Desde que lançamos o Assistente Webex em 2020, a pergunta que mais recebemos de nossos clientes é: “Isto é preciso?” E eu entendo; os clientes querem ter a certeza de que, se optarem por usar o mecanismo de transcrição automática Webex AI (IA – Inteligência Artificial), ele cumprirá sua promessa de manter um registro preciso da reunião, permitirá que as plataformas de reunião se concentrem na conversa ao invés de digitar notas de reunião e tornará as reuniões mais inclusivas através de recursos de acessibilidade. Há tantos exemplos em que a inteligência artificial é muito promissora e pouco divulgada, e para tarefas críticas para os negócios, o Webex deu grandes passos para garantir um foco incansável na precisão. À medida que o mundo se transforma em um modelo de trabalho híbrido, recursos como legendagem, transcrição e captura de itens de ação se tornaram mais importantes do que nunca na condução de experiências de reunião igualitárias e inclusivas, independentemente do idioma que os usuários falam, quais as necessidades de acessibilidade que eles possam ter ou se eles optam por pular uma reunião para lidar com suas vidas ocupadas e se apoiam no Assistente Webex para proporcionar uma recapitulação. Nosso objetivo é aproveitar a IA e o aprendizado de máquina para tornar cada experiência de reunião melhor para todos. Criar os motores de transcrição de IA de ponta é uma forma de atingir esse objetivo. Dado o investimento que o Webex tem feito na criação de sistemas robustos de rotulagem, treinamento e aprendizagem de máquinas, estamos orgulhosos de poder usar esta base para implantar um motor de transcrição em inglês que tem precisão líder na indústria para a experiência do Webex Meetings quando comparado com alguns dos melhores sistemas de reconhecimento de voz do mercado. Em um esforço para expandir o alcance da nossa tecnologia para cobrir mais de 98% dos clientes Webex em todo o mundo, estaremos implantando ASRs (sistemas de reconhecimento automático de fala) em espanhol, francês e alemão, desenvolvidos totalmente de forma interna, que serão oferecidos gratuitamente para todos os usuários do Assistente Webex no primeiro semestre deste ano. 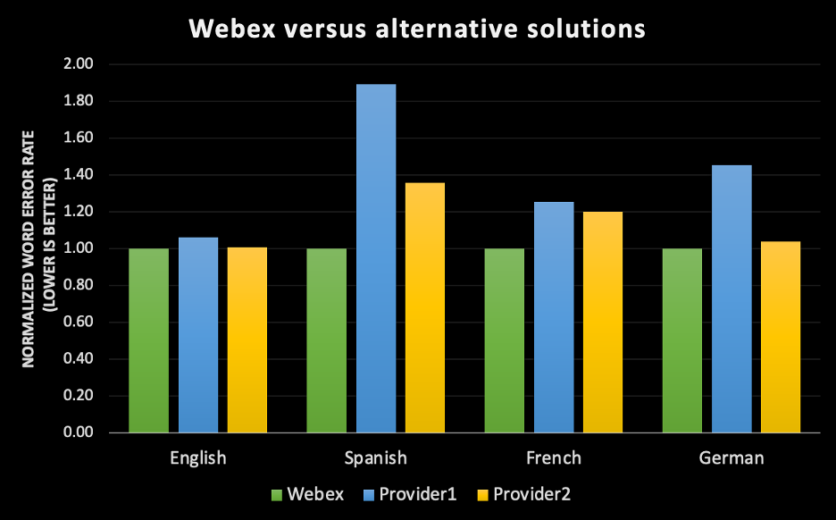


 Veja o exemplo abaixo
Veja o exemplo abaixo 





Mas o que realmente significa “preciso”?
Quando pensamos em uma transcrição precisa de uma conversa, muitas vezes pensamos que, se tivermos um transcritor humano ouvindo este arquivo de áudio, a transcrição irá refletir um registro exato do que foi dito. Entretanto, para colocar as coisas em perspectiva, a taxa de erro humano foi medida em alguns dos conjuntos de dados populares, como “CallHome”, e os melhores resultados relatados até agora é de 6,8% de taxa de erro; ou seja, se você tiver uma transcrição de 100 palavras, aproximadamente 7 delas seriam transcritas de forma imprecisa por um humano. Vale mencionar também que “CallHome” é um conjunto de dados que constitui conversas telefônicas de 30 minutos não escritas entre falantes nativos de inglês. [1] Espera-se que o erro percentual para um conjunto de dados com falantes de diferentes sotaques de inglês seja maior. O que é ainda mais interessante é que a aceitação entre os transcritores, medido pelo Linguistics Data Consortium (LDC), varia entre 4,1% e 9,6%, dependendo de se tratar de transcrições múltiplas cuidadosas versus transcrição rápida [2]. O que isso significa é que, se você der um arquivo de áudio idêntico a duas pessoas, elas ainda não produzirão um registro idêntico do que foi dito, mesmo em perfeitas condições ambientais. Nosso objetivo ao continuarmos a melhorar a transcrição do Webex não é só para estarmos a par da transcrição humana, mas para ultrapassá-la e alcançar a melhor precisão para cada idioma que enviamos em diferentes sotaques, gêneros e ambientes acústicos. Então, para responder à pergunta “isto é preciso?”. É fundamental delinear as diferentes dimensões de precisão no reconhecimento automático da fala:1. A precisão é medida usando uma métrica comum chamada WER (Word Error Rate – taxa de erros de palavras)
- Ela mede o bom desempenho da máquina na transcrição do que foi dito pelos locutores.
- O mesmo áudio que o modelo de aprendizagem da máquina (ML) foi transcrito é dado aos legendadores humanos para estabelecer uma base para a transcrição.
- A taxa de erros de palavras (WER) é calculada dividindo o número de erros pelo número total de palavras. Para calcular a WER, comece somando as substituições, inserções e deleções que ocorrem em uma sequência de palavras reconhecidas. Divida esse número pelo número total de palavras de acordo com a base. O resultado é a WER. Transformando isso em uma fórmula simples, temos: Taxa de erro de palavras = (Substituições + inserções + exclusões) / Número de palavras faladas. [3]
- Uma substituição ocorre quando uma palavra é substituída (por exemplo, “Carl” é transcrito como “Car”).
- Uma inserção ocorre quando se adiciona uma palavra que não foi dita (por exemplo, “middleware” se torna “model where”).
- Uma exclusão acontece quando uma palavra é deixada completamente fora da transcrição (por exemplo, “come up with” se torna “come with”).
- Quanto mais baixa a WER, melhor a precisão do mecanismo de transcrição; isto significa que ele está cometendo menos erros.
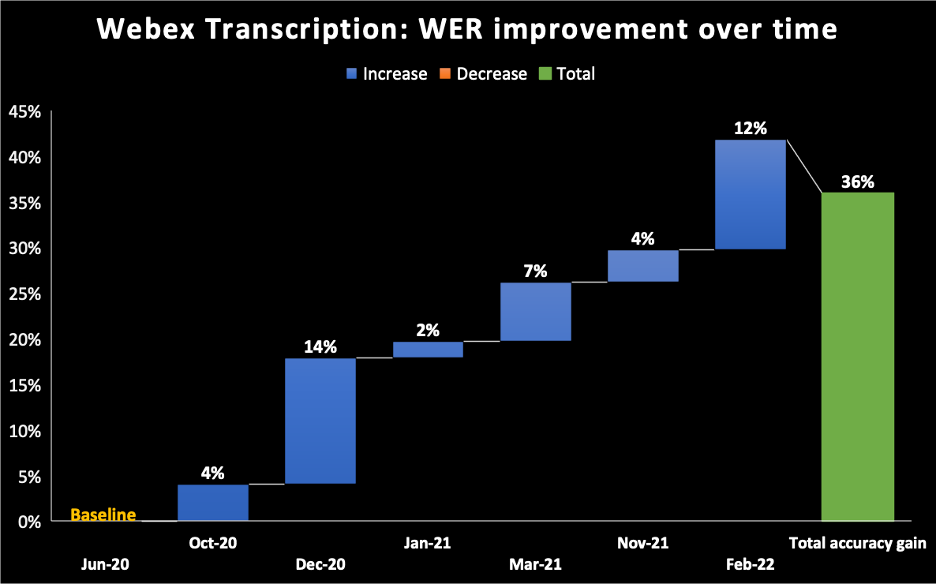
- No gráfico abaixo, tomamos junho de 2020 como base para o modelo que enviamos para o sistema de transcrição IA do Assistente Webex. Você pode ver que ao longo do tempo continuamos melhorando nossa WER, alcançando 36% de melhoria incremental até fevereiro de 2022.
2. Tudo depende do conjunto de dados
- Não há medida absoluta de WER para qualquer mecanismo de reconhecimento de fala. Cada conjunto de dados tem vários atributos, como distribuição de dialetos, gêneros, ambiente acústico e domínios. Assim, rodar o mecanismo de transcrição Webex em um conjunto de dados de audiolivros resultaria na WER que é diferente do Webex Meetings, que seria diferente das chamadas telefônicas. Além disso, rodar o mesmo mecanismo de transcrição em reuniões Webex para usuários com sotaque nativo em inglês resultaria em uma taxa de erro diferente se fosse rodado em uma reunião Webex onde os participantes tivessem um discurso mais acentuado.
- Para alcançar a melhor precisão na classe, estamos focando apenas o caso de uso de videoconferência. Há muitas coisas que são diferentes sobre a maneira como as pessoas falam em videoconferência em comparação com falar por telefone ou com sua Alexa. Nossos mecanismos de reconhecimento de fala captam esses padrões específicos e os tornam ideais para a videoconferência. Criar um mecanismo ASR internamente versus utilizar um fornecedor terceirizado nos permite treinar nossos modelos ML sobre esses atributos específicos para a experiência de reunião Webex.
3. A precisão melhora com o decorrer da reunião
- Nosso Reconhecimento automático de fala (ASR) cria três tipos de transcrições durante o período de duração da reunião:
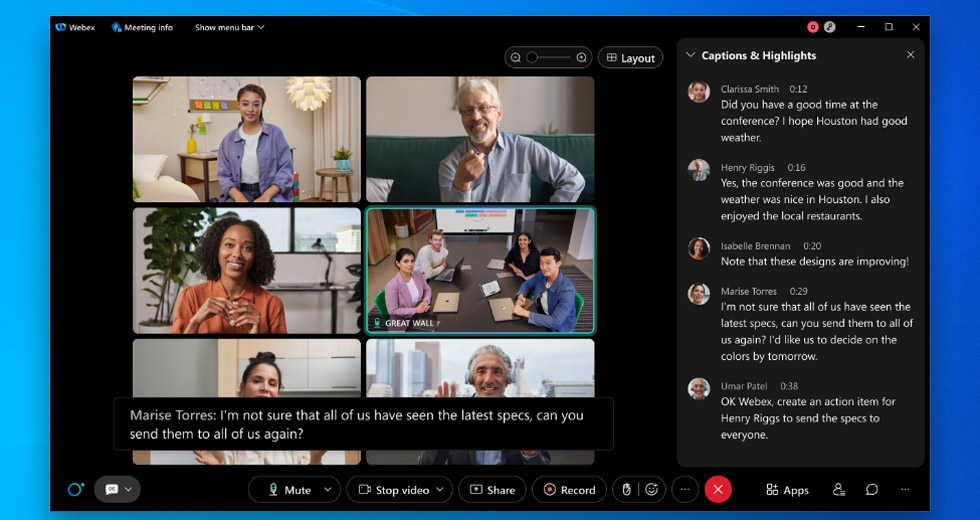
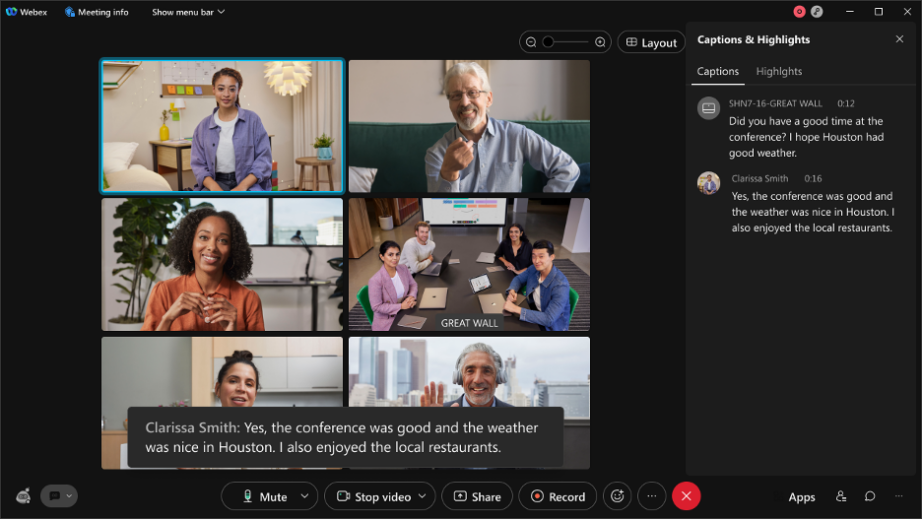
- Discurso de rascunho/provisório: o que você vê em tempo real é o esboço/ínterim do discurso. Se você estiver olhando de perto a legenda em uma reunião Webex [caixa preta na imagem abaixo] enquanto estiver falando, o rascunho da transcrição é criado nos primeiros milissegundos da transcrição e esta é a primeira transcrição que você vê. Chamamos isto de transcrição de áudio on-line/streaming.
- Discurso final: Após alguns milissegundos, é criado outro rascunho da transcrição que tem melhor precisão. Tudo isso está acontecendo em tempo real e não pode ser facilmente distinguido a olho nu.
Veja o exemplo abaixo - Neste exemplo de um discurso proferido em uma de nossas reuniões de equipe: 13 rascunhos foram criados para um discurso. Tudo isso está acontecendo em tempo real para obter a melhor precisão da frase final e a experiência do usuário em tempo real.
- Aprimorado: Após o término da reunião, nós refizemos um conjunto de mecanismos adicionais de transcrição para aumentar ainda mais a precisão da transcrição. As transcrições aprimoradas estão disponíveis dentro de 10 minutos em média, independentemente da duração da reunião. Esta transcrição é a versão mais precisa de uma transcrição de reunião.
4. Outras questões de transcrição impactam a percepção da precisão da transcrição
- Pontuação e uso de maiúsculas e minúsculas:
- Mesmo que a transcrição possa ser precisa, o texto pode não ser pontuado ou seguir o uso de maiúsculas e minúsculas com precisão. Cada idioma tem suas próprias regras de pontuação e uso de maiúsculas e minúsculas, e temos que treinar nossos modelos para respeitar essas funções, para que a transcrição seja bem lida por nossos usuários.
- Pontuação e uso de maiúsculas e minúsculas:

- Atribuição do locutor:
- A atribuição do locutor atribui um trecho de texto a um locutor e identifica quem falou quando durante uma reunião. Se uma afirmação for atribuída ao locutor errado, a percepção da qualidade regride. A atribuição do locutor nos permite criar recursos interessantes, tais como a análise da reunião em torno do tempo de intervenção das plataformas de reunião.
- Manipulação de acrônimos e nomes:
- Os mecanismos de reconhecimento de voz são normalmente treinados em palavras de vocabulário comum. Isso não inclui nomes de pessoas, acrônimos de empresas, jargões médicos… etc. Por exemplo, a sigla “COVID-19” era um novo termo para o mundo antes de 2020 e nosso ASR não teria sido capaz de reconhecê-lo, já que é uma palavra fora do vocabulário. Nossa equipe assume várias abordagens para fornecer uma transcrição mais precisa de palavras fora de vocabulário, tais como aprender os nomes das plataformas de reunião durante uma reunião ou usar a visão computadorizada para aprender acrônimos de uma apresentação que está sendo compartilhada durante uma reunião.
- Manipulação de acrônimos e nomes:
- Manuseio de números e formatos especiais:
- Alguns números precisam de formatação específica, como números de telefone (+1 203 456 7891), e-mails (someone@email.com), datas (15 de abril de 2021) e outros. Os modelos de ML treinados nesses formatos especiais identificam as palavras faladas e processam posteriormente o texto a ser exibido no formato correto. Tudo isso acontece em tempo real.
- Manuseio de números e formatos especiais:
- Falas cruzadas:
- Quando os locutores falam ao mesmo tempo ou se interrompem mutuamente, a transcrição (mesmo quando precisa), pode não ser legível – impactando a percepção de qualidade. Para resolver este problema, estamos construindo recursos que alavancam o reconhecimento facial e a impressão da voz para distinguir diferentes locutores.
Já estamos lá?
Não é bem assim. No entanto, é uma maratona e não um sprint. Acreditamos que, ao continuarmos a treinar sobre dados específicos do domínio enquanto nos esforçamos para mitigar a tendência e manter a privacidade e segurança dos dados de nossos clientes, nosso mecanismo de transcrição de IA desenvolvido internamente para o Webex ficaria ao mesmo nível, se não, excederia a taxa de erro de palavras humanas.
Saiba mais Ingressando no Webex como engenheiro de aprendizado de máquinas: uma entrevista com Ritvik Shrivastava Como nossa busca por áudio/vídeo de IA inclusivo está alimentando o futuro da colaboração Reimagine o trabalho, com o WebexGostaria de experimentar? Inscreva-se em uma avaliação gratuita hoje mesmo
About The Author

Mayada Abdelrahman Director of Product Management, AI/ML Cisco
Mayada Abdelrahman, leads product management for Speech AI/ML features designed for Webex including Cisco’s Webex Assistant, the first-of-its-kind enterprise digital meeting assistant.
In this role, Mayada drives the strategy and roadmap for speech AI/ML features for Webex with the goal of transforming the meeting experience and revolutionizing the way we work providing an inclusive meeting experience for everyone.
Prior to joining Cisco, Mayada led product and program management at Voicea, an AI/ML startup that built “Eva” the meeting assistant which was later acquired by Cisco in 2019.
Learn more


