In April, our team celebrated the long-awaited release of Webex Assistant for Devices in Japanese. Since then, we have seen a steady increase in customer adoption as well as weekly numbers of queries directed at the assistant in Japanese. In our previous post on Internationalization and the Webex Assistant, we explored how internationalization is a challenge that requires a much larger linguistic scope than localizing documents or user interfaces. To date, Japanese has thrown the most challenges our way throughout the internationalization process. Not only was it the first language we attempted that was written in a non-Latin-based script, but it also required a new tokenization strategy, and an overhaul of our entity recognition system.
Perhaps the largest hurdle to launching Japanese was adapting the entity resolution to work with the variety of writing styles and systems that are present in the language. The calling feature is one of the primary functions of the Webex Assistant. In order for it to work correctly, the system needed to be adapted to recognize non-Latin script names. Additionally, it needed to work with different naming conventions and politeness norms that are commonplace in business contexts throughout Japan.
Though this was a challenge, internationalizing the Webex Assistant is still much easier than development from scratch, and flexible initial design decisions and translated data can give development a leg up. The key to our progress resides in our understanding of language structure commonalities and differences, paired with a strong attention to language’s role in society. Overall, these are fun and interesting challenges.
The first challenge we anticipated when adapting Webex Assistant for Japanese was the switch from Latin script to the Japanese writing system. Japanese uses three basic scripts which can be used together throughout a text.
Kanji is a system based on logograms, which are characters that refer to a word or a basic unit of meaning. Originally borrowed from the Chinese writing system, Kanji is commonly used as the preferred script for writing nouns, main verbs, and adjectives, as well as given names. Most Kanji characters can have multiple meanings and are generally disambiguated based on context.
Katakana and Hiragana are both syllabic writing systems called kana, with most characters corresponding to a single syllable. As opposed to an alphabetic system, whose smallest elements are single characters representing consonants and vowels (’a’, ‘b’, ‘c’, …), the smallest elements of syllabic systems are single characters that represent all the possible syllables in the language (’na’, ‘mi’, ‘su’, etc.). Both kana systems in Japanese each contain 46 different characters. Diacritic marks are also used to extend the sets of possible sounds.
Hiragana is generally used to write words that are native to Japanese, including grammatical “glue words”. It is frequently found used as a suffix attached to kanji to express verb forms, or to convert one part of speech into another. Katakana is reserved for words of foreign origin that have been borrowed into the language, as well as for some onomatopoetic sounds (things like “knock-knock”, “bang”, “meow”, “tick tock”).
Recognizing names in any language can be a difficult task. While given (“first”) names and family (“last”) names in English-speaking communities generally form a set that are distinct from other parts of speech (for example, George Clooney, Denzel Washington, Meryl Streep), it is not uncommon for names to lead double lives as other parts of speech (see, for example, Betty White, Drew Barrymore, or River Phoenix). Names also commonly have pronunciations that are not phonetically regular, and which might depend on sound systems present in their language of origin (which is the case for Saoirse Ronan, Idris Elba, or Ralph Fiennes). Naming practices of course vary depending on country and culture, and Japanese naming traditions present their own peculiarities.
Japanese family names are generally written in kanji, and there is an official, restricted list of kanji that are allowed to be used to write them. Because a single kanji can have multiple pronunciations, this means that the same kanji can be used to represent different names that may have completely different pronunciations. For an important set of kanji, Japanese speakers cannot be sure how to read the name unless they have a more specific indication, either verbally, or with an attached transcription using one of the syllabic systems for writing. For example, it’s quite common to see Japanese business cards with a person’s name in kanji, along with a pronunciation guide written in katakana or hiragana.
An additional challenge is that conversely, the same pronunciation for a name can map to completely different kanji that represent different names. The Japanese name that is Romanized to Nakazawa can be written in kanji as either 中沢 or 中澤.
Japanese culture, and work culture in particular, has a heightened awareness of politeness. It is most common to refer to someone using only their family name and an honorific suffix, which indicate the speaker and the addressee’s familiarity or unfamiliarity with each other. The most common honorific marker is -san, which can be used to address women as well as men.
The cultural differences in naming practices have a large effect on the implementation of name recognition, which is central to the People Search portion of the Webex Assistant in Japanese. Whereas the general order of English names generally appears as [Given name] [Family name], Japanese traditions reverse this, preferring [Family name] [Given name]. In an English context, one might drop the family name entirely, preferring to call someone by only their given name. In Japanese, using a person’s given name is very unusual in most contexts. It’s common to not even know a coworkers’ given name. Instead, coworkers are addressed by taking a person’s family name and adding on an honorific particle as a suffix:
| English Context | |
|---|---|
| Given name, Family name | Yoko Ono |
| Given name | Yoko |
| Japanese Context | |
|---|---|
| Family name, Given name | Ono Yoko |
| Family name + ‘san’ | Ono-san |
The Webex Assistant allows users to call anyone by name in their organization using a voice command. They can wake the assistant and say something like “Call Sam Smith” or “I would like to talk to Chloe” and the assistant will place the call.
As described in detail in a previous post about robust NLP for voice commands, when a user addresses a calling command to the assistant, the voice command goes through an Automatic Speech Recognition (ASR) system that analyzes the sound input and outputs a set of likely candidates, ranked by confidence. From those ASR candidates, our Entity Recognizer will detect if there are potential person names in the transcripts offered. “I want to make a call” does not contain a person name or job title entity, whereas “Dial Martine” contains one person name entity, “Martine”.
The most likely entity candidate will then be matched to one or many entries in the directory. The selected directory entries either correspond exactly to the extracted name or have very similar pronunciations to the extracted name. The user is then presented with a carousel of likely matches, ordered based on confidence, which they can page through to select their intended contact.
In a large organization, the name that is being called often corresponds to more than one individual. In these cases, our algorithms will extract the most likely candidates and offer a carousel of choices, ordered from the most likely to the least likely suggestion. The carousel is built based on the name uttered by the user coupled with our knowledge of the user’s network. For example, a user is more likely to contact their direct report than someone in a completely different team.
The user can page through the carousel to select their intended contact. They can confirm their choice either by saying the full name of the person they want to call, or by selecting an option number associated with the desired contact. This works well for English, even if there are some challenges, especially with some names that are uncommon in English.
Grapheme to Phoneme (G2P) models are commonly used to help improve person name recognition. Such models generate plausible pronunciations for names based on their written forms (see Using a Grapheme to Phoneme Model in Cisco’s Webex Assistant for more on this). Especially for names that are not “spelled the way they sound”, this is an important step in the Entity Recognition and People Search processes. In the simplest cases, G2P conversions can be a 1:1 mapping from graphemes (written symbols) to phonemes (the smallest categorical sound units of speech). A simple case would be the name Sam, which can be easily transformed into a G2P representation in the International Phonetic Alphabet (IPA) or Arpabet:
| English Input | IPA | Arpabet |
|---|---|---|
| < sam > | /sæm/ | /S AE M/ |
But generally, G2P transformation is more complicated. For example, in English, other graphemes besides s can represent the “s sound” (represented by s in both IPA and arpabet), and the grapheme s can represent other sounds. Compare the pronunciation of certain and curtain — in the former, the sound c corresponds to is more s-like, in the latter, more k-like:
| English Input | IPA | Arpabet |
|---|---|---|
| < curtain > | /kɜrtən/ | /K ER T AH N/ |
| < certain > | /sɜrtən/ | /S ER T AH N/ |
The grapheme s can also have other pronunciations than the “s sound”, such as in rose with a “z sound” (represented by z in both IPA and arpabet), or in Sean where it corresponds to the sound represented by ʃ in IPA and SH in arpabet.
| English Input | IPA | Arpabet |
|---|---|---|
| < rose > | /roʊz/ | /R OW Z/ |
| < sean > | /ʃɔn/ | / SH AO N/ |
In Japanese, the kana graphemes correspond to phoneme sequences quite consistently (generally one consonant plus one vowel), but the correspondences for kanji are more dependent on context.
Japanese does have some practices in place that help to mediate this potential hurdle. On top of kanji, katakana, and hiragana, Japanese also uses a system called Romaji, which is a set of Latin-script representations of the language. While it is rare to encounter text written like this, using Romaji is the standard input tool for computing systems — configured correctly, a Latin-script keyboard layout can easily use character combinations to type syllables in Japanese. But using only Romaji as an input to a dialogue system has its drawbacks, as doing so tends to simplify the sound patterns of the language. For example, vowel length, which is not marked in English orthography, can be the only difference between two words, and it is not captured in common Romaji representations of the names of people and places:
| Kanji | Standard Romaji | Common Romaji | English |
|---|---|---|---|
| 程 | hodo | hodo | ‘degree, event’ |
| 歩道 | hodou | hodo | ‘sidewalk’ |
| 富士 | Fuji | Fuji | ‘Fuji mountain’ or family name |
| 藤井 | Fujii | Fuji | ‘Fuji’ (family name) |
| 小野 | Ono | Ono | ‘Ono’ (family name) |
| 大野 | Oono | Ono | ‘Ono’ (family name) |
Thus, even though Romaji presents a great starting point for recognition of Japanese names, it cannot be the only tool in our internationalization toolbox.
The G2P approach for name recognition has proven efficient for English, but Japanese offers a new set of challenges. Let us first focus on the prototypical case of a Japanese speaker trying to call a colleague with a Japanese name.
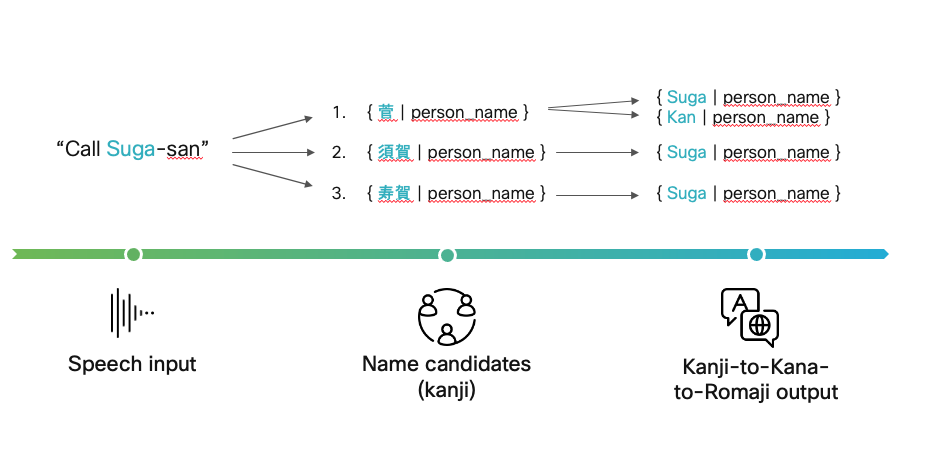
When the user’s command goes through the speech recognition module, the output candidates could be written in any of Japanese’s writing systems. If the name that was uttered is recognized as a potential Japanese name by the speech recognition module, it should come out as one of the first candidates and be written using kanji. There might be other potential candidates in hiragana, in katakana, and even some in the Latin-script romaji.
In our current system, we do not store a user’s audio input. This means the only information we can access is the written transcription of the user’s command that was sent to us by the ASR provider. Given all the information about Japanese names, their writing conventions, and their lack of 1:1 form-to-pronunciation mapping, this can make our task quite difficult. Any given speech input could output many candidate names, and in any of the writing systems:
| Candidates | Writing system | Romaji transcription | English translation |
|---|---|---|---|
| 1. 井出さん | Kanji | Ide-san | Mr. Ide |
| 2. いでさん | Hiragana | Ide-san | Mr. Ide |
| 3. イデさん | Katakana | Ide-san | Mr. Ide |
Currently, most of our organizations’ directories use Latin-script to populate their Given Name and Family Name fields. The difficulty of the task is to match the Kanji that was extracted from the ASR candidates with one of the names in the directory, which are written in Latin-script.
In English, mapping speech to text presents a dimension of ambiguity based on orthography. When the Webex Assistant receives a speech directive, there are multiple completely valid ways of transcribing it, all of which potentially refer to different real-world entities. For a calling scenario, we might be returned a list of possible transcriptions like the following, and our People Search functionality will have to know that all of these names are said in the same way, but spelled differently:
Similarly, the same written name may be pronounced in different ways. A request to call Dr. “Hughart” might be pronounced:
| English Input | IPA | Arpabet | Approximation |
|---|---|---|---|
| 1. Hughart | /hʌghɑɹt/ | /HH AH G HH AA R T/ | “hug heart” |
| 2. Hughart | /hjuɚt/ | /HH Y UW ER T/ | “Hubert” without the ‘B’ |
| 3. Hughart | /juɑɹt/ | /Y UW AA R T/ | “you art” |
In Japanese, the availability of multiple writing systems presents another layer of ambiguity. To account for this, we added a module to People Search that takes the extracted candidates returned from ASR and transliterates them from kanji to kana and from kana to romaji.
In order to match to specific people in the employee directory, each indexed entry now contains a new Aliases field in addition to Family Name, Given Name, and Job Title fields. Aliases can be populated by a list of alternate romaji transliterations and potential matching kanji that could arise when a Japanese name is ambiguous. When People Search looks for a match, it can now search the Family Name and Given Name fields, as well as the Aliases fields for matching entries in any of romaji, kanji, katakana, or hiragana. More weight is given to a match in the Family Name field, followed by Aliases, and finally, Given Name. This weighted search enables Webex Assistant to reliably find the intended person in the directory.
Extending an English-language voice recognition system to other languages poses unique challenges that are not present when internationalizing other types of content. Even when internationalization efforts take time at the beginning of development to outline potential pitfalls that might arise, each new language is really its own entity. Even with the best plan of action, what really counts in effectively internationalizing a product is to be flexible in data development, to be acutely aware of linguistic differences and to work closely with native speakers, while being mindful of the social context that the product will be used in.
Acknowledgement
We would like to extend our special thanks to the Japanese language analysts Masa Ide and Hiroshi Sasaki from Telus International who helped us understand the issues described here.
Kelsey Kraus is a Data Science Analysis Manager on the MindMeld team at Cisco. In her role at Cisco, she helps build and evaluate NLU models, as well as ensure quality interactions with the Webex Assistant. She is fascinated by language in all its forms and is committed to expanding the reach of language technologies past the monolith of English. Her PhD research at UC Santa Cruz on the role of intonation in conversation contributed to a further interest in creating natural interactions with computer systems.
Lucien Carroll is a Software Engineering Technical Leader with the MindMeld team at Cisco. His role encompasses advising the team on methods for data curation and troubleshooting, as well as working out new data development processes. Before joining MindMeld, his PhD work in Linguistics at UC San Diego focused on probabilistic models of language variation, qualitative description of the sound systems of low-resource languages, and statistical modeling of speech acoustics.
Melissa Samson-Fauteux is a Data Analyst Manager with the MindMeld team at Cisco. In the language expansion effort for Webex Assistant, Melissa’s role is to coordinate the data development and data curation for each new language, as well as to ensure the maintenance of the product in all the supported languages. During her Master’s in Linguistics at Université de Montréal, she specialized in Semantics, Lexicology and Formal Lexicography. She has been working in Linguistics and Natural Language Processing for more than 15 years and had the chance to contribute to projects that involve many NLP technologies.
Here at Webex, we are dedicated to keeping people connected for seamless collaboration. In today’s…
This series focuses on SDP, the Session Description Protocol, the method by which almost all…
We’re excited to share that Cisco was recently named a 2024 Customers’ Choice in the…
Cisco is committed to continuously advancing state-of-the-art speech enhancement AI technology, such as Background Noise…
In this hybrid work environment, we strive for work-life balance by making our day more…
Last week, Orlando was teeming with Webex partners, customers, and IT pros from across different…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}