
A deep dive series on Webex AI Agent
This blogpost is dedicated to the memory of Jay Patel, an enthusiastic champion of our AI Agent vision and a tireless advocate for every millisecond of improvement.
Why low latency matters for voice AI
In voice AI, latency is everything. Humans naturally pause for only a few hundred milliseconds between speaking turns — so when an AI agent waits longer, the conversation immediately feels robotic and inattentive. For AI agents, staying within that natural pause window is critical because even small delays can break the flow and frustrate customers.
On telephony network (PSTN) the challenge is even tougher, as roughly 500 ms of latency is introduced across the call path – leaving only a few hundred milliseconds for turn detection, retrieval, reasoning and speech synthesis. Efficiency in every component is essential to keep conversations flowing naturally.
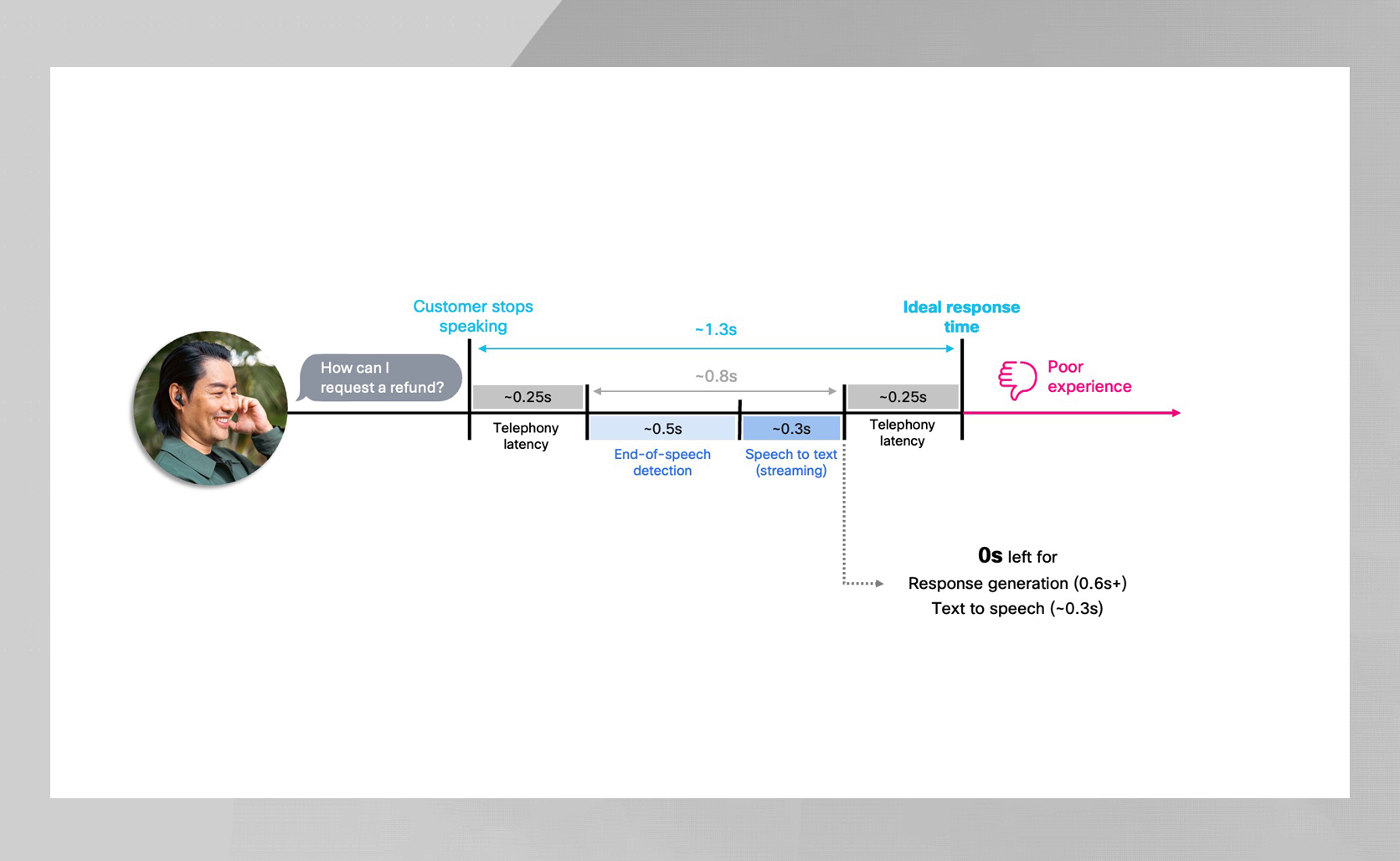
Yet speed alone isn’t enough. Smaller models may be fast, but real customer-facing agents must also be accurate, instruction-following, hallucination-resistant, and enterprise-grade — qualities tiny models simply don’t deliver. Larger models provide that intelligence, but at the cost of added latency. And that latency matters most once you move beyond web demos and into real calls. Delivering speed is easy in web demos, where connections are higher fidelity and avoid the PSTN’s extra latency and encoding overhead. The real challenge is delivering that intelligence while still responding in under a second on real telephony paths.
This is where Cisco takes a unique approach. By combining the intelligence of high-quality models with deep latency engineering, Webex AI Agent delivers responses that are smart, immediate, and feel human.
Our approach
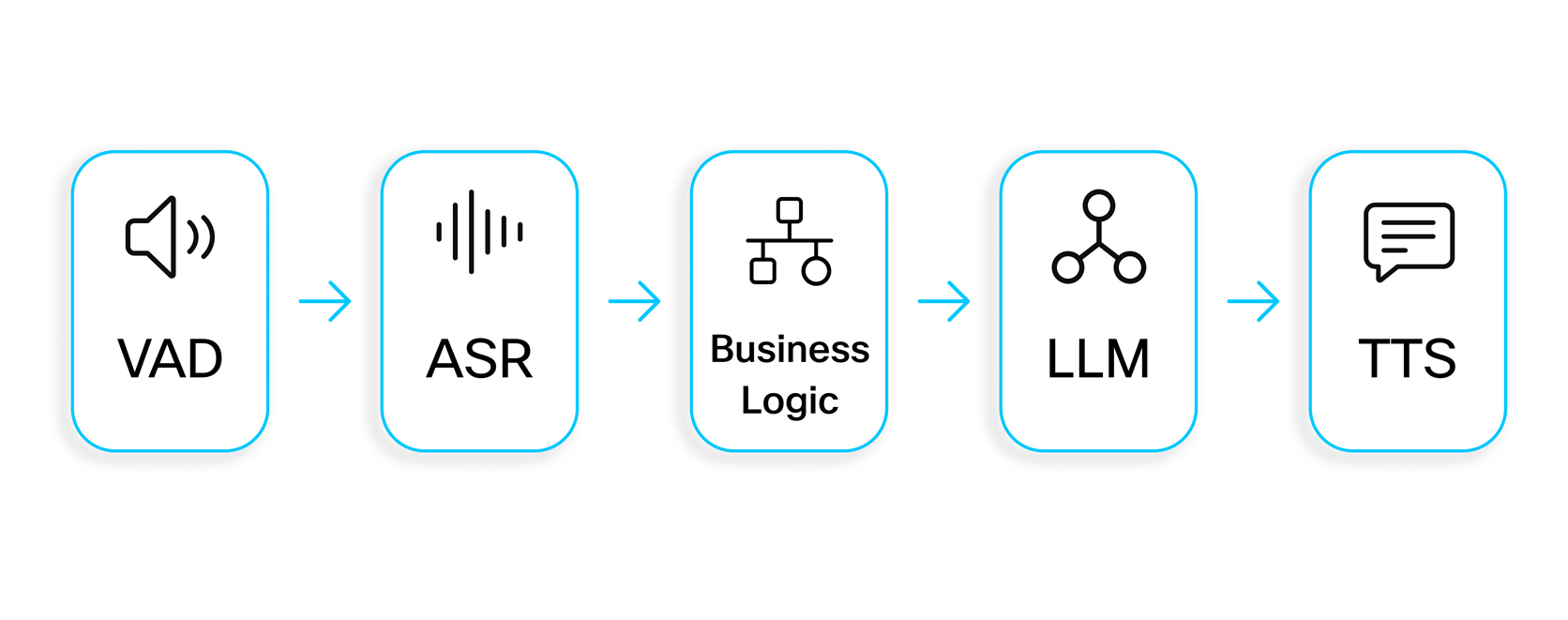
To deliver natural, low-latency responses, we use a modular pipeline: Voice Activity Detection (VAD) → Automatic Speech Recognition (ASR) → business logic → Large Language Model (LLM) → Text-to-Speech (TTS). This structure provides transparency and allows each component to be tuned for both speed and quality.
VAD detects when the customer starts and stops speaking, enabling barge-in and turn taking, while ASR converts speech to text, a critical step since all downstream logic relies on its accuracy. The business logic layer then interprets the transcript, managing turn detection (with entity-aware checks like digit sequences), grounding LLM responses with retrieval-augmented generation (RAG), which fetches relevant facts from corporate knowledge bases to prevent hallucinations, and handling additional decisions such as small-talk detection and tool usage.
The LLM generates the answer using transcript, context, and retrieved data, and TTS produces the natural audio the customer hears. We currently deploy trillion-parameter commercial models alongside Cisco’s internal models to balance accuracy and latency, as detailed in our Webex AI Transparency Note. VAD and turn detection ensure we know precisely when to speak, RAG and business logic ground the answers, and the LLM and TTS deliver high-quality responses – all within strict timing constraints. Behind the scenes, several proprietary Cisco models provide additional intelligence and latency optimizations, further enhancing accuracy and responsiveness.
These choices will continue to evolve as the industry and model capabilities advance.
Generating the first part of the final answer upfront
A key optimization is generating the beginning of the final answer while the customer is still speaking. Instead of waiting for a full transcript and completed retrievals, we pre-compute an initial segment so that playback can start immediately once VAD and TD confirm the end of turn. This mirrors human conversation: skilled agents begin speaking as they’re still formulating the rest of their response. By generating the first part early, we maintain sub-second responsiveness while heavier, more accurate models continue processing in the background.
Why This Matters
Without upfront generation, we’d be forced to use much smaller, less accurate models to meet latency budgets. That means real tradeoffs: the LLM would need to be lightweight with weaker instruction following, the ASR might have to be ultra-fast but less accurate, and the TTS would likely rely on faster but robotic-sounding engines. In practice, customers would get responses sooner, but those responses would be noticeably less helpful, natural, and trustworthy.
By generating and caching the first part early, we create valuable time for slower, higher-quality reasoning, retrieval, and synthesis. That breathing room lets larger, more capable models run in the background to perform the heavier reasoning and retrieval needed to generate intelligent responses – all before the customer ever notices a delay. The result is speed without compromise, rapid responses that are both accurate and natural.
Challenges and Design Choices
Generating early output introduces several requirements:
- Incomplete input: The early segment must be safe, contextually plausible, and able to continue naturally after the full reasoning completes.
- Continuation model: We never discard the early part; the final answer simply continues from it.
- Mid-sentence flexibility: The early part doesn’t need to be a full sentence (e.g., “I’m happy to help…”), making it blend seamlessly into the final answer.
- Multiple candidates: We generate several possible starts and pick the best one as more context arrives.
This design delivers a single, smooth response from the customer’s perspective, even as complex processing continues behind the scenes.

Additional latency optimizations
Across the stack, we implement multiple engineering optimizations, each shaving small amounts of time to keep the pipeline fast even when using higher-quality models.
Streaming
- Low-latency ASR/TTS streaming
- LLM token streaming
Infrastructure
- Regional media colocation
- Reserved capacity for critical LLM calls
Modelling
- Hybrid multi-model mixtures for lightweight tasks
- Robust End of Speech (EOS) detection combining VAD, ASR, and custom signals
Caching
- Common prompt caching
- Pre-synthesized audio
On the infrastructure side, we build multiple layers of resilience to keep latencies predictable under real production conditions. This includes an LLM proxy with regional failover, parallel “safety-net” requests to hedge against slow LLM responses, coordinated retries and caching for ASR and TTS paths, and a system-wide orchestration layer that dynamically adjusts model sizes and fallback strategies.
Real life latency numbers
We measure latency from the moment the customer stops speaking to when they hear the first audio. In practice, the breakdown looks like this:
- VAD EOS: ~500 ms
- Turn Detection: <75 ms p99
- First part of answer: Already generated + cached by EOS
- TTS for the first segment: Usually 10–20 ms (due to cache hits)
- PSTN return path: ~500 ms
Because the early segment is ready immediately at EOS, playback can start almost instantly. Meanwhile, the heavier generation and RAG retrieval complete in parallel, seamlessly continuing the answer. The result is natural, sub-second responsiveness despite larger models running in the background.
Our low latency advantage
Delivering a truly human, natural, and immediate voice AI experience requires more than connecting ASR, LLM, and TTS. It demands careful orchestration of every component — precision turn detection, early-answer generation, caching, and resilient infrastructure — all working together to minimize latency without compromising intelligence.
Webex AI Agent combines high-quality models with deep latency engineering to consistently achieve ~1.3 second PSTN latencies over real telephony paths. The result is an AI agent that feels human, attentive, and reliable, helping enterprises meet customer expectations while maintaining accuracy, grounding, and enterprise-grade reliability.
Discover how Webex AI Agent can bring fast, natural, and accurate voice experiences to your PSTN interactions — reach out to your Webex sales representative or partner for a personalized demo.
About The Authors





