
In our latest blog on real-time conferencing, we’ll share some insights on video.
Central Processing Unit (CPU) costs can be a serious constraint, particularly for real-time compression of video using more modern codecs. Compression of high-resolution, high-framerate video in software on the CPU can be challenging even for reasonably powerful computers and is generally not practical for mobile applications. These codecs are generally amenable to being run on GPUs for systems that have them, but the most common use of encoding and decoding of some codecs is with support built directly into silicon; this is how even relatively low-powered mobile devices can decode and encode HD video at 30fps or better. As such, the widespread adoption of new video codecs is often limited by whether they are supported on-chip by key silicon vendors.
Compression
Raw video requires a huge volume of bandwidth; as previously established a single 1080p30 stream of video would have a bitrate of 1.5 gigabits! As such, video requires very high levels of compression to be feasible.
Image compression, particularly lossy compression, allows for a 10:1 compression with little loss of quality, but even reducing the bandwidth by a factor of 15 would mean a 1080p stream would still require 100Mbps. In practice modern video compression can compress a 1080p30 stream to 4Mbps while maintaining an acceptable level of quality, a compression ratio of 375:1!
The reason for this is that compressed video is not, in fact, a series of compressed images. Instead, real-time compressed video is made up of two kinds of frames. I-frames (Intra-coded frames) are compressed images that can be decoded individually, but they generally make up only a small fraction of the frames in a video stream. These frames are alternatively referred to as keyframes.
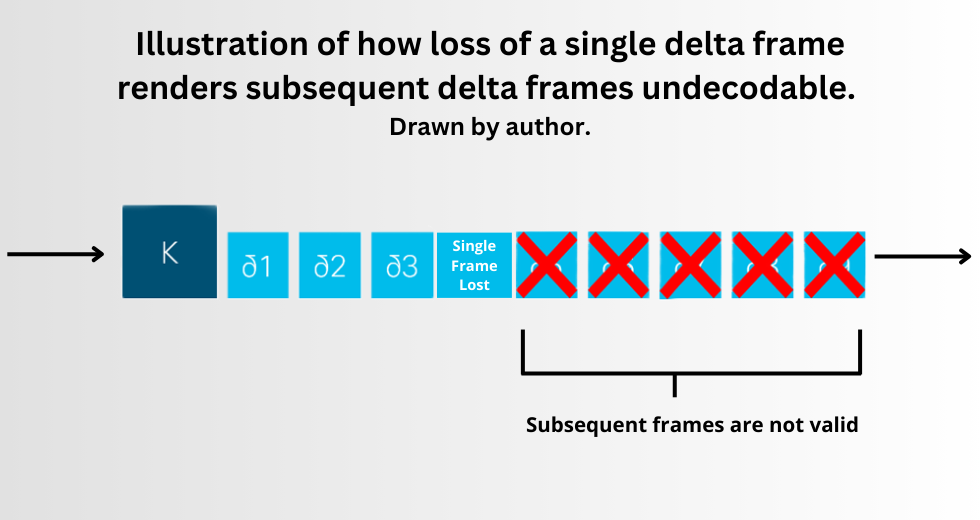
The others are P-frames (Predicted frames), which, rather than encoding an image, hold only changes between the current frame and the previous frame. They are sometimes also called delta frames because they encode the delta between the current and previous frames. In most cases the changes between two frames of video, usually only 33ms apart, are minor, and hence a P-frame can be far smaller than encoding the actual image.
This is how video compression can be so efficient. The downside of this approach is that, in the event of packet loss making a frame undecodable, all subsequent frames are also compromised, as they depend on information in the previous frame. Resolving this generally requires sending a request back to the sender for a new I-frame. In the meantime, a decoder can either freeze the video on the last valid frame or attempt the carry-on by guessing the contents of the missing frame, which can lead to strange visual distortions.
Codecs
The importance of hardware support, combined with the higher level of engineering effort involved in developing a competitive video codec versus an audio codec, helps explain why for over a decade one video codec has dominated across almost every use-case: H.264. Standardized in 2004, H.264 sees ubiquitous hardware support, and widespread use in every video use-case, including real-time conferencing.
H.264 is not the only codec video-conferencing systems may support. Some other codecs that a non-trivial number of real-time conferencing systems support are listed below.
There are older video codecs such as H.261, H.263, and H.263+, which offer lower quality video for a given bitrate at lower CPU cost; there may be a need to support one or more of these for interoperability with very old systems. Systems designed to support or interwork with H.323, an old signaling protocol, may need to implement H.261 for compliance reasons because the signaling protocol mandates its support.
VP8 and VP9 are alternate protocols driven (now) by Google and designed to be patent-free, though there has been debate about whether this would hold up in court. VP8 was designed to be a competitive alternative to H.264, though it has much less flexibility with regard to operating points. VP9 was designed to be superior to H.264 (though not as advanced as H.265 and AV1). While a patent-free video codec would be appealing, lack of hardware support and other major tech companies other than Google endorsing the codecs have meant that their support is limited outside of the browser space, where the dominance of Google’s Chrome has meant they are generally available.
H.265 was designed to be the successor to H.264, but despite being standardized in 2013 its adoption has been much slower in the following decade than H.264’s was. This is primarily not a technical issue but a legal and financial one: H.265 has a much more aggressive and expensive licensing schedule than H.264, making it cost-prohibitive for many use cases where companies cannot afford to pay a licensing fee per download of their product. Some tech companies also believe there is a legal risk to its usage as the patent situation is much more complex; while H.264 has a single patent pool which essentially all patent-holders belong, H.265 has three separate patent pools, and there are some vendors that have not joined any of them. Despite this, it does have some amount of on-chip hardware support, and so may be well suited to specific use cases.
The most promising modern codec is AV1. It has a similar compression ratio and CPU cost to H.265, but, like VP9, it is designed to be patent-free. However, the codec was developed with a much broader base of support across the industry than VP9, meaning a higher level of buy-in as well as greater confidence in its royalty-free status. Adoption of AV1 is still limited, as it was only standardized in 2018, but it seems the most likely candidate for eventually superseding H.264 as support, including on-chip hardware support, is growing.
Exploring the Fundamentals of Audio
Learn the basics of audio and see a comparision of the top 6 audio codecs in Rob’s previous post.

H.264
When encoding video, most codecs divide the frame up into macroblocks, discrete and mostly independent processing units. Codecs can then subdivide these macroblocks further to perform specific transformations or predictions, but that level of detail is beyond this explanation.
Macroblocks & Resolutions
In H.264, macroblocks are blocks of 256 pixels in a 16×16 square (though they can be smaller or subdivided for some internal operations). As a result of this, the width and height of H.264-encoded video in pixels must be a multiple of 16 since the frame boundaries must end on a macroblock’s boundary.
Macroblocks are sufficiently fundamental to H.264 that, when negotiating supported resolutions, the maximum frame size, max-fs, is expressed in total macroblocks, not pixels. Unlike earlier codecs such as H.263, in H.264 there is no need, or ability, for a receiver to express the resolutions or aspect ratios they support. An H.264 receiver simply expresses a singular number of maximum macroblocks per frame and is then supposed to be able to decode and render any valid resolution that contains that many macroblocks or fewer.
The issue with this is that, per the specification, it is legal for the sender to send video in unusual aspect ratios, potentially even extremely unusual aspect ratios such as 5×1. In practice most decoder allocate a surface to decode the video with a maximum height and width, and extreme resolutions may not fit into this surface and will not be decodable. Implementors concerned with interoperability should be wary of sending non-standard resolutions unless there is some other mechanism to signal support for them but should also seek to make their decoder relatively robust to receive a reasonable range of resolutions that they might receive.
In video conferencing television aspect ratios (16:9) tend to be more commonly supported than monitor aspect ratios (16:10). Older codecs were focused on 4:3 resolutions. However, note that modern systems are increasingly supporting a wide range of aspect ratios, including portrait video. Robust support for a wide range of resolutions is particularly important for content or presentation video, which can be shared from a wide range of devices, and preserving the original resolution where possible is particularly important to ensure crisp, readable text.
Interestingly, the common HD resolution 1080p, nominally 1920×1080, is not encodable with standard H.264, as a height of 1080 pixels does not allow for a round number of macroblocks (it is not divisible by 16). As such, H.264 content that is nominally 1080p will be 1920×1072 or 1920×1088. This is important when advertising, sending, and receiving; implementations supporting 1080p should advertise support for up to 1920×1088 and should be able to handle receiving either 1920×1072 or 1920×1088. When sending, implementations must ensure that they do not exceed the far end’s advertised maximum, which may mean sending 1920×1072 rather than 1920×1088 if that is the maximum they have advertised support for).
Note also that some implementations will advertise a max-fs of 8100 macroblocks, which corresponds to a naïve calculation of the macroblocks required for 1080p ( (1920×1080) / (16×16)); while these implementations can actually often handle 1920×1088 that actually exceeds their advertised max-fs value, and they should be sent 1920×1072 for compliance.
Framerates
Similarly, H.264 negotiation does not involve a negotiation of the maximum framerate, but instead the maximum macroblocks per second, max-mbps. As with the aspect ratio issue with max-fs, this does have the property that a sender is within specification to send lower resolutions at higher framerates. For instance, 720p corresponds to (1280×720)/(16×16)=3600 macroblocks, which at 30fps is an mbps of 108000. However, this max-mbps also allows for 720×576 at more than 60fps, or lower resolutions at even higher framerates.
As with the aspect ratio issue, implementations rarely actually support receiving arbitrarily high framerates; implementors concerned with interoperability should avoid sending framerates higher than 30fps unless there is some other mechanism to signal support for them.
Quantization Parameter
Resolution and framerate are not the only variables that affect the bitrate required to send an H.264 stream, the codec can also vary the fidelity, or quality, of the compressed frame itself through the Quantization Parameter, QP. The QP is an index used to derive a scaling matrix; the smaller the QP value, the more steps the encoder takes, and hence the more detail from the original frame is preserved, but the more bitrate is required. A higher QP uses bigger steps and leads to a greater loss of fidelity but can encode the same resolution frame using fewer bits. As such the QP can be considered to control the quality of the encoding – low QP means higher quality, and high QP means lower quality. High QP values lead to frames with visible compression artifacts and look fuzzy, blocky, and otherwise distorted.

As such, when an encoder is targeting a given maximum bitrate, implementations must strike a compromise between the framerate, resolution, and quality. Most implementations will choose to set the framerate and resolution based on the target bitrate, allowing the encoder to pick the best QP to hit the target quality.
However, in circumstances where a large number of keyframes are required (perhaps due to packet loss leading to the far end sending frequent keyframe requests), the encoder may be forced to use a sufficiently high QP to maintain the resolution and framerate that the video will degrade visibility; this can lead to a ‘pulsing’ quality as the encoder can only produce low-quality I-frames and is then able to lower the QP for subsequent delta frames before being forced to raise it again for the next keyframe. Implementations may wish to set a QP ceiling to avoid this effect, dropping frames (and hence lowering the effective framerate) instead to avoid this being too noticeable.
Profiles
Within the H.264 standard, there are a number of optional tools available. Some of them allow for the allocation of additional bits to certain parameters to achieve higher fidelity, but these are rarely used in real-time media encoding. More relevant are toolsets that allow for higher fidelity at a given bitrate, but at a significantly higher CPU cost.
While these tools are of great value in use cases where a video stream will be encoded once and then decoded by a multitude of receivers (such as streaming media or media on disk), the calculation is different in the case of videoconferencing, where encoding must be done in real-time and encoding is will only be decoded by a handful of receivers. In these circumstances, many implementations choose not to support these advanced tools.
Rather than negotiate all these tools separately, H.264 bundles them into profiles, where each predefined profile means supporting a number of these extensions. H.264 in video conferencing is primarily concerned with three profiles:
- Constrained Baseline: The most basic form of H.264, with none of the optional extensions. This is the most commonly supported profile in video conferencing, and implementations concerned with interoperability should always offer H.264 Constrained Baseline support, even if they also offer other profiles.
- Main: This profile adds support primarily for CABAC (Context Adaptive Baseline Arithmetic Coder), which tends to give approximately a 10% decrease in bitrate at a given quality for approximately a 50% increase in CPU cost of encoding. A decent percentage of implementations in video conferencing support Main profile.
- High: As well as the tools in Main this allows for intra-frame prediction across multiple macroblocks, again allowing for a decrease in bitrate at a given quality, though again at an even higher CPU cost. Few implementations in video conferencing support High profile.
There is also a separate Baseline profile that is commonly signaled, but which is effectively equivalent to the Constrained Baseline Profile (CBP). It is primarily signaled for historical reasons; CBP was not defined until after the negotiation of Baseline H.264 was well established in SIP (Session Initiation Protocol) and SDP (Session Description Protocol).
Scalable Video Coding (SVC)
Another extension to H.264 is Scalable Video Coding (SVC). When this extension is used the encoder creates a video stream that also contains one or more substreams, which can be derived by dropping certain packets from the stream. This is valuable in use cases where an encoded stream is being sent to multiple receivers, some of which may have differing receive capabilities – a switching server can then forward all packets to the more capable receivers while discarding one or more layers of the SVC stream to forward one of the substreams to other receivers at a lower bitrate.
SVC encoding allows for three types of substream:
- Temporal: Each sublayer represents a different framerate of the stream. For instance, a 30fps stream might contain a 15fps sublayer by having every other frame be predicted, not from the previous frame, but the one before that. Thus a server could discard the 50% of frames from which nothing is predicted and have a compliant 15fps stream to send to a subset of receivers. This is by far the simplest SVC mode to implement, and so is the best supported in video conferencing.
- Spatial: Each sublayer represents a different resolution of the stream. This is significantly more complex than temporal scalability and is less often supported in video conferencing.
- Quality: Also called Fidelity or SNR (Signal to Noise Ratio) scalability, each sublayer has the same resolution and framerate but at a different quality. This is the least commonly supported form of SVC.
Since SVC is primarily used in circumstances where one source stream is switched to multiple recipients, which is not currently well supported in the widely implemented video-conferencing standards, it is more commonly seen in proprietary video-conferencing solutions.
Note that SVC does reduce the efficiency of the encoding process: for instance, an SVC encoding of a 30fps stream containing a 15fps sublayer will require a marginally higher bitrate to maintain the same quality as a non-SVC encoding of the same stream at 30fps at the same resolution.
Between that and its complexity, some implementations solve the same problem through simulcast: sending multiple independent encodings of the same stream at different resolutions/framerates/qualities to a switching server, which can then forward the most appropriate of these encodings to each receiver. This generally results in a higher upstream bandwidth and encoding cost, but a lower downstream bandwidth for each receiver, as well as avoiding the complexities of supporting SVC.
In the context of multiple substreams, non-SVC H.264 is often referred to as AVC (Advanced Video Coding) to differentiate it, which is part of the official nomenclature of the H.264 codec.
Packetization mode
Finally, when H.264 is sent in RTP (see later blog entries) there is a need to split a given frame up into multiple packets, as unlike audio a video frame will rarely fit within a single RTP packet given the Maximum Transmission Unit (MTU) network limits. H.264 supports multiple packetization modes. These must be configured as part of the encoding, as different packetization modes require the frame to be encoded in specific ways.
H.264 has 3 different packetization modes:
- 0: The simplest mode, where an RTP packet can only contain a single NAL Unit (NALU), which are an internal structure within H.264. The simplest to implement, implementations concerned with interoperability should generally offer support for packetization mode 0.
- 1: This mode allows a NALU to span multiple packets, which generally allows better compression efficiency than mode 0 at a given bitrate. This is the most widely used packetization mode in video conferencing, and it is recommended that implementations ensure they support and negotiate packetization mode 1.
- 2: The most complex mode, this is rarely supported or negotiated in video conferencing using H.264
Licensing of H.264
Despite the impression that may be given by its ubiquity, H.264 is not freely available to implement or use. Instead, companies that hold patents related to H.264 set up a patent pool under a body named MPEG LA that sets the rules and fees for licensing H.264, collects that revenue, and distributes it to its constituents.
While in 2010 MPEG LA did away with licenses for H.264 video sent across the internet that is free for end users (such as YouTube) it still charges for other use-cases, including video conferencing. However, the maximum amount payable annually by a single entity is capped, and since 2013 Cisco has made available a precompiled version of its open-source codec, openh264, which any implementation, including commercial ones, can integrate for free (with Cisco paying MPEG LA the capped amount). This allows for H.264 support in open-source software products such as Firefox, and others that would otherwise struggle to pay the license cost.
Note that to avoid the need to pay the licensing fee themselves implementations using openh264 must follow some specific steps when integrating it to ensure they are doing so in a manner compliant with avoiding needing to pay the licensing fee themselves.
More from Webex:
About The Author




