
A deep dive series on Webex AI Agent
Customer expectations for AI agents have fundamentally changed. A single poor interaction – a slow response, an irrelevant answer, a hallucinated policy – is enough to erode trust. In high-volume contact centers, accuracy, relevance, and speed are no longer differentiators – they are baseline requirements.
Knowledge has always been at the heart of great customer experience. Long before AI entered the picture, contact center agents depended on vast repositories of information – policies, product manuals, procedures, troubleshooting guides – spanning multiple formats, languages, and systems. Getting customers to the right answer, quickly and accurately, has never been simple.
As AI agents take on more of these workflows, the knowledge challenge doesn’t just remain – it scales. They must continuously draw on vast, fragmented, and constantly evolving information, retrieving it with precision across languages, maintaining context across interactions, and surfacing the right answer in real-time – every time.
Relying on a language model’s internal knowledge alone is simply not enough – and its a liability. Without access to current, enterprise-specific knowledge, AI agents risk confidently delivering outdated or incorrect answers, eroding the very trust they are meant to build.
Common challenges with knowledge retrieval
This is why retrieval has become such a critical part of modern AI systems. In practice, many AI agents use Retrieval-Augmented Generation (RAG), which retrieves relevant information from trusted enterprise sources and uses it to ground the model’s response.
While the concept is simple, delivering it effectively in enterprise environments is far more complex.
In enterprise environments, knowledge retrieval is difficult for a number of reasons:
- Content lives in varied document formats and systems
- Important information is often embedded in complex layouts, including tables, charts, and images
- Knowledge must be retrieved accurately across languages
- Loss of context due to simplistic chunking strategies
- Vector search alone can miss critical results or return loosely related content
- User queries are often conversational, ambiguous, or incomplete
- Latency constraints in real-time environments like contact centers
These obstacles can slow the creation of AI-friendly knowledge repositories, hindering adoption and limiting the effectiveness of AI Agents.
Webex’s approach
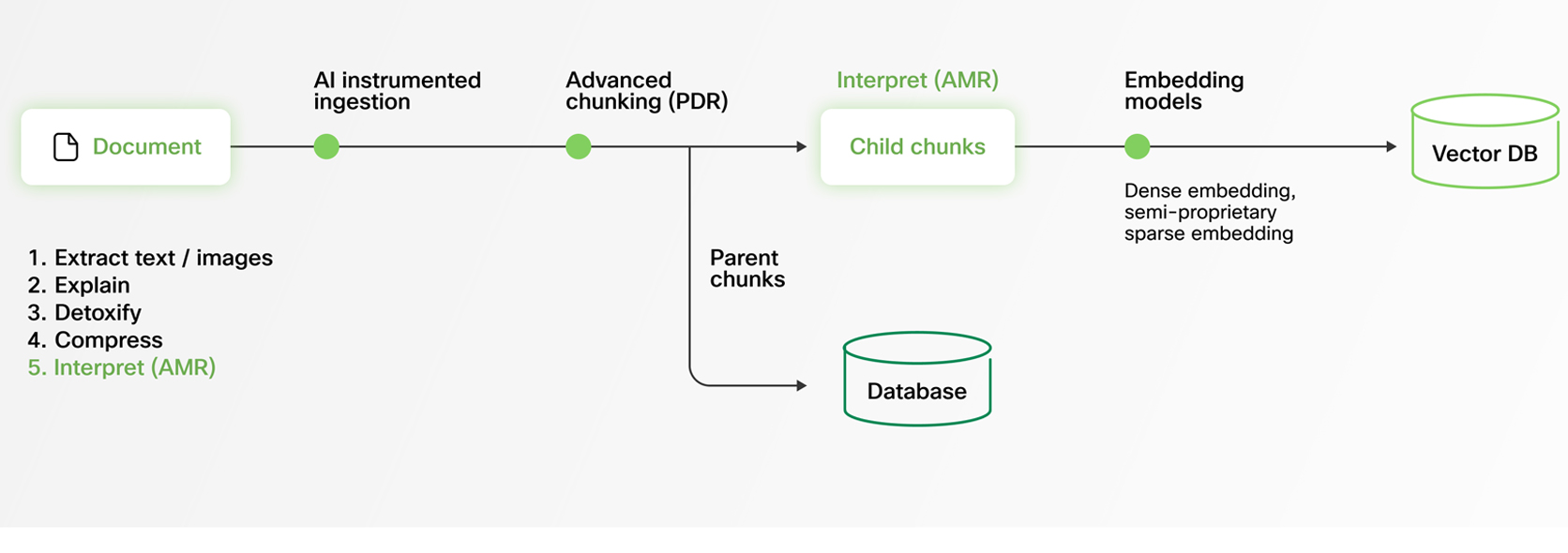
At Webex, we’ve reimagined RAG from the ground up to address these real-world enterprise challenges. Our AI Agent RAG architecture combines advanced document processing, adaptive multilingual intelligence, hybrid retrieval, and low-latency optimization to deliver precise, context-rich answers at scale.
Below, we break down each of these innovations, the engineering decisions behind them, and the impact they deliver in real-world production environments.
Transforming enterprise documents into LLM-ready knowledge
Modern enterprises store knowledge across diverse formats — PDFs, spreadsheets, Word documents, slide decks — that rarely follow clean structures. These documents often contain complex layouts with images, tables, charts, multi-column formatting, and nested sections. For an AI Agent to deliver reliable answers, it must process this content without losing meaning or context.
At Webex, we’ve engineered our AI Agent RAG pipeline to embrace this reality. Our system ingests diverse document formats and extracts structured knowledge from even the most complex files.
To make this content LLM-friendly, we convert everything into Markdown, a versatile and widely adopted format for structured text. This transformation is non-trivial: parsing graphics, preserving table data, and maintaining contextual relationships between elements all require sophisticated processing. Our advanced document pipeline ensures that critical information isn’t lost in translation, empowering AI Agents to generate precise, comprehensive, and contextually accurate responses.
Multilingual by design
For global enterprises, knowledge doesn’t exist in just one language. Product documentation and support content are created and maintained across multiple regions — often in multiple languages. Yet many RAG systems struggle with multilingual content, leading to inconsistent retrieval quality, reduced accuracy, and uneven customer experiences.
The underlying challenge is subtle but significant: while multilingual embedding and re-ranking models have made impressive progress, they still achieve their highest accuracy in English. Robust models for other languages are improving, but performance gaps remain — especially in high-precision retrieval scenarios.
Our AI Agent RAG system is architected from the ground up to solve this through Adaptive Monolingual RAG (AMR).
Regardless of the source document’s language, our system normalizes content to English internally for retrieval and reranking. This enables us to leverage the world’s most advanced English-trained models — delivering industry-leading accuracy, even when the original documents are in other languages.
The result is consistency, precision, and reliability across every deployment, for every customer, in every language.
Context preservation through parent–child chunking
Retrieving the right information in RAG isn’t just about relevance — it’s about context. If too little content is retrieved, the AI Agent may miss critical details. If too much is retrieved, the model can be overwhelmed with irrelevant information. Striking the right balance between precision and completeness is one of the most persistent challenges in production RAG systems.
Webex AI Agent addresses this with a hierarchical Parent–Child Chunking strategy (also known as Parent Document Retrieval).
During retrieval, the system searches across smaller, finely tuned child chunks. This enables fast, precise, and highly granular matching. Once relevant sections are identified, responses are generated using their corresponding parent chunks — larger sections of the document that provide broader context and more complete information.
This dual-level approach ensures that answers are not only accurate, but also context-rich and coherent. Rather than being constrained by arbitrary chunk boundaries, the model benefits from both precision in retrieval and depth in response generation. Combined with modern LLMs’ expanded context windows, this strategy guarantees fully informed, coherent responses.
Understanding smarter retrieval through hybrid search
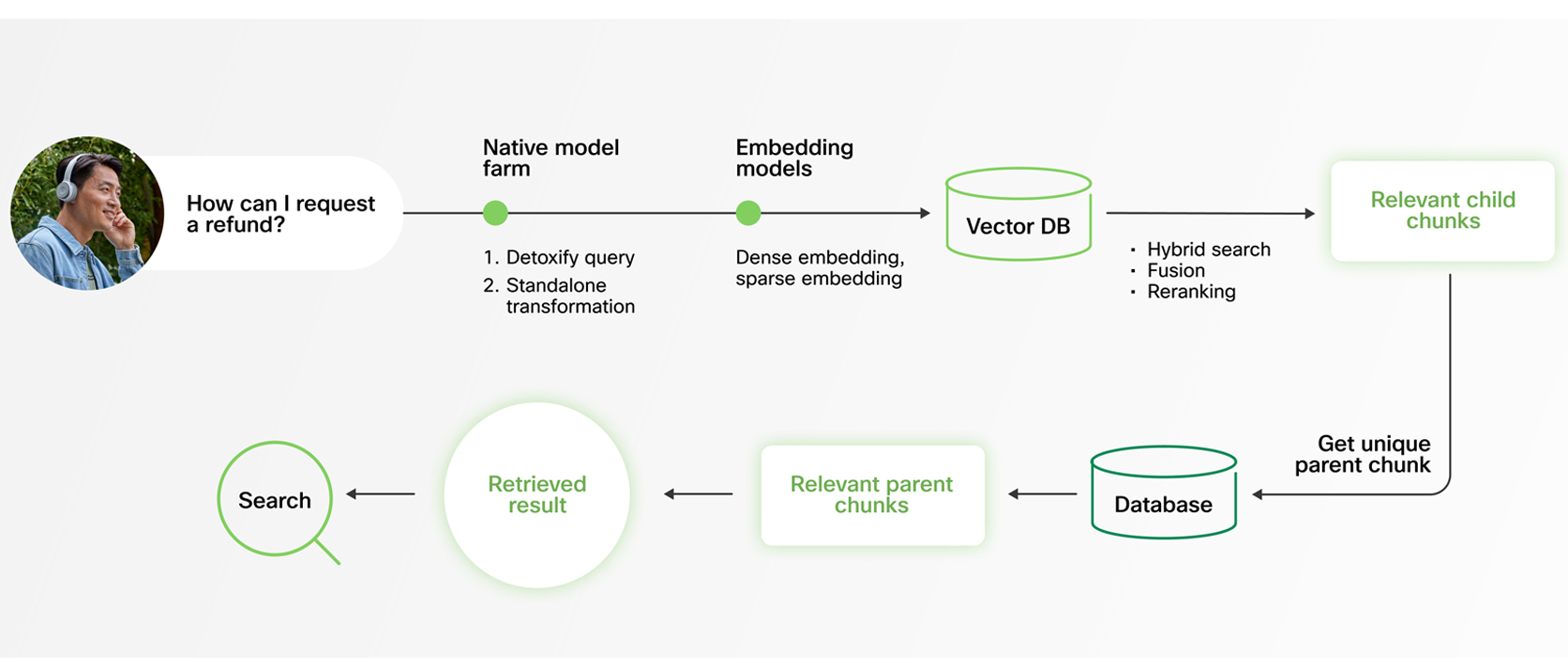
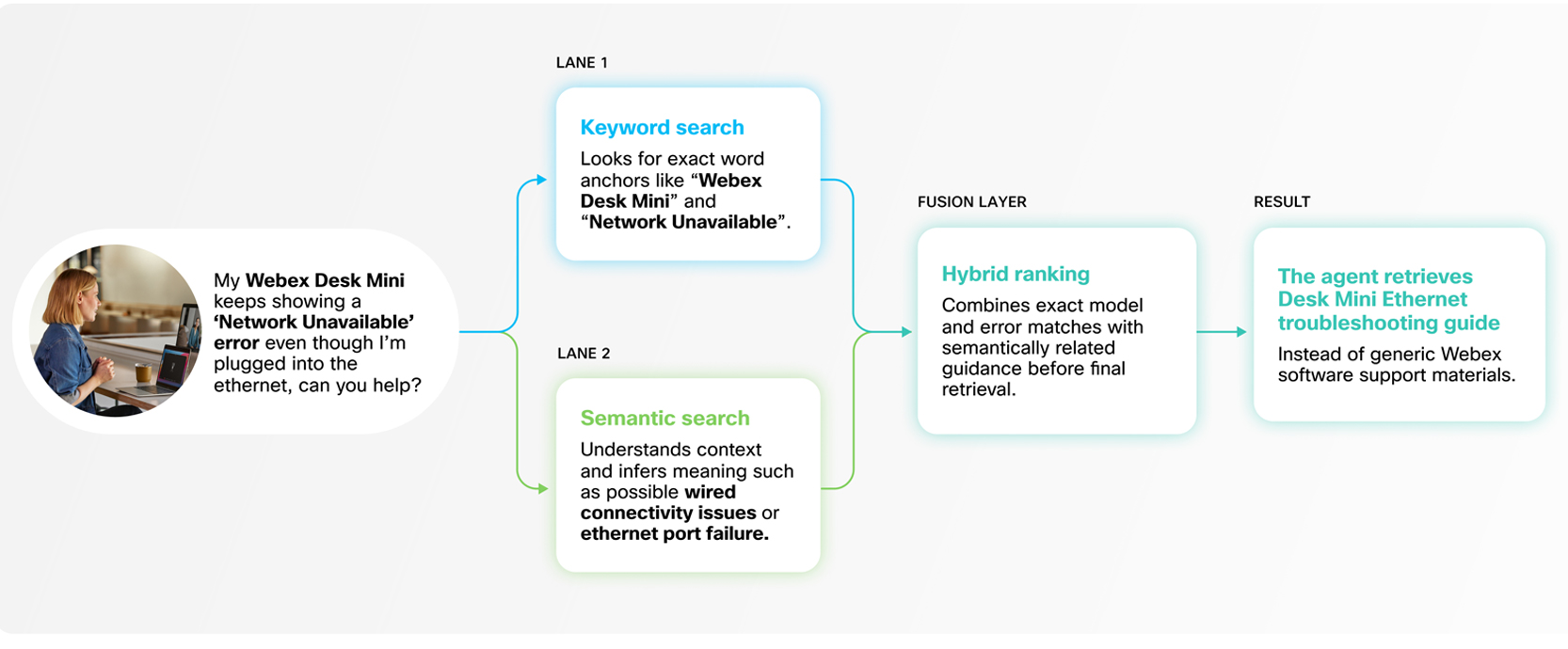
Relying on a single retrieval method can limit accuracy. Pure vector (semantic) search is powerful for understanding intent and meaning, but it can miss exact matches — especially when queries include technical jargon, product codes, or direct quotations. On the other hand, keyword search is highly precise but lacks semantic depth. In production environments, neither approach alone is sufficient.
Webex AI Agent addresses this with a hybrid search strategy that combines both.
Our RAG system integrates keyword and vector search using weight-based balancing, followed by entailment-controlled reranking to refine results. This ensures that exact matches are captured when necessary, while still preserving the contextual understanding required for nuanced queries.
The outcome is comprehensive, high-precision retrieval without added latency. Customers benefit from the best of both approaches — fast, accurate, and contextually relevant answers, every time.
Retrieving based on intent, not just input
Customer queries in real-world conversations are rarely complete or self-contained. They’re often short, ambiguous, or dependent on prior context. When a customer responds with something like “Yes” to “Do you need more information?”, the intent can only be understood by referencing the preceding dialogue. On its own, “Yes” is meaningless to a retrieval system.
To address this, Webex AI Agent includes a purpose-built, lightweight query reframing model. This model reconstructs full, context-rich queries from conversational fragments before retrieval occurs.
Rigorously tested for both high accuracy and ultra-low latency, this approach ensures that our RAG system retrieves information based on true intent — not just surface-level inputs. The result is more relevant answers, smoother interactions, and consistently better customer experiences.
Built for real-time performance
In contact centers, every millisecond counts. High-volume customer interactions demand AI Agents that deliver accurate answers instantly, keeping conversations seamless and customer experiences frictionless. In this environment, low-latency RAG isn’t just a technical optimization — it’s a business requirement.
Webex AI Agent’s RAG system is engineered for real-time performance without sacrificing precision or depth. Our innovations in language-agnostic knowledge processing, adaptive multilingual retrieval, hierarchical chunking, hybrid search, reranking, and standalone query generation are not isolated features — they work together as a unified architecture optimized for speed and reliability.
By solving the hardest challenges in knowledge ingestion, multilingual accuracy, context preservation, and conversational intent, Webex AI Agent sets a new standard for AI-powered customer engagement — delivering consistent, precise, and responsive experiences at scale.
About The Authors




