
Introdução
Os sistemas de Reconhecimento automático de voz (ASR) disponibilizam transcrições de texto. Em geral, não passa de uma sequência de palavras. A Cisco conta com esses sistemas para gerar legendas em tempo real durante as reuniões no Webex. Um problema que acaba surgindo refere-se à possível dificuldade de ler as legendas sem pontuação e uso de letras maiúsculas. A pontuação faz total diferença quando o assunto é entender o significado de um texto. Imagine a seguinte sequência de palavras com duas opções de pontuação:“maria a gerente do banco ligou”.
Opção A: “Maria, a gerente do banco ligou.”
Opção B: “Maria, a gerente do banco, ligou.”
Uma única vírgula pode fazer uma diferença e tanto.
Falaremos sobre várias questões ao criar um sistema de pós-processamento:- Modelos de alta precisão para uso de maiúsculas e restabelecimento de pontuação a partir de um texto básico. Rápida inferência em resultados intercalares: para acompanhar as legendas em tempo real.
- Uso de pequenos recursos: o reconhecimento de voz é exaustivo do ponto de vista computacional; algo que não é necessário aos nossos modelos de pontuação.
- Capacidade de processar palavras fora do vocabulário: às vezes, será necessário pontuar ou usar maiúscula em palavras totalmente desconhecidas para o nosso modelo.
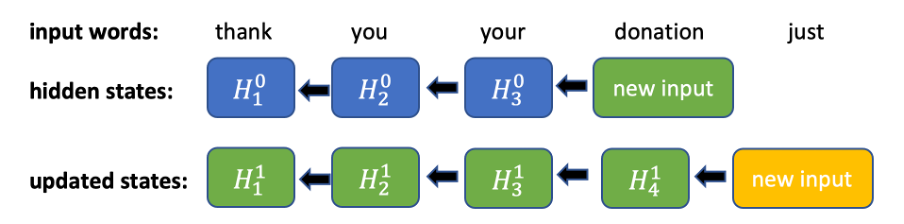
Figura 1. Computações no passo regressivo de uma RNN bidirecional. Todos os status ocultos anteriores devem ser sequencialmente atualizados para cada nova entrada
TruncBiRNN
A intuição e os experimentos apontam que é fundamental ter um contexto futuro ao criar um modelo de pontuação, pois é mais difícil determinar as marcações de pontuação em uma posição atual sem saber as várias outras palavras que se seguem. Para fazer uso de informações sobre os próximos tokens e não precisar atualizar todos os status ocultos de todos os tokens no sentido regressivo, optamos por truncar este sentido a uma janela fixa. No sentido progressivo, é apenas uma RNN normal. No sentido regressivo, consideramos apenas uma janela fixa em cada token, executando a RNN para essa janela (figura 2). Com essa janela, é possível obter uma inferência de tempo constante para um novo token de entrada (é necessário computar um status oculto no sentido progressivo e n+1 no sentido regressivo).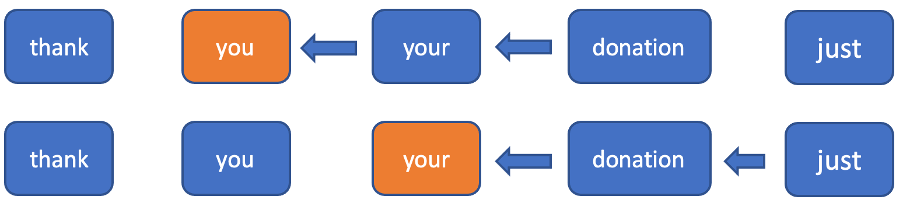
Figura 2. Neste exemplo, para cada token atual, somente os próximos dois são levados em consideração para computação do status oculto no sentido regressivo.
Arquitetura
A arquitetura consiste da camada integrada, TruncBiGRU e camada de GRU unidirecional, e da camada totalmente conectada. Com relação ao resultado, usamos duas camadas softmax para pontuação e uso de maiúscula, respectivamente (figura 3).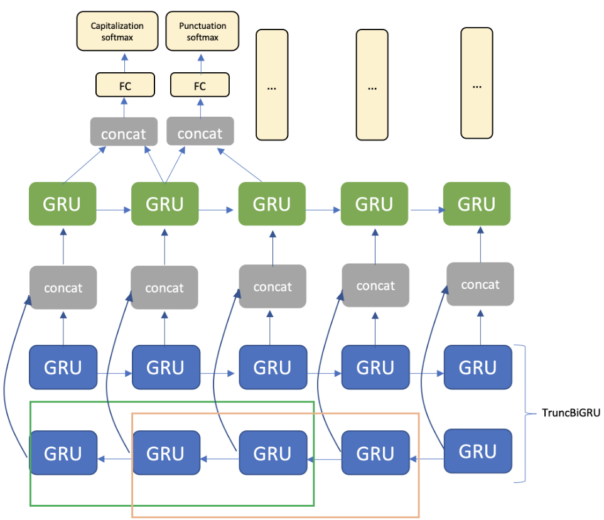
Figura 3. Arquitetura de modelo com tamanho de janela igual a dois tokens para TruncBiGRU.
ponto – um ponto no meio da frase que não sugere, necessariamente, que a próxima palavra deve ser iniciada em maiúscula (“a.m.”,“D.C.”, etc)
vírgula
ponto de interrogação
reticências
dois pontos
travessão
ponto final – um ponto no final de uma frase
Com relação ao uso de maiúscula, há quatro classes:minúscula
maiúscula – todas as letras estão em maiúscula (“IEEE”, “NASA”, etc.)
inicial em maiúscula
alternado – por exemplo, “iPhone”
Primeira palavra com inicial em maiúscula – palavras que iniciam uma frase
As classes adicionais, “primeira palavra com inicial em maiúscula” e “ponto final”, podem soar redundantes a princípio, mas elas ajudam a ampliar a consistência das respostas relacionadas ao uso de maiúscula e pontuação. O “ponto final” sugere que a próxima resposta de uso de maiúscula não pode ser “minúscula”, enquanto “primeira palavra com inicial em maiúscula” indica que a pontuação anterior é um “ponto final” ou ponto de interrogação. Essas classes desempenham um papel importante na função de perda. Função de perda: É necessário otimizar a pontuação e o uso de maiúscula. Para tanto, usamos o produto da função de perda de registro com um coeficiente: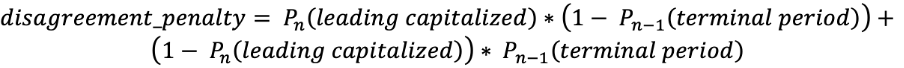 O primeiro termo corresponde à probabilidade de se ter uma “primeira palavra com inicial maiúscula” após um “ponto que não seja final”; o segundo refere-se à probabilidade de não se ter uma “primeira palavra com inicial maiúscula” após um “ponto final”. Essa sanção soma-se com os tokens nos quais esse erro ocorre. Além disso, passamos dois tensores consecutivos da camada anterior às camadas softmax. Dessa forma, é possível reduzir satisfatoriamente os termos de sanção. Por fim, há a função de perda:
O primeiro termo corresponde à probabilidade de se ter uma “primeira palavra com inicial maiúscula” após um “ponto que não seja final”; o segundo refere-se à probabilidade de não se ter uma “primeira palavra com inicial maiúscula” após um “ponto final”. Essa sanção soma-se com os tokens nos quais esse erro ocorre. Além disso, passamos dois tensores consecutivos da camada anterior às camadas softmax. Dessa forma, é possível reduzir satisfatoriamente os termos de sanção. Por fim, há a função de perda: 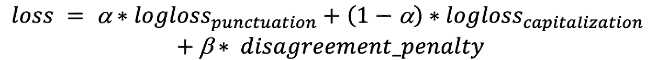
Treinamento
Para fins de treinamento, usamos transcrições de texto de um conjunto de reuniões internas no Webex e dados de texto extraídos do Wikipedia. Antes de tudo, os dados do treinamento são limpos e divididos em duas frases. Durante o treinamento, cada amostra é gerada a partir de frases consecutivas e truncada a uma extensão aleatória de uma distribuição fixa, o que permite ao modelo identificar frases cortadas durante o treinamento e, consequentemente, lidar com os resultados intercalares durante a inferência. Em seguida, treinamos o modelo em um total aproximado de 300 megabites de texto do Wikipedia, ajustando-o a transcrições de reunião no Webex. O pré-treinamento no Wikipedia ajuda a otimizar todas as classes de pontuação, embora seja particularmente útil para as classes de uso de maiúscula, o que se deve, a nosso ver, à grande quantidade de nomes próprios no corpus do Wikipedia. Nós aplicamos a mesma preparação de dados em nossos conjuntos de avaliação ao concatenar frases e truncá-las em extensões aleatórias. Dessa forma, é possível avaliar a precisão do que possivelmente observaríamos em status intercalares de transcrição.Conclusão
Ao fazer uso de técnicas relativamente fáceis com algumas personalizações da arquitetura, como GRU truncada e sanção adicional em uma função de perda, criamos um modelo que pode ser executado on-line. A experiência de leitura de legendas ao vivo é substancialmente otimizada com o uso de maiúscula e pontuações em tempo real. Referências [1] A. Gravano, M. Jansche, and M. Bacchiani, “Restoring punctuation and capitalization in transcribed speech”, in ICASSP 2009, 2009, pp. 4741–4744. [2] Monica Sunkara, Srikanth Ronanki, Kalpit Dixit, Sravan Bodapati, Katrin Kirchhoff, “Robust Prediction of Punctuation and Truecasing for Medical ASR” [3] Tilk, Ottokar & Alumäe, Tanel. (2016). Bidirectional Recurrent Neural Network with Attention Mechanism for Punctuation Restoration. 3047-3051. 10.21437/Interspeech.2016-1517. [4] Vardaan Pahuja, Anirban Laha, Shachar Mirkin, Vikas Raykar, Lili Kotlerman, Guy Lev “Joint Learning of Correlated Sequence Labelling Tasks Using Bidirectional Recurrent Neural Networks” [5] Wang, Peilu & Qian, Yao & Soong, Frank & He, Lei & Zhao, Hai. (2015). Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Recurrent Neural Network. [6] Lita, Lucian & Ittycheriah, Abe & Roukos, Salim & Kambhatla, Nanda. (2003). tRuEcasIng. 10.3115/1075096.1075116. [7] https://github.com/google/sentencepiece Inscreva-se no Webex Acesse nossa página inicial ou entre em contato conosco para obter assistência. Clique aqui para saber mais sobre as ofertas do Webex e para se inscrever em uma conta grátis.About The Author


