自從我們在 2020 年推出 Webex Assistant 以來,客戶最常提出的問題就是:「它是否準確?」我能理解;客戶想確保如果選用 Webex AI (人工智慧) 自動化轉錄引擎,該引擎能確實協助保存準確的會議記錄,讓會議出席者能專注於對話,而非打字記錄會議筆記,並可透過輔助功能使會議更具包容性。有太多案例顯示人工智慧過度承諾和無法履行承諾,而針對業務關鍵工作,Webex 在確保高準確度上已取得大幅進展。 隨著全球邁向混合工作模式,對於推動平等且具包容性的會議體驗來說,隱藏式輔助字幕、轉錄及擷取動作項目等功能變得比以往都重要,無論使用者的溝通語言為何,可能需要何種輔助功能,或是否選擇略過會議以應付忙碌的生活,並仰賴 Webex Assistant 來回顧會議內容。我們的目標是利用 AI 和機器學習技術,提升所有人的會議體驗。 打造最先進的 AI 轉錄引擎就是達成此目標的方法之一。 有鑑於 Webex 對打造健全的端對端標籤、訓練及機器學習管道的投資,我們很自豪能以此為基礎,推出 Webex 會議體驗的英文轉錄引擎,與市場中某些同級最佳語音辨識引擎相比,我們的引擎具有領先業界的準確度。在我們努力拓展技術以觸及全球超過 98% 的 Webex 客戶時,我們將推出完全由內部研發的西班牙文、法文及德文 ASR (自動語音辨識引擎),這些引擎將在今年上半年免費提供給所有 Webex Assistant 使用者使用。 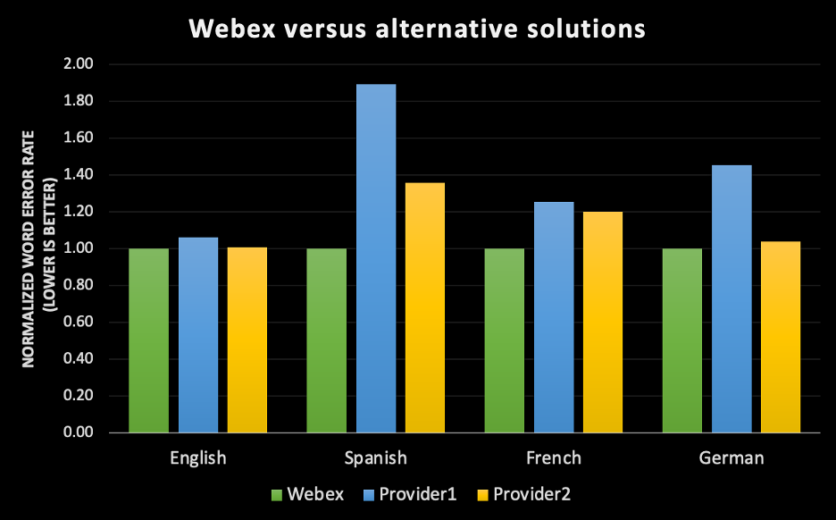

 請見下方範例
請見下方範例 





但「準確度」的真正意義為何?
談到準確的對話轉錄文字,我們經常認為若由人類轉錄員聆聽此音訊檔案的話,轉錄文字就會正確重現語音記錄。但事實上,「CallHome」等某些熱門資料集所測得的人類錯誤率,目前為止最佳表現為 6.8%;這表示如果轉錄 100 個字,則人類轉錄員的轉錄內容大約會有 7 個錯字。此外值得一提的是,「CallHome」是以英文母語人士之間的通話內容 ( 30 分鐘無講稿) 所構成的資料集。[1] 因此我們可以預期若資料集採樣不同英文口音的談話者,其錯誤率將會更高。 更有趣的是,語言資料協會 (LDC) 制定的內部轉錄員協議,其錯誤率範圍介於 4.1% 至 9.6% 之間,視模式為謹慎的多次轉錄,或是快速轉錄而定 [2]。這表示如果您將同一個音訊檔案交給兩個人,即使在完美的環境條件下,他們仍然無法轉錄與話語內容完全相同的記錄。 隨著我們持續改善 Webex 轉錄功能,我們的目標不僅是要達到人類轉錄的準確度,而是要超越此水準,並讓我們每一種語言在各種口音、語法性別及聲音環境下達到同級最佳的準確度。 因此,若要回答「它是否準確?」這個問題,必須先定義自動語音辨識準確度的各種層面:1. 準確度以通用指標「字詞錯誤率」(WER) 為測量標準
- WER 會測量機器轉錄談話內容的表現程度。
- 由機器學習 (ML) 模式轉錄的同一份音訊檔將交給人類標記員,以提供轉錄文字的基準真相。
- 字詞錯誤率 (WER) 的計算方式是以總字數除以錯誤數量得出。若要計算 WER,必須先將一段已識別字詞出現的替換、插入及刪除數量加總計算。然後以基準真相為依據算出總字數,並將總字數除以剛剛得出的數字。最後的結果就是 WER。如果要將上述過程轉換成簡單的公式,字詞錯誤率 = (取代 + 插入 + 刪除)/口語總字數。[3]
- 取代即替換某個字詞 (例如「Carl」被轉錄成「Car」)。
- 插入即新增某個未說出的字詞 (例如「middleware」變成「model where」)。
- 刪除即轉錄文字完全遺漏某個字詞 (例如「come up with」變成「come with」)。
- WER 越低,則轉錄引擎的準確度越高;這代表引擎犯的錯誤越少。
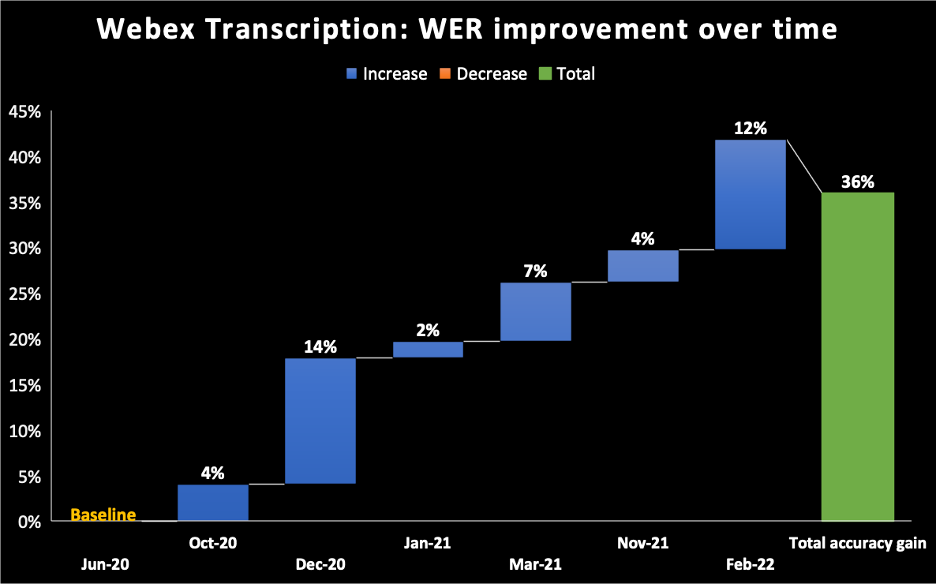
- 在下方的圖表中,我們以 2020 年 6 月作為 Webex Assistant AI 轉錄引擎所推出模式的基準。您可以看到我們隨著時間持續改善 WER,在 2022 年 2 月時累計改善了 36%。
2. 一切視資料集而定
- 所有語音辨識引擎沒有一套絕對的 WER 測量方法。每個資料集都有各種屬性,例如方言、語法性別、聲音環境及區域的分佈。因此,在有聲書的資料集上執行 Webex 轉錄引擎所得出的 WER,將會不同於 Webex 會議和電話通話的 WER。此外,在英文母語口音使用者的 Webex 會議中,以及在會議出席者有不同口音的 Webex 會議中執行相同的轉錄引擎,得出的錯誤率也會不同。
- 為了達到同級最佳準確度,我們的目標只鎖定視訊會議使用案例。人們在視訊會議說話的方式,和在電話中或對 Alexa 說話的方式有諸多不同之處。我們的語音辨識引擎會從中識別特定模式,並針對視訊會議進行最佳化。和使用第三方供應商相比,我們內部打造的 ASR 引擎可讓我們針對 Webex 會議中的特定屬性1訓練機器學習模式。
3. 隨著會議的進行提升準確度
- 我們的自動語音辨識 (ASR) 可在會議期間建立 3 種轉錄文字:
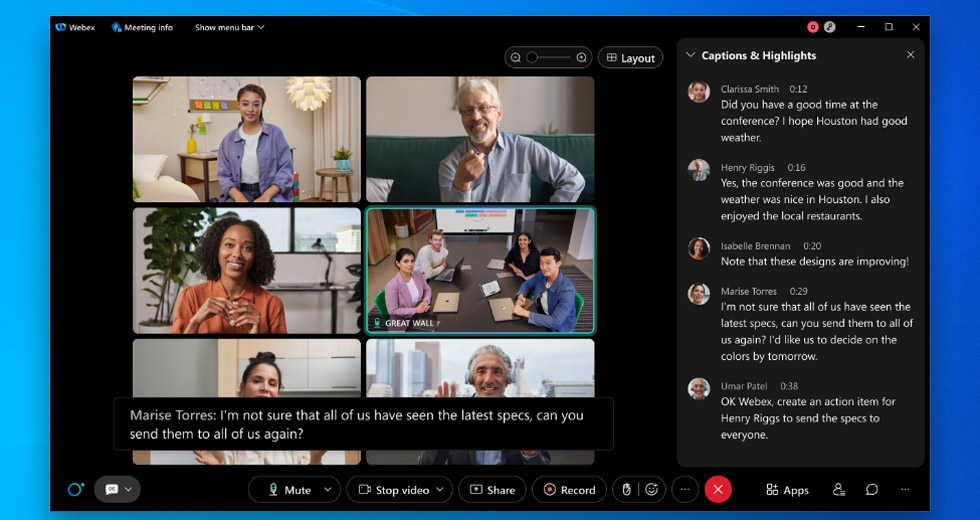
- 草稿/臨時話語:即時顯示的草稿話語。如果您在 Webex 會議中說話並查看隱藏式輔助字幕 [下方螢幕截圖中的黑色方塊],開始轉錄的數毫秒內便會建立轉錄草稿,也是您看見的第一版轉錄文字。我們稱之為線上/串流音訊轉錄。
- 最終話語:數毫秒後,系統將建立另一個更準確的轉錄草稿版本。這一切會即時執行,您無法輕易以肉眼發現變化。
請見下方範例 - 以我們團隊會議中說出的話語為例:系統為這一句話建立了 13 份草稿。這一切會即時執行,讓最終語句達到最高的準確度,並提供最佳的即時使用者體驗。
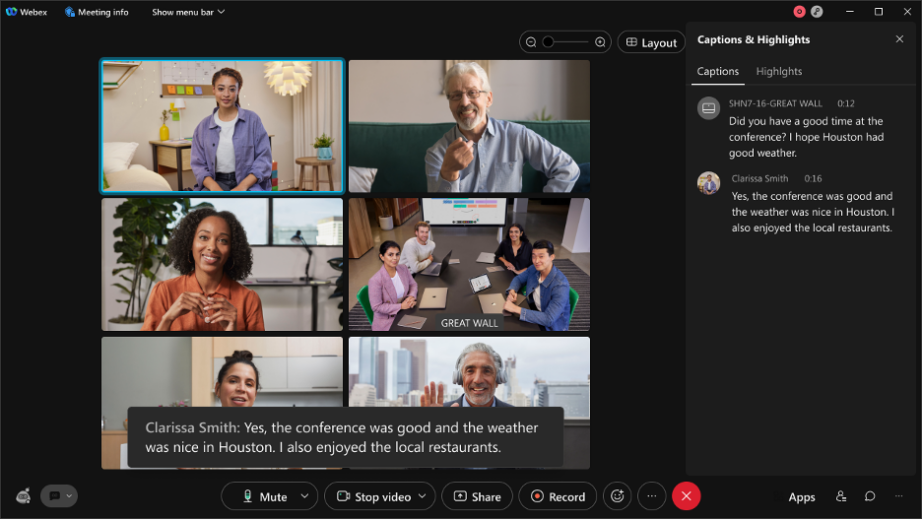
- 增強版:會議結束後,我們會以額外的轉錄引擎重新執行轉錄,進一步提升轉錄文字的準確度。無論會議長度,系統平均 10 分鐘內便能提供增強版轉錄文字。這會是最準確的會議轉錄文字版本。
4. 其他轉錄問題會影響我們對轉錄準確度的認知
- 標點符號與大小寫:
- 即使轉錄內容可能正確,其中的文字可能未準確使用標點符號或大小寫。每一種語言都有各自的標點與大小寫規則,我們必須訓練我們的模式遵守這些規則,讓使用者可輕鬆閱讀轉錄文字。
- 標點符號與大小寫:

- 發言人追蹤:
- 發言人追蹤功能可將一段文字歸納給一位發言人,並識別會議期間誰正在發言。如果一段話語歸納給錯誤的發言人,則會降低品質認知度。發言人追蹤功能可讓我們開發有趣的功能,例如針對會議出席者發言時間所進行的會議分析。
- 處理縮寫與名稱:
- 語音辨識引擎通常會以常見詞彙作為訓練素材。這不包含人名、公司縮寫、醫療術語等等。舉例來說,「COVID-19」這個縮寫是 2020 年才出現的新詞彙,由於它並未列在字彙庫中,我們的 ASR 因此無法識別。我們的團隊採用數種方法來準確轉錄字彙庫中未列出的字詞,例如在會議期間學習出席者姓名,或利用電腦視覺技術從會議中分享的簡報中學習縮寫。
- 處理縮寫與名稱:
- 處理數字與特殊格式:
- 有些數字需要以特殊格式書寫,例如電話號碼 (+1 203 456 7891)、電子郵件 (someone@email.com)、日期 (2021 年 4 月 15 日) 等等。以這些特殊格式訓練的機器學習模式能辨識話語並進行後處理,讓轉錄文字以正確格式顯示。這一切會即時進行。
- 處理數字與特殊格式:
- 語音重疊:
- 當多個發言人同時講話或彼此干擾時,轉錄文字 (即使正確) 可能會無法閱讀,從而影響品質認知。為解決此問題,我們正在開發可利用臉部辨識與聲紋的功能,藉此分辨不同的發言人。
我們成功了嗎?
還沒有。但改善的過程是一場馬拉松,不是賽跑。我們相信持續針對特定區域的資料進行訓練,同時致力於降低誤差並維持客戶的資料隱私與安全性,這個由我們內部為 Webex 開發的 AI 轉錄引擎終將達到人類字詞錯誤率的水準,甚至超越人類表現。
深入瞭解 加入 Webex 成為機器學習工程師:與 Ritvik Shrivastava 的訪談 我們對包容性音訊/視訊 AI 的追求如何促進協作發展 利用 Webex 重新構思工作型態如果您想要親自體驗,請立即註冊免費試用
About The Author

Mayada Abdelrahman Director of Product Management, AI/ML Cisco
Mayada Abdelrahman, leads product management for Speech AI/ML features designed for Webex including Cisco’s Webex Assistant, the first-of-its-kind enterprise digital meeting assistant.
In this role, Mayada drives the strategy and roadmap for speech AI/ML features for Webex with the goal of transforming the meeting experience and revolutionizing the way we work providing an inclusive meeting experience for everyone.
Prior to joining Cisco, Mayada led product and program management at Voicea, an AI/ML startup that built “Eva” the meeting assistant which was later acquired by Cisco in 2019.
Learn more


