großbuchstabe am Satzanfang“ (leading capitalized) und „abschließender Punkt“ (terminal period) mögen zunächst überflüssig erscheinen, sie leisten jedoch einen Beitrag zu konsistenteren Antworten im Hinblick auf Groß- und Kleinschreibung sowie Interpunktion. Der „abschließende Punkt“ deutet darauf hin, dass die Antwort bei der nächsten Frage der Groß- und Kleinschreibung nicht „Kleinbuchstaben“ sein kann, wohingegen „Großbuchstabe am Satzanfang“ bedeutet, dass das vorhergehende Satzzeichen ein „abschließender Punkt“ oder ein Fragezeichen sein muss. Diese Klassen spielen eine wichtige Rolle für die Verlustfunktion. Verlustfunktion: Wir müssen die Groß- und Kleinschreibung und die Interpunktion optimieren. Dazu verwenden wir die Summe aus einer logarithmischen Verlustfunktion mit einem Koeffizienten: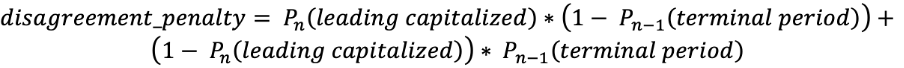 Die erste Bedingung entspricht der Wahrscheinlichkeit, dass ein „Großbuchstabe am Satzanfang“ nach einem Token mit einem anderen Wert als „abschließender Punkt“ steht, und die zweite für die Wahrscheinlichkeit, dass „Großbuchstabe am Satzanfang“ nicht nach „abschließender Punkt“ steht. Dieser Abzug summiert sich, wenn der Fehler bei mehreren Token auftritt. Außerdem übertragen wir zwei aufeinanderfolgende Tensoren von der vorherigen Ebene auf die Softmax-Ebenen. So können wir Abzugsbedingungen effizient reduzieren. Und schließlich ist da noch die Verlustfunktion:
Die erste Bedingung entspricht der Wahrscheinlichkeit, dass ein „Großbuchstabe am Satzanfang“ nach einem Token mit einem anderen Wert als „abschließender Punkt“ steht, und die zweite für die Wahrscheinlichkeit, dass „Großbuchstabe am Satzanfang“ nicht nach „abschließender Punkt“ steht. Dieser Abzug summiert sich, wenn der Fehler bei mehreren Token auftritt. Außerdem übertragen wir zwei aufeinanderfolgende Tensoren von der vorherigen Ebene auf die Softmax-Ebenen. So können wir Abzugsbedingungen effizient reduzieren. Und schließlich ist da noch die Verlustfunktion: 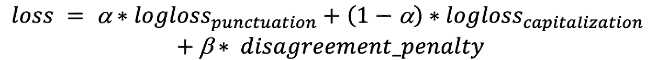
Training
Für das Training verwenden wir Abschriften von Texten aus einigen internen Webex Meetings und Textdaten von Wikipedia. Zunächst werden die Training-Daten bereinigt und in Sätze unterteilt. Während des Trainings wird jedes Beispiel aus aufeinanderfolgenden Sätzen generiert und auf eine beliebige Länge aus einer festen Verteilung gekürzt. Auf diese Weise wird das Modell im Training mit abgeschnittenen Phrasen konfrontiert, die es dem Modell ermöglichen, beim Folgern mit Zwischenergebnissen zu arbeiten. Anschließend trainieren wir ein Modell mit etwa 300 Megabyte Text von Wikipedia und nehmen dann mithilfe der Abschriften von Webex Meetings Feinabstimmungen vor. Das Vorab-Training mit Wikipedia trägt zu Verbesserungen bei allen Interpunktionsklassen bei, es ist jedoch besonders hilfreich bei den Klassen für die Groß- und Kleinschreibung. Wir vermuten, das liegt daran, dass der Wikipedia-Korpus sehr viele Substantive enthält. Wir wenden dieselbe Datenvorbereitung auf unsere Bewertungssätze an, indem wir Sätze kürzen und sie bei einer beliebigen Länge „abschneiden“. Auf diese Weise können wir die Genauigkeit der Ergebnisse erfassen, die wir bei den Zwischenstufen der Abschriften erwarten können.Fazit
Wir haben relativ einfache Techniken mit einigen Anpassungen bei der Architektur, z. B. gekürzte GRU und zusätzliche Abzüge in Verlustfunktionen, eingesetzt, um ein Modell zu entwickeln, das online ausgeführt werden kann. Live-Untertitel sind deutlich leichter lesbar, wenn Interpunktion sowie Groß- und Kleinschreibung in Echtzeit hinzugefügt werden. Literatur [1] A. Gravano, M. Jansche und M. Bacchiani: „Restoring punctuation and capitalization in transcribed speech“, in ICASSP 2009, 2009, S. 4741–4744. [2] Monica Sunkara, Srikanth Ronanki, Kalpit Dixit, Sravan Bodapati, Katrin Kirchhoff: „Robust Prediction of Punctuation and Truecasing for Medical ASR“ [3] Tilk, Ottokar und Alumäe, Tanel (2016): „Bidirectional Recurrent Neural Network with Attention Mechanism for Punctuation Restoration“, 3047-3051. 10.21437/Interspeech.2016-1517 [4] Vardaan Pahuja, Anirban Laha, Shachar Mirkin, Vikas Raykar, Lili Kotlerman, Guy Lev: „Joint Learning of Correlated Sequence Labelling Tasks Using Bidirectional Recurrent Neural Networks“ [5] Wang, Peilu und Qian, Yao und Soong, Frank und He, Lei und Zhao, Hai. (2015): „Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Recurrent Neural Network“ [6] Lita, Lucian und Ittycheriah, Abe und Roukos, Salim und Kambhatla, Nanda (2003): tRuEcasIng. 10.3115/1075096.1075116. [7] https://github.com/google/sentencepiece Bei Webex anmelden Besuchen Sie unsere Homepage oder kontaktieren Sie uns direkt, wenn Sie Unterstützung benötigen. Klicken Sie hier, um mehr über die Angebote von Webex zu erfahren und sich für ein kostenloses Konto anzumelden.About The Author


