
소개
ASR(자동 음성 인식) 시스템은 텍스트 변환 기능을 제공합니다. 일반적으로 텍스트는 일련의 단어들입니다. Cisco는 ASR 시스템을 사용하여 Webex 미팅에 실시간 자막을 제공합니다. 이때 발생하는 한 가지 문제는 구두점과 대문자가 없으면 자막을 읽기 어려울 수 있다는 점입니다. 텍스트의 의미를 이해할 수 있는지 여부는 구두점에 따라 달라질 수 있습니다. 다음과 같이 두 가지 방법으로 구두점을 표기할 수 있는 일련의 단어를 생각해 보세요.“thank you your donation just helped someone get a job”.(감사합니다 여러분의 후원이 누군가의 취업을 도왔습니다.)”.
옵션 A: “Thank you! Your donation just helped someone get a job.(감사합니다! 여러분의 후원이 누군가의 취업을 도왔습니다.)”
옵션 B: “Thank you! Your donation just helped someone. Get a job.(감사합니다! 여러분의 후원이 누군가를 도왔습니다. 여러분의 일을 찾으세요.)”
구두점 하나가 큰 차이를 만듭니다.
다음과 같이 후처리 시스템을 구축할 때의 몇 가지 고려 사항을 살펴보겠습니다.- 원시 텍스트에서 구두점을 복원하고 대문자를 표기하기 위한 정확도 높은 모델. 실시간 자막의 속도를 따라가기 위한 중간 결과에 대한 빠른 추론
- 소규모 리소스 활용: 음성 인식은 계산 집약적이지만, 구두점 모델도 계산 집약적일 필요가 없음
- 어휘가 아닌 단어를 처리하는 능력: 때로는 모델이 이전에 본 적이 없는 단어에 구두점이나 대문자를 표기해야 함
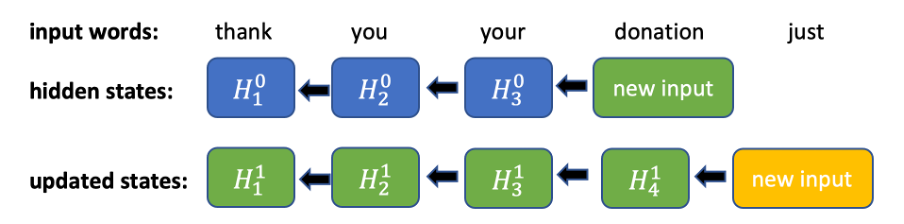
그림 1. 양방향 RNN의 역전파(backward pass)에 대한 연산. 모든 새로운 입력에 대해 이전의 모든 은닉 상태가 연속적으로 업데이트되어야 합니다.
TruncBiRNN
직관과 실험에 따르면 구두점 모델을 만들 때 미래에 대한 컨텍스트를 제공해야 합니다. 다음에 올 몇 개의 단어를 모르는 상태에서는 현재 위치에 올 구두점을 결정하는 것이 어려워지기 때문입니다. 역방향의 모든 토큰에 대한 모든 은닉 상태를 업데이트 해야 할 필요 없이 다음 토큰에 대한 정보를 사용하기 위해 역방향을 고정된 윈도우로 잘라내기로 결정했습니다. 순방향인 경우에는 단순한 일반 RNN입니다. 역방향인 경우에는 각 토큰에 대해 고정된 윈도우만 고려하며 해당 윈도우에 RNN을 실행합니다(그림 2). 이 윈도우를 사용함으로써 새로운 입력 토큰에 대해 일정한 시간 추론을 수행할 수 있습니다(순방향의 경우 1개의 은닉 상태를 계산하며, 역방향의 경우 n+1개의 은닉 상태를 계산해야 합니다).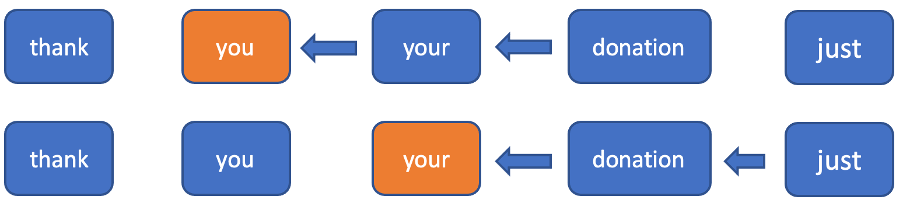
그림 2. 이 예에서는 각 현재 토큰에 대해 역방향으로 다음 두 개의 토큰만 은닉 상태를 계산하는 것으로 간주됩니다.
아키텍처
아키텍처는 임베딩 계층, TruncBiGRU 및 단방향 GRU 계층, 완전 연결 계층으로 구성됩니다. 출력의 경우 구두점과 대문자 표기에 대해 각각 2개의 소프트맥스(softmax) 계층을 사용합니다(그림 3).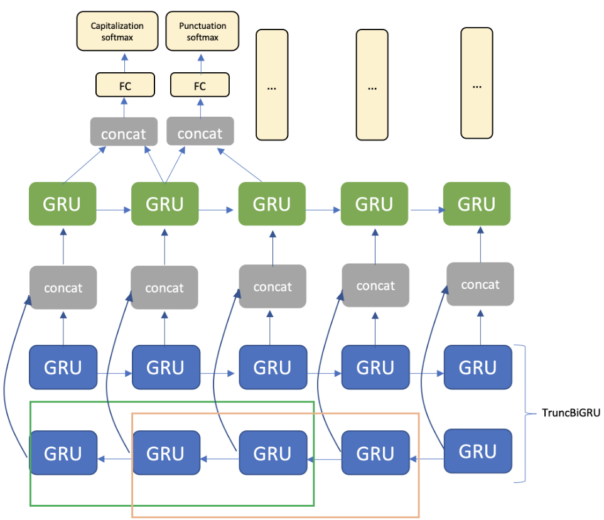
그림 3. TruncBiGRU에 대해 2개의 토큰과 같은 크기의 윈도우를 갖춘 모델 아키텍처.
문장 중간의 마침표 – 문장 중간에 있는 마침표의 경우 다음 단어가 반드시 대문자로 표기되어야 하는 것은 아님(예, “a.m.,””D.C.” 등)
쉼표
물음표
줄임표
콜론
대시
문장 끝 마침표 – 문장 끝에 오는 마침표
대문자 표기의 경우 다음과 같은 네 가지 등급이 있습니다.소문자
전체 대문자 – 모든 문자를 대문자로 표기(예: “IEEE,” “NASA” 등)
대문자
대소문자 혼합 – “iPhone”과 같은 단어
첫글자 대문자 – 문장을 시작하는 단어
추가적인 클래스인 “첫글자 대문자”와 “문장 끝 마침표”는 언뜻 보기에는 중복되는 것처럼 보일 수 있지만 대문자 표기 및 구두점과 관련된 답변의 일관성을 높이는 데 도움이 됩니다. “문장 끝 마침표”는 다음 대문자 표기 답변이 “소문자”가 될 수 없음을 의미하는 한편, “첫글자 대문자”는 이전 구두점이 “문장 끝 마침표”이거나 물음표임을 의미합니다. 이러한 클래스는 손실 함수에서 중요한 역할을 합니다. 손실 함수: 대문자 표기와 구두점을 모두 최적화해야 합니다. 이를 달성하기 위해 계수와 함께 로그 손실 함수 합계를 사용합니다.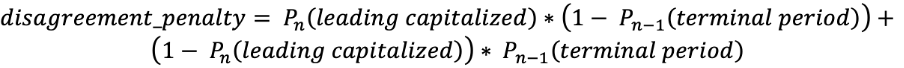 첫 번째 조건은 “첫글자 대문자”가 “문장 끝 마침표”가 아닌 구두점 뒤에 올 확률에 해당하며 두 번째 조건은 “첫글자 대문자”가 “문장 끝 마침표” 뒤에 오지 않을 확률에 해당합니다. 이 벌칙은 이 오류가 발생한 토큰에 합산됩니다. 또한 이전 계층에서 소프트맥스 계층으로 2개의 연속 텐서(tensor)를 전달합니다. 이를 바탕으로 벌칙 조건을 효율적으로 줄일 수 있습니다. 결과적으로 다음과 같은 손실 함수가 됩니다.
첫 번째 조건은 “첫글자 대문자”가 “문장 끝 마침표”가 아닌 구두점 뒤에 올 확률에 해당하며 두 번째 조건은 “첫글자 대문자”가 “문장 끝 마침표” 뒤에 오지 않을 확률에 해당합니다. 이 벌칙은 이 오류가 발생한 토큰에 합산됩니다. 또한 이전 계층에서 소프트맥스 계층으로 2개의 연속 텐서(tensor)를 전달합니다. 이를 바탕으로 벌칙 조건을 효율적으로 줄일 수 있습니다. 결과적으로 다음과 같은 손실 함수가 됩니다. 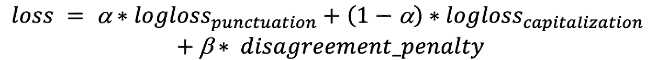
훈련
훈련을 위해서는 일련의 내부 Webex 미팅의 텍스트 변환과 Wikipedia의 텍스트 데이터를 사용합니다. 첫째, 훈련 데이터를 클린하고 문장으로 나눕니다. 훈련 중에는 각 샘플이 연속된 문장에서 생성되고 고정 분포에서 랜덤 길이로 잘려집니다. 이를 통해 모델은 훈련 중에 잘린 문구를 볼 수 있으며, 모델이 추론 중에 중간 결과를 처리할 수 있게 됩니다. 다음으로 약 300메가바이트의 Wikipedia 텍스트에 대한 모델을 훈련한 다음, Webex 미팅 텍스트 변환에 대해 미세 조정합니다. Wikipedia에 대한 사전 훈련은 모든 구두점 클래스를 개선하는 데 도움이 되지만 특히 대문자 표기 클래스에 유용합니다. 이는 Wikipedia corpus에 방대한 양의 고유명사가 있기 때문일 것이라 추측됩니다. 문장을 연결하고 랜덤 길이로 잘라 평가 세트에 동일한 데이터 준비를 적용합니다. 이렇게 하면 중간 텍스트 변환 상태에서의 정확성을 측정할 수 있습니다.결론
Cisco는 잘린 GRU 및 손실 함수의 추가적인 벌칙과 같은 일부 아키텍처 사용자 정의가 적용된 비교적 쉬운 기법을 사용하여 온라인에서 실행할 수 있는 모델을 구축했습니다. 실시간 구두점 및 대문자 표기를 통해 라이브 자막의 읽기 환경이 크게 향상되었습니다. 참고 문헌 [1] A. Gravano, M. Jansche, and M. Bacchiani, “Restoring punctuation and capitalization in transcribed speech,” in ICASSP 2009, 2009, pp. 4741–4744. [2] Monica Sunkara, Srikanth Ronanki, Kalpit Dixit, Sravan Bodapati, Katrin Kirchhoff, “Robust Prediction of Punctuation and Truecasing for Medical ASR” [3] Tilk, Ottokar & Alumäe, Tanel. (2016). Bidirectional Recurrent Neural Network with Attention Mechanism for Punctuation Restoration. 3047-3051. 10.21437/Interspeech.2016-1517. [4] Vardaan Pahuja, Anirban Laha, Shachar Mirkin, Vikas Raykar, Lili Kotlerman, Guy Lev “Joint Learning of Correlated Sequence Labelling Tasks Using Bidirectional Recurrent Neural Networks” [5] Wang, Peilu & Qian, Yao & Soong, Frank & He, Lei & Zhao, Hai. (2015). Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Recurrent Neural Network. [6] Lita, Lucian & Ittycheriah, Abe & Roukos, Salim & Kambhatla, Nanda. (2003). tRuEcasIng. 10.3115/1075096.1075116. [7] https://github.com/google/sentencepiece Webex 가입하기 Webex 홈페이지를 방문하시거나 직접 문의하여 도움을 받아보세요. 여기를 클릭하여 Webex가 제공하는 서비스에 대해 자세히 알아보고 무료 계정에 가입하세요.About The Author

Pavel Pekichev Machine Learning Scientist Cisco
Pavel Pekichev is a Machine Learning Scientist at Cisco working on speech recognition systems.
Learn more
