
In the last blog we introduced RTCP, its common header format, and the Sender Report. In this blog we will examine the corresponding Receiver Report (RR), which is used to provide information about media received by the RR sender, as well as SDES, which among other things is key to stream synchronization.
Receiver Report (RR)

The format of the Receiver Report (RR) is essentially identical to that of the Sender Report except that it uses a Payload Type of 201, and it does not contain a Sender Info block. Otherwise, the format is identical. An RR should be sent by a device that is only receiving media on an RTP session and not sending any itself (otherwise it should send a Sender Report).
The RR still contains a Reporter SSRC, though since there is no associated RTP its value is essentially irrelevant. However, as a matter of best practices, an implementation should ideally generate a random value that is different from any other SSRCs, and use it consistently for RRs when sending RRs.
Technically since there is a limit on the number of Report Blocks an SR or RR can include, it may be necessary to send one or more follow-up RRs if more than 31 RTP streams are being received on a single media session. In practice this is a very specialized use-case that is unlikely to come up and most implementations won’t need to consider.
Sender Description (SDES)
The Source Description packet can be used to attach additional, non-media information to an RTP media stream, such as email addresses and telephone numbers. In practice most of this information, if needed, is better conveyed in some other layer such as the call signaling, making many fields of the SDES packet less relevant now than they might once have been. However, one element, the CNAME, is still both important and mandatory. The SDES packet can also be easily extended to convey proprietary information.
The SDES packet contains the regular header, with a Payload Type of 202, and the Item Count is equal to the number of SSRC/CSRC Chunks in the packet, followed by zero or more SSRC/CSRC Chunks that contain information about a particular SSRC or CSRC, each aligned to the 32-bit boundary.
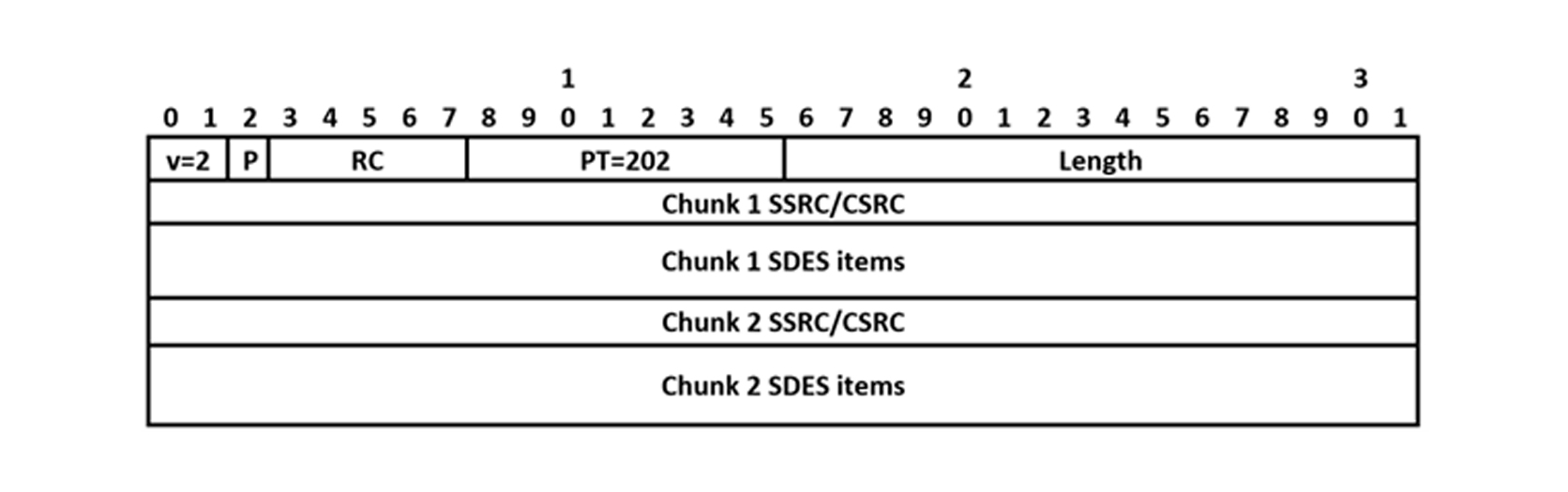
Each chunk contains a 32-bit SSRC or CSRC, and then zero or more items containing information about that SSRC/CSRC.
Each item is made up of an 8-bit type field, an 8-bit length field (which does not include the 2 bytes for the type and length) and a value field of up to 255 bytes.
Items are contiguous and do not need to start or terminate on 32-bit boundaries, but the chunk as a whole is terminated by at least one null (0) byte, and further null bytes must be added to pad the chunk to the 32-bit boundary. As such a well-constructed chunk will always have between 1 and 4 null bytes at the end. Note that these null bytes are part of the SDES item and hence do not count as padding when it comes to setting the Padding byte in the header.
Technically the contents of values are UTF-8, though implementations concerned about interoperability may wish to use US-ASCII to minimize issues when dealing with receivers that do not correctly interpret the values as Unicode.
CNAME
The key item for video conferencing is the Canonical End-Point Identifier, or CNAME, which has a type value of 1. The CNAME serves several key purposes:
- It provides a consistent binding between SSRCs, which can change for a stream at any time. A CNAME should be consistent throughout a call.
- The CNAME should be unique across all streams within an RTP session.
- The CNAME is used in stream synchronization (eg, lipsync).

It is the responsibility of the sender to choose CNAME values to use. The specification RFC 3550 recommends using the device’s hostname, or username plus hostname, as this has the ‘advantage’ of allowing third-parties to identify the sender purely from the RTP/RTCP stream. However, in modern times this is problematic: it raises significant privacy concerns, and for devices without a configured hostname on a private network it is not impossible that two devices could generate clashing CNAMEs (eg, 192.168.1.176).
As such, many modern implementations prefer to use something anonymous and unique such as a UUID. The original specification also suggests that the CNAME is persistent across time for a given device, primarily for debugging cases, and an implementation can choose to preserve their chosen value and reuse it for all calls, but even that can have privacy concerns, and for that and for simplicity reasons it is now generally preferred to generate a new value for each call. This is suggested in RFC 7022, which is dedicated purely to selecting CNAMEs, and which refutes most of the suggestions in the original RFC 3550, and is in fact made mandatory for WebRTC in the WebRTC specification RFC 8834.
While RFC 3550 defines all item values as UTF-8, it is highly recommended that CNAMEs are restricted to US-ASCII characters for interoperability reasons.
However the value is chosen, one key property of CNAMEs is that they identify streams that belong to a single synchronization context. This means that the timestamps of the RTP streams have been generated from a common clock, and hence can be synchronized by adjusting the playout of one or more streams using the RTP timestamps – see the Synchronization section of the relevant RTP blog for more details on how this is done. Streams that have different CNAMEs should not be synchronized. Implementations should choose how to handle cases where CNAMEs are not received for one or more streams; the simplest behavior is to not synchronize these streams.
While the SDES specification does not specify an ordering of items it is recommended that implementations that choose to send items other than CNAME put the CNAME item first in the chunk, as receivers may be coded such as to assume that will be its location.
Other Items
A range of other items are also defined in the base specification:
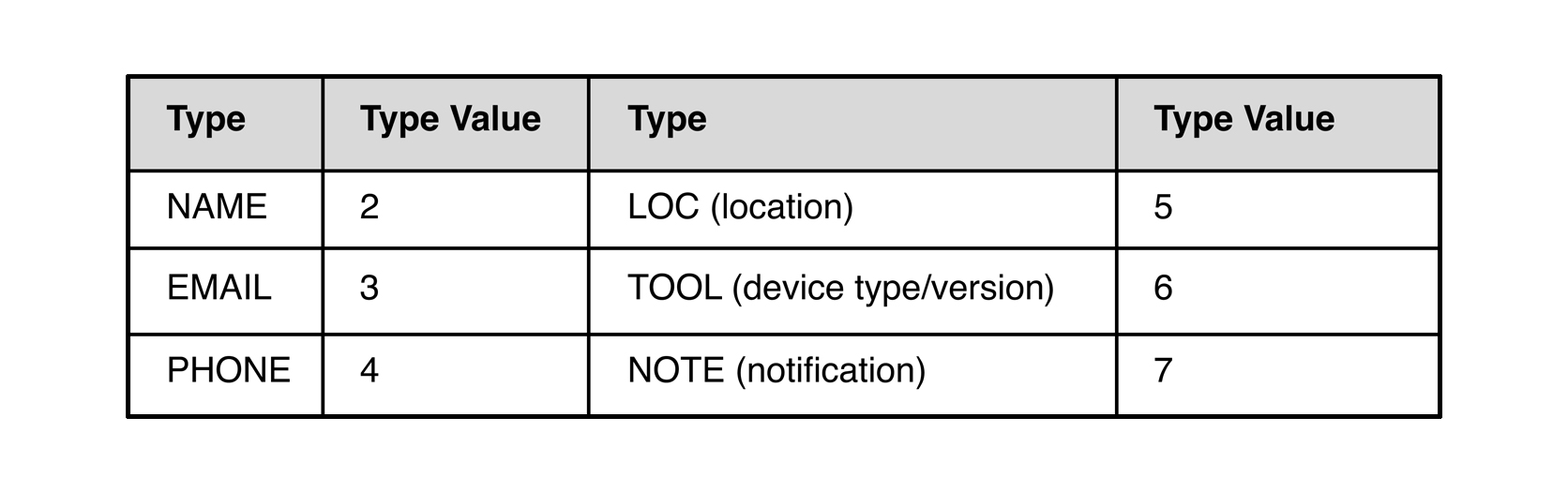
In practice very few devices send any of these, and an implementation can safely ignore any that they are not expecting.
One final item is defined, PRIV, with a value of 8.

This type is reserved for PRIVate extensions, which applications can use for application-specific items. These are created by splitting the item’s value string into three sections:
- Prefix length: 8 bits, defines the length of the prefix string in bits.
- Prefix string: A variable number of bits, containing a string that uniquely identifies the extension.
This should be as short as possible while remaining unique, though as the number of private RTCP extensions will be small there is no need for anything as long and robust as a UUID. It is recommended that this prefix string is in US-ASCII. - Value string: The contents of the private extensions.
Remember that the length field is equal to the length of the three subsequent sections, and that that length must not exceed 255 bytes (one of the main reasons to keep the prefix string short).
It is worth noting that some implementations prefer to do proprietary extensions by picking an unused type value and using that for their application-specific values. That is simpler than the PRIV mechanism, but it is worth noting that unlike PRIV there is no defined mechanism in SDES to avoid a clash with some other implementation’s own application-specific values.
In an environment where an implementation will be using proprietary SDES extensions and interoperating with third-party devices, it should either use PRIV for the extensions or add some indication at the signaling level to identify whether the far end supports this extension.
Proprietary extensions using a new item type should pick a number in the top half of the range (128-255) to avoid a clash with potentially standardized items.
New standardized SDES items are defined by more recent specifications. A full list can be found in the IANA registry for RTP Parameters.
Safely parsing SDES packets
A robust parser should not assume that the CNAME is the first item in a chunk, but should parse all items even if it plans to ignore everything but the CNAME.
The parser should ignore items of an unknown type, or with a type it knows but does not care to parse. If the implementation includes support for one or more private extensions, it should parse the PRIV type and read the prefix string using the prefix length.
When parsing value strings, care should be taken as the strings are length-based and not null-terminated. The implementation should also take care that a malformed length value (accidental or malicious) does not cause it to attempt to read beyond the length of the packet. Inside PRIV packages a similar check should be applied when reading the prefix string via the prefix length, which should always be less than or equal to (item length-8).
Goodbye (BYE)
A Goodbye packet (more commonly just referred to as a BYE) indicates that one or more RTP media sources will no longer be sent.
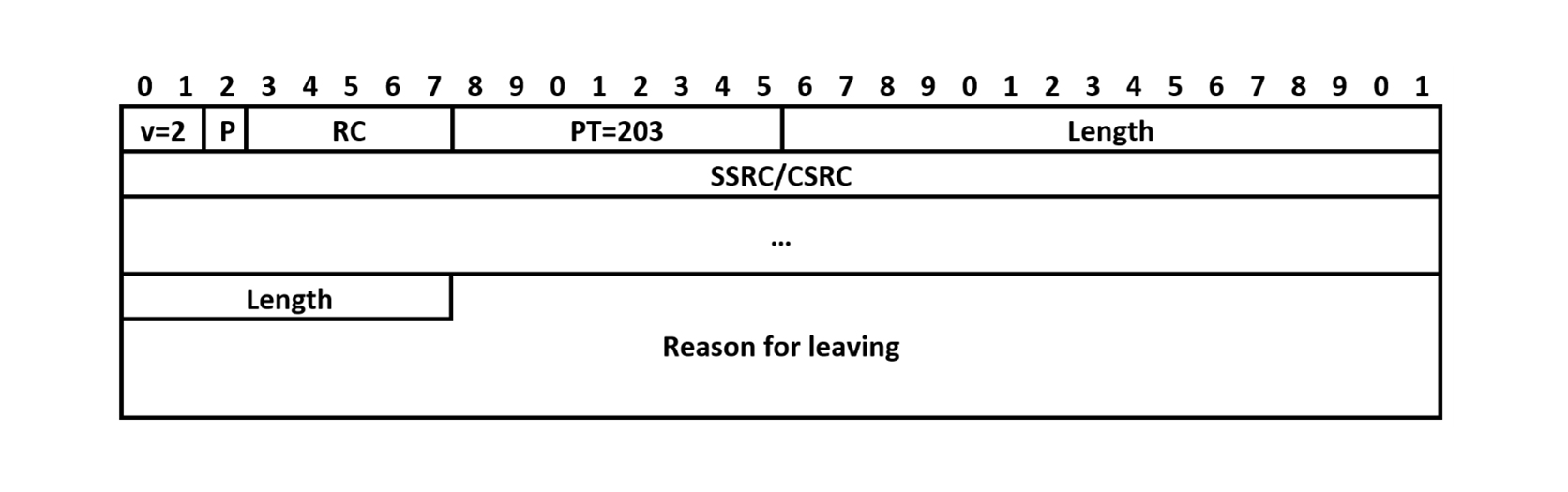
The packet format is very simple. The regular header has a Payload Type of 203 and an Item Count equal to the number of SSRCs or CSRCs that are included in the packet. It then contains that many 32 bit SSRC or CSRCs.
Finally, there is an optional portion with an 8-bit length field and then a field of that many bytes containing a reason for leaving string in UTF-8. This is a human-readable string that could be displayed as a notification or just used for debugging though very few implementations make use of it. If this extension is used, the string should be followed by 0-3 null (0) bytes to ensure this optional portion ends at a 32-bit boundary – these do not count as packet padding and hence do not set the P bit to 1.
A BYE should be sent when an SSRC will no longer be sent, either because the stream itself is ending (e.g., the call has ended) or when the SSRC has changed. It allows the receiver to safely purge any state they are maintaining associated with that old SSRC (for instance, its cryptographic context). Once a BYE has been sent for a given SSRC, that SSRC should not be reused later.
When receiving a BYE an implementation should not purge the associated information immediately, as there is a chance that packet reordering or alternate paths mean that some RTP packets are still in transit. As such, implementations seeking to purge such information should include a small delay to avoid such issues.
As a receiver, be aware that not all implementations will send BYEs, and that even if they do, they may not be received, as RTCP is normally sent over UDP and has no built-in resilience. This may result in a receiver needing to cache the state associated with multiple SSRCs in case they are used again.
When pausing a stream (for reasons such as a user muting it, or it being a content media channel when sharing has stopped), it is recommended that the sender send a BYE on that channel immediately, and then use a new SSRC when that stream is restarted. This avoids any risk of the receiver having chosen to discard the state associated with the old SSRC due to no packets having been received for a long period when the stream is eventually resumed. Cases where one side of a call discards such state while the other retains it leads to major issues when SRTP encryption is in use, so implementations should take efforts to reduce such risks.
In the next, final blog in the series we will look at some ways applications can define their own proprietary RTCP messages, along with some of the most widely supported RTCP messages defined subsequent to the initial standard.
About The Author




