2020년에 Webex Assistant를 출시한 이래로, 고객에게서 가장 많이 받은 질문은 “이 기능이 과연 정확한가요?”였습니다. 물론 이해합니다. 고객은 Webex AI(인공지능) 자동 텍스트 변환 엔진 사용에 동의할 경우에 미팅의 정확한 기록을 유지하고, 미팅 참가자가 미팅 메모를 입력하는 대신 대화에 집중할 수 있으며, 접근성 기능으로 더욱 포용적인 미팅 환경을 만들 수 있다는 약속이 실제로 지켜질 가능성이 있는지 확실히 알고 싶은 겁니다. 인공지능이 많은 걸 해결할 수 있다고 약속하지만 실제로는 기대에 미치지 못하는 사례가 매우 많습니다. 비즈니스 크리티컬 작업의 경우 Webex는 정확성에 중점을 둘 수 있도록 상당 부분을 향상했습니다. 전 세계가 하이브리드 업무 모델로 전환하게 되면서 사용자가 말하는 언어나 필요로 하는 접근성 기능이 다양해졌고, 바쁜 일상에서 여러 가지 일을 처리하느라 미팅에 불참하고 요약 내용만 확인하기 위해 Webex Assistant에 의존하는 경우도 나타났습니다. 따라서, 이 모든 경우를 포용하는 동등한 회의 환경을 구축하는 과정에서 자막 처리, 텍스트 변환, 작업 항목 캡처 같은 기능이 그 어느 때보다 더 중요해졌습니다. 우리의 목표는 AI와 머신러닝을 활용하여 모든 사용자의 미팅 경험을 한층 더 개선하는 것입니다. 최첨단 AI 텍스트 변환 엔진을 구축하는 일은 이러한 목표를 실현하기 위한 한 가지 방법입니다. Webex에 견고한 엔드 투 엔드 레이블링, 교육, 머신러닝 파이프라인을 구축하기 위해 투자한 것을 고려할 때, 시스코에서는 이러한 토대를 활용하여 현재 출시된 동급 최고의 음성 인식 엔진과 비교해도 손색이 없을만큼 Webex 미팅 경험에 정확성을 갖춘 영어 텍스트 변환 엔진을 출시했다는 데 자부심을 느낍니다. 시스코 기술의 범위를 확장하여 전 세계 Webex 고객의 98% 이상을 지원하기 위해 시스코에서 자체 제작한 스페인어, 프랑스어, 독일어 ASRs(Automatic Speech Recognition engines)를 출시할 예정이며 이 기능은 올해 상반기에 모든 Webex Assistant 사용자에게 무료로 제공됩니다. 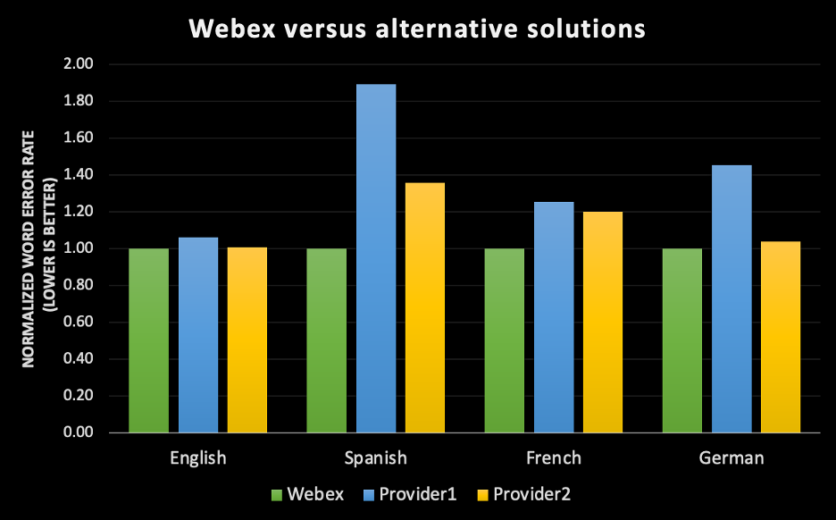


 아래 예시를 참조하세요
아래 예시를 참조하세요 





하지만 “정확하다”라는 건 정말로 어떤 의미일까요?
대화를 정확하게 텍스트로 변환한다는 의미를 생각해보면, 사람이 이 오디오 파일을 들으면서 대화 내용을 기록했을 때 가장 정확한 내용을 반영한다고 생각하는 경우가 많습니다. 그러나 객관적인 관점에서 보았을 때 “CallHome”같은 유명한 데이터셋에서 인적 오류율을 측정해보면 지금까지 보고된 최상의 인적 오류율 결과는 6.8%였습니다. 즉, 100단어를 텍스트로 변환한다고 가정할 경우 그 중 약 7개 단어는 사람에 의해 잘못 변환될 가능성이 있다는 뜻입니다. 게다가 “CallHome”은 영어가 모국어인 화자 간에 이루어진 각본 없는 30분 동안의 전화 대화로 구성된 데이터셋이기 때문에 더욱 언급할 가치가 있습니다. [1] 다양한 영어 억양을 구사하는 화자들로 구성된 데이터셋은 오류율이 더 높을 것으로 예상됩니다. 더욱 흥미로운 점은 LDC(Linguistics Data Consortium)에서 측정한 텍스트 변환자 간의 일치율 범위를 살펴보면, 여러 번의 텍스트 변환을 신중하게 작업할 경우에 4.1%이고 빠르게 작업할 경우에는 9.6%라는 점이었습니다 [2]. 이는 동일한 오디오 파일을 2명에게 줄 경우, 완벽한 환경적 조건에서도 대화 내용을 똑같이 기록할 수 없다는 의미입니다. Webex 텍스트 변환 기능을 지속적으로 개선하는 과정에서 시스코의 목표는 사람이 하는 텍스트 변환과 동등한 수준이 되는 데 그치지 않고 그 수준을 능가하는 것이며 다양한 억양, 성별, 음향 환경 전반에 걸쳐 제공하는 모든 언어에 대해 동급 최고의 정확성을 실현하는 것입니다. 이제 “이 기능이 과연 정확한가요?”라는 질문에 대해 답을 해보겠습니다. 자동 음성 인식에서 정확도의 다각적인 차원을 설명하는 것이 매우 중요합니다.1. 정확도는 단어 오류율(WER, Word Error Rate)이라는 공통 메트릭을 사용하여 측정됩니다
- WER은 기계가 화자가 말한 내용을 얼마나 정확하게 텍스트로 변환했는지 측정합니다.
- 머신러닝(ML) 모델이 텍스트로 변환한 똑같은 오디오가 레이블링 담당자에게 전달되어 텍스트 변환을 위한 정답 값(Ground Truth)을 제공합니다.
- 단어 오류율(WER)은 오류 수를 총 단어 수로 나누어 계산합니다. WER을 계산하려면 우선 인식된 단어의 시퀀스에서 일어나는 치환, 삽입, 삭제를 합산합니다. 정답 값(Ground Truth)에 따라 이 수를 총 단어 수로 나눕니다. 그 결과가 WER입니다. 간단한 공식으로 나타내보면, 단어 오류율 = (치환 + 삽입 + 삭제) / 발화한 단어 수입니다. [3]
- 치환은 한 단어가 다른 단어로 교체될 때 발생합니다(예: “Carl”이라는 텍스트가 “Car”로 변환된 경우).
- 삽입은 말하지 않은 단어가 추가되는 경우입니다(예: “middleware”가 “model where”가 되는 경우).
- 삭제는 텍스트 변환에서 한 단어가 완전히 탈락할 때 일어납니다(예: “come up with”가 “come with”가 되는 경우).
- WER이 낮을수록 텍스트 변환 엔진의 정확도가 좋은 것이며, 이는 오류가 적게 발생한다는 걸 의미합니다.
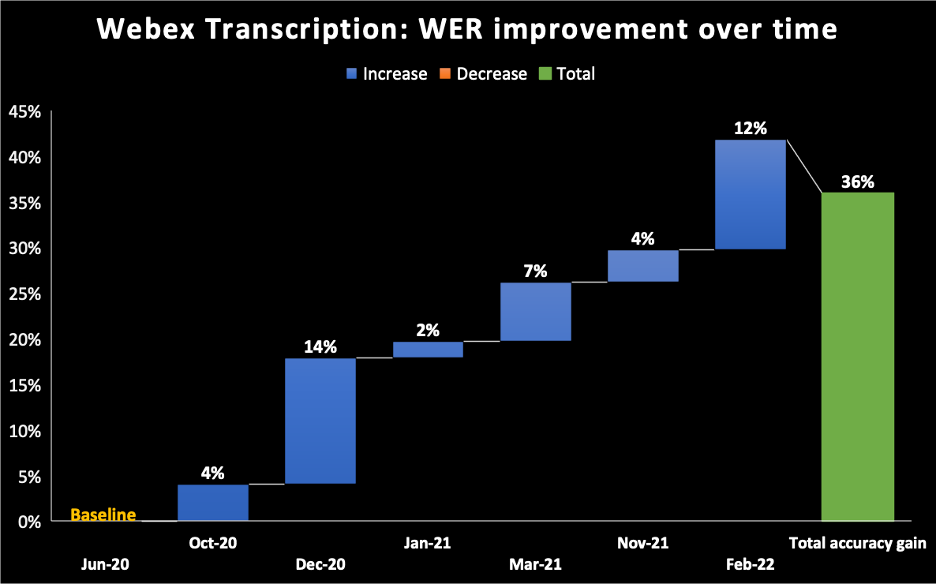
- 아래 차트에서는 Webex Assistant AI 텍스트 변환 엔진에 제공했던 모델의 베이스라인으로 2020년 6월을 선택했습니다. 시간이 지날수록 WER이 계속 개선되어 2022년 2월에는 36%에 도달한 것으로 나와 있습니다.
2. 데이터셋에 의해 전적으로 좌우되는 정확도
- 어떤 음성 인식 엔진도 WER에 대한 절대적인 측정치는 없습니다. 모든 데이터셋에는 방언, 성별, 음향 환경, 분야의 분포와 같은 여러 가지 특성이 포함되어 있습니다. 따라서 오디오 북의 데이터셋을 기준으로 Webex 텍스트 변환 엔진을 실행할 경우, 전화 통화와 상이한 Webex 미팅과는 다른 WER이 측정될 겁니다. 또한 참석자가 외국인 억양으로 말한 Webex 미팅에서 측정을 실행할 경우, 모국어 영어 억양을 지닌 사용자의 Webex 미팅에 대해 똑같은 텍스트 변환 엔진을 실행하면 다른 오류율 결과가 나올 겁니다.
- 동급 최고의 정확도를 실현하기 위해 시스코에서는 오로지 비디오 회의 활용 사례만을 목표로 하고 있습니다. 비디오 회의에서 사람들이 말하는 방식은 전화상으로 말하거나 Alexa에 말하는 방식과 비교했을 때 다른 점이 많습니다. 시스코의 음성 인식 엔진은 이러한 특정 패턴을 수집한 후 이를 비디오 회의에 최적화합니다. 서드파티 공급업체를 이용하는 대신 자체적으로 ASR 엔진을 구축하므로, 시스코에서는 Webex 미팅 경험에 특화된 이러한 특성1에 대해 ML 모델을 훈련시킬 수 있습니다.
3. 미팅을 진행하는 과정에서 개선되는 정확도
- 시스코의 ASR(Automated Speech Recognition)은 미팅의 기간 동안 3가지 종류의 대화 내용을 생성합니다.
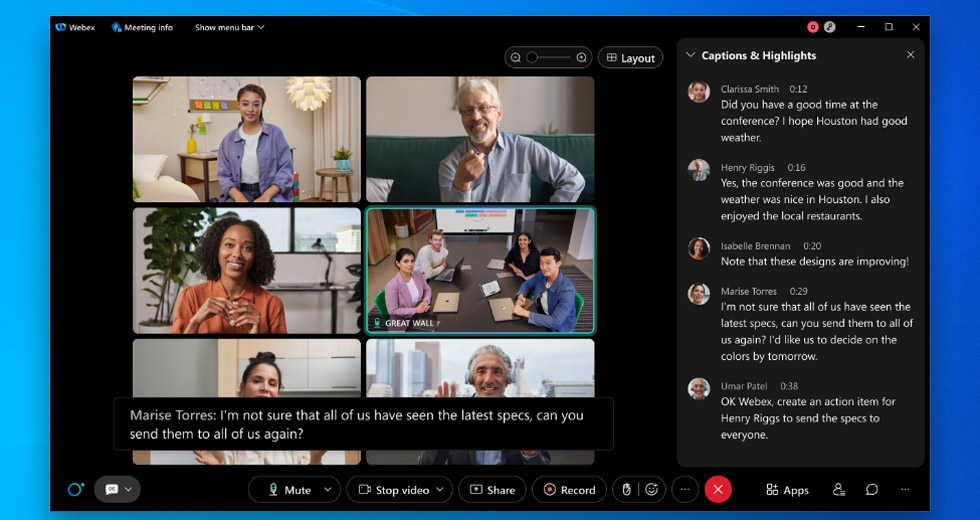
- 초안/중간 발화: 초안 발화는 사용자에게 실시간으로 표시되는 내용입니다. 사용자가 말을 하는 동안 Webex 미팅에서 자막[아래 스크린샷의 검은색 상자]이 보인다면, 1밀리초 동안 텍스트 변환 후에 초안 대화 내용이 생성되며 이것이 바로 사용자에게 표시되는 최초의 대화 내용입니다. 이를 온라인/스트리밍 오디오 텍스트 변환이라고 합니다.
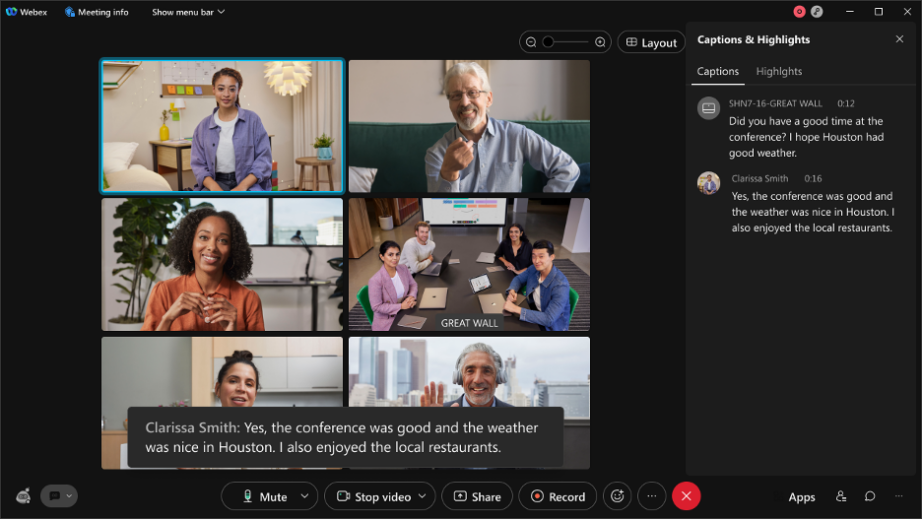
- 최종 발화: 몇 밀리초 이후, 해당 대화 내용에 대해 정확도가 더 높은 또 다른 초안이 생성됩니다. 이 모든 과정이 실시간으로 일어나며 육안으로는 쉽게 구분할 수 없습니다.
아래 예시를 참조하세요 - 이 예시에는 팀 미팅 중 이루어진 발화가 나와 있으며, 한 문장에 초안 발화 13개가 생성되었습니다. 이 모든 과정은 실시간으로 일어나 최종 문장의 정확도를 최상으로 실현하고 실시간 사용자 경험을 최대한 끌어올립니다.
- 개선: 미팅이 종료된 후, 추가적인 텍스트 변환 엔진 집합체를 재실행하여 대화 내용의 정확도를 더욱 개선합니다. 개선된 대화 내용은 미팅의 지속 시간과 상관없이 평균 10분 이내에 제공됩니다. 이 대화 내용이 가장 정확한 버전의 미팅 대화 내용입니다.
4. 텍스트 변환 정확도의 인식에 영향을 미치는 다른 텍스트 변환 문제
- 구두법과 대문자 표시:
- 텍스트 변환이 정확하게 되더라도, 구두점이나 대문자 표시가 정확하지 않을 수 있습니다. 모든 언어에는 고유한 구두법과 대문자 표시 규칙이 있으며, 사용자가 대화 내용을 잘 읽을 수 있으려면 텍스트 변환 모델이 이러한 규칙을 지키도록 훈련시켜야 합니다.
- 구두법과 대문자 표시:

- 발화자의 속성:
- 발화자의 속성은 텍스트의 일부분을 발화자의 것으로 간주하며 미팅 중 발화한 사람이 누구인지 식별합니다. 발화의 특성이 전혀 다른 발화자와 잘못 연결되면 품질 인식이 저하됩니다. 발화자의 속성을 활용하여 미팅 참석자의 발화 시간과 관련된 미팅 분석 같은 흥미로운 기능을 구축할 수 있습니다.
- 약어와 이름 처리:
- 음성 인식 엔진은 일반적으로 통용어에 대한 훈련이 이루어집니다. 여기에는 사람 이름, 회사 약어, 의학 용어 등이 포함되지 않습니다. 예를 들어 “COVID-19”라는 약어는 2020년 전에는 새로운 단어였으며, 이는 미등록 단어이므로 시스코의 ASR에서는 이를 인식하지 못했을 겁니다. 저희 팀은 미팅 중 참석자의 이름을 학습하거나, 컴퓨터 비전을 사용하여 미팅 중 공유되는 프레젠테이션의 약어를 학습하는 등의 방법을 이용해 미등록 단어를 더욱 정확하게 텍스트로 변환할 수 있도록 여러 가지 접근 방식을 시도하고 있습니다.
- 약어와 이름 처리:
- 숫자와 특수 서식 처리:
- 전화번호(+1 203 456 7891), 이메일(someone@email.com), 날짜(2021년 4월 15일)처럼 어떤 숫자에는 특정 서식이 필요합니다. ML 모델은 이러한 특수 서식에 대한 훈련을 통해 발화된 단어를 식별하고 텍스트를 사후 처리하여 올바른 서식으로 표시합니다. 이 모든 작업이 실시간으로 이루어집니다.
- 숫자와 특수 서식 처리:
- 대화 혼선:
- 발화자가 동시에 말하거나 서로의 말을 가로막을 경우, 대화 내용이 정확하다고 해도 읽기 어려운 상태가 될 수 있으며 이는 품질 인식에 영향을 미칩니다. 이 문제를 해결하기 위해 시스코에서는 얼굴 인식과 성문을 활용하여 각각의 발화자를 구분할 수 있는 기능을 구축하고 있습니다.
목표에 도달한 상태일까요?
아직은 아닙니다. 하지만 이 여정은 단거리 경주가 아닌 마라톤입니다. 분야별 데이터에 대한 훈련을 계속 진행하는 동시에 편향을 완화하고 고객의 데이터 개인정보보호와 보안을 유지하기 위해 꾸준히 노력한다면, 시스코에서 자체 개발한 Webex용 AI 텍스트 변환 엔진의 단어 오류율이 사람의 단어 오류율과 거의 같아지거나 나중에는 그 기준을 뛰어넘으리라 생각합니다.
자세히 알아보기 머신 러닝 엔지니어로 Webex에 가입하기: Ritvik Shrivastava와의 인터뷰 포용적 오디오/비디오 AI가 미래의 협업을 지원하는 방법 Webex로 업무 환경 재구성이 기능을 직접 체험해보고 싶다면 오늘 무료 평가판에 등록하세요
About The Author

Mayada Abdelrahman Director of Product Management, AI/ML Cisco
Mayada Abdelrahman, leads product management for Speech AI/ML features designed for Webex including Cisco’s Webex Assistant, the first-of-its-kind enterprise digital meeting assistant.
In this role, Mayada drives the strategy and roadmap for speech AI/ML features for Webex with the goal of transforming the meeting experience and revolutionizing the way we work providing an inclusive meeting experience for everyone.
Prior to joining Cisco, Mayada led product and program management at Voicea, an AI/ML startup that built “Eva” the meeting assistant which was later acquired by Cisco in 2019.
Learn more


