Desde que lanzamos Webex Assistant en 2020, la pregunta más común que recibimos de nuestros clientes es “¿Es preciso?”. Lo entiendo; los clientes quieren asegurarse de que, si optan por utilizar el motor de transcripción automatizada de IA (inteligencia artificial) de Webex, este cumplirá su promesa de mantener un registro preciso de la reunión, permitir a las plataformas de reuniones centrarse en la conversación en lugar de teclear las notas de la reunión y hacer que las reuniones sean más inclusivas gracias a las características de accesibilidad. Hay muchos ejemplos en los que la inteligencia artificial promete más de la cuenta y no cumple y, en el caso de las tareas críticas para la empresa, Webex ha dado grandes pasos para garantizar un enfoque implacable en la precisión. A medida que el mundo avanza hacia un modelo de trabajo híbrido, las características como el subtitulado, la transcripción y la captura de elementos de acción se han vuelto más importantes que nunca a la hora de impulsar experiencias de reuniones igualitarias e inclusivas, independientemente del idioma que hablen los usuarios, de las necesidades de accesibilidad que puedan tener o de si deciden saltarse una reunión para ocuparse de sus vidas ajetreadas y confiar en Webex Assistant para que les haga un resumen. Nuestro objetivo es aprovechar la IA y el aprendizaje automático para mejorar la experiencia de cada reunión para todos. Crear motores de transcripción de IA de última generación es una forma de lograr ese objetivo. Dada la inversión que Webex ha realizado en la creación de procesos sólidos de etiquetado, entrenamiento y aprendizaje automático de extremo a extremo, estamos orgullosos de poder utilizar esta base para lanzar un motor de transcripción en inglés que tiene una precisión líder en la industria para la experiencia de las reuniones de Webex en comparación con algunos de los mejores motores de reconocimiento de voz del mercado. En un esfuerzo por expandir el alcance de nuestra tecnología para abarcar a más del 98% de los clientes de Webex en todo el mundo, lanzaremos motores de reconocimiento automático del habla en español, francés y alemán, creados íntegramente en la empresa, que se ofrecerán de forma gratuita a todos los usuarios de Webex Assistant en el primer semestre de este año. 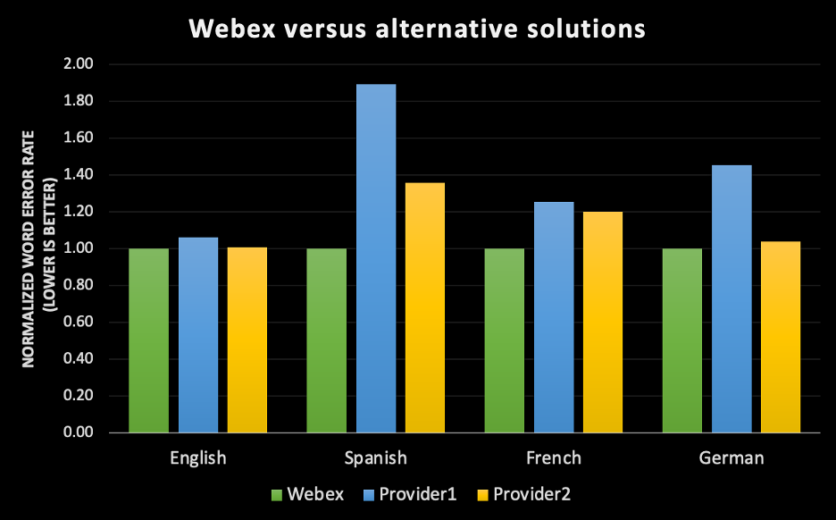


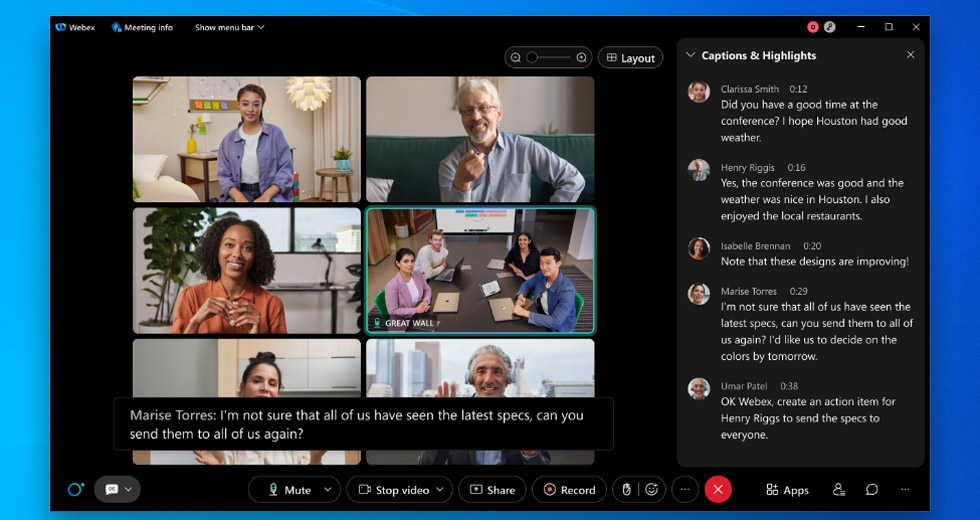
 Vea el ejemplo siguiente:
Vea el ejemplo siguiente: 





Pero ¿qué significa realmente “preciso”?
Cuando pensamos en una transcripción precisa de una conversación, solemos imaginar que, si un transcriptor humano escucha este archivo de audio, la transcripción reflejará un registro exacto de lo que se dijo. Sin embargo, para poner las cosas en perspectiva, se ha medido la tasa de error humano en algunos de los conjuntos de datos más populares, como “CallHome”, y los mejores resultados reportados hasta ahora son un 6,8% de tasa de error, lo que significa que, si se tiene una transcripción de cien palabras, aproximadamente siete de ellas serían transcritas de forma inexacta por un humano. También hay que mencionar que “CallHome” es un conjunto de datos que constituye conversaciones telefónicas de treinta minutos sin guion entre hablantes nativos de inglés. [1] Es de esperar que el porcentaje de error de un conjunto de datos con hablantes de distinto acento inglés sea mayor. Lo que es aún más interesante es que la concordancia entre transcriptores, según las mediciones del Linguistics Data Consortium (LDC), oscila entre el 4,1% y el 9,6%, dependiendo de si se trata de transcripciones múltiples cuidadosas o de transcripciones rápidas [2]. Esto significa que, si se da un archivo de audio idéntico a dos personas, estas no producirán un registro idéntico de lo que se dijo, incluso en condiciones ambientales perfectas. Nuestro objetivo, mientras seguimos mejorando la transcripción de Webex, es no solo estar a la altura de la transcripción humana, sino superarla y lograr la mejor precisión de su clase en todos los idiomas en diferentes acentos, géneros y entornos acústicos. Por lo tanto, para responder a la pregunta “¿es preciso?” es fundamental esbozar las diferentes dimensiones de la precisión en el reconocimiento automático del habla:1. La precisión se mide con una métrica común llamada tasa de error de palabras (WER)
- La WER mide el rendimiento de la máquina en la transcripción de lo que dijeron los oradores.
- El mismo audio que el modelo de aprendizaje automático transcribió se entrega a etiquetadores humanos para que proporcionen datos reales de la transcripción.
- La tasa de error de palabras (WER) se calcula dividiendo el número de errores por el número total de palabras. Para calcular la WER, sume las sustituciones, las inserciones y las supresiones que se producen en una secuencia de palabras reconocidas. Divida ese número por el número total de palabras según los datos reales. El resultado es la WER. Para ponerlo en una fórmula simple: Tasa de error de palabras = (Sustituciones + Inserciones + Supresiones) / Número de palabras habladas. [3]
- Se produce una sustitución cuando se reemplaza una palabra (por ejemplo, “Carl” se transcribe como “Car”).
- Una inserción es cuando se agrega una palabra que no se dijo (por ejemplo, “middleware” se convierte en “model where”).
- Una supresión se produce cuando una palabra queda completamente fuera de la transcripción (por ejemplo, “come up with” se convierte en “come with”).
- Cuanto más baja sea la WER, mejor será la precisión del motor de transcripción; eso significa que comete menos errores.
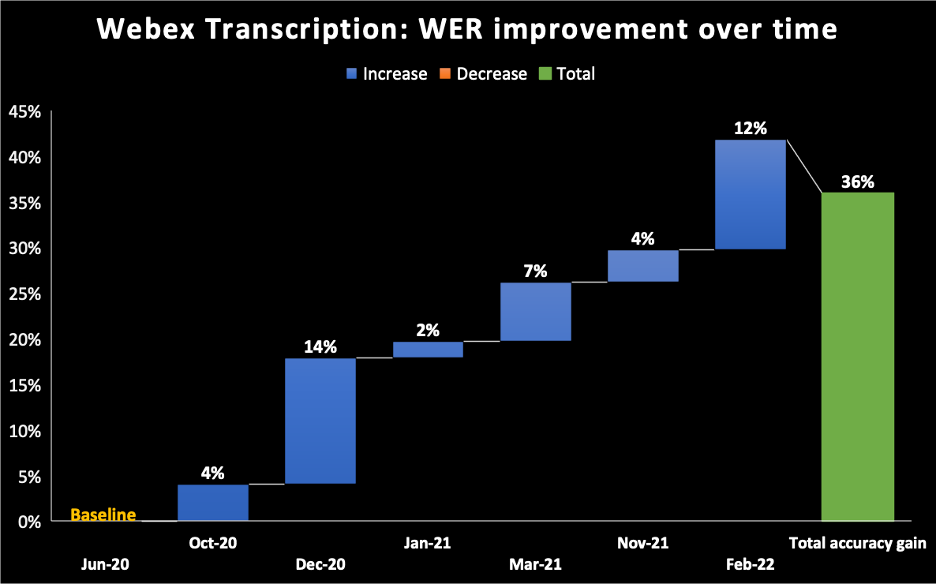
- En el gráfico siguiente, tomamos junio de 2020 como referencia para el modelo que enviamos para el motor de transcripción de IA de Webex Assistant. Se puede ver que, con el tiempo, seguimos mejorando nuestra WER hasta alcanzar una mejora incremental del 36% en febrero de 2022.
2. Todo depende del conjunto de datos
- No existe una medida absoluta de la WER para un determinado motor de reconocimiento del habla. Cada conjunto de datos tiene varios atributos, como la distribución de dialectos, géneros, entorno acústico y dominios. Por lo tanto, si se ejecuta el motor de transcripción de Webex en un conjunto de datos de audiolibros, la WER será diferente a la de las reuniones de Webex, que a su vez será diferente a la de las llamadas telefónicas. Además, si se ejecuta el mismo motor de transcripción en reuniones de Webex para usuarios con acento inglés nativo, la tasa de error sería diferente si se ejecutara en una reunión de Webex en la que los asistentes tuvieran un habla con acento.
- Para conseguir la mejor precisión de su clase, nos centramos únicamente en el caso de uso de las videoconferencias. Hay muchas cuestiones diferentes en la forma de hablar de las personas en las videoconferencias en comparación con la forma de hablar por teléfono o con Alexa. Nuestros motores de reconocimiento del habla captan esos patrones específicos y los optimizan para las videoconferencias. Crear un motor de reconocimiento automático del habla interno en lugar de utilizar un proveedor externo nos permite entrenar a nuestros modelos de aprendizaje automático en esos atributos1 específicos de la experiencia de las reuniones de Webex.
3. La precisión mejora en el transcurso de la reunión
- Nuestro reconocimiento automático del habla (ASR) crea tres tipos de transcripciones durante la reunión:
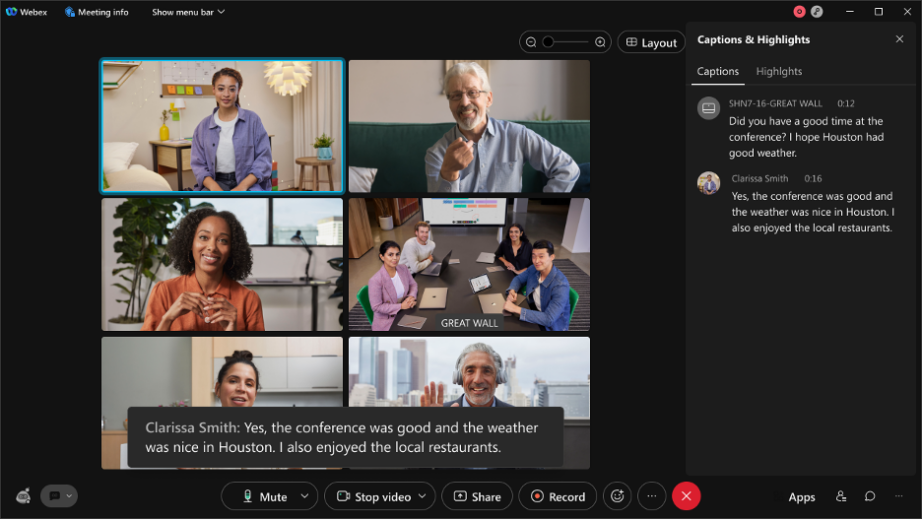
- Borrador de la transcripción: el borrador de la transcripción es lo que se ve en tiempo real. Si está viendo los subtítulos en una reunión de Webex [cuadro negro en la captura de pantalla de abajo] mientras está hablando, el borrador de la transcripción se crea en los primeros milisegundos de la transcripción y esa es la primera transcripción que ve. A esto lo llamamos transcripción de audio en línea/transmisión.
- Transcripción final: después de unos milisegundos, se crea otro borrador de la transcripción que tiene mayor precisión. Todo esto ocurre en tiempo real y no puede distinguirse fácilmente a simple vista.
Vea el ejemplo siguiente: - En este ejemplo, para un enunciado pronunciado en una de nuestras reuniones de equipo, se crearon 13 borradores para una frase. Todo esto sucede en tiempo real para lograr la mejor precisión de la frase final y la experiencia del usuario en tiempo real.
- Transcripción mejorada: una vez finalizada la reunión, volvemos a ejecutar un conjunto de motores de transcripción adicionales para mejorar aún más la precisión de la transcripción. Las transcripciones mejoradas están disponibles en un promedio de diez minutos, independientemente de la duración de la reunión. Esta es la versión más precisa de la transcripción de una reunión.
4. Otros problemas de transcripción influyen en cómo se percibe la precisión de la transcripción
- Puntuación y mayúsculas:
- Aunque la transcripción sea precisa, es posible que el texto no tenga la puntuación o las mayúsculas adecuadas. Cada idioma tiene sus propias reglas de puntuación y uso de mayúsculas, y tenemos que entrenar a nuestros modelos para que respeten esas funciones, de modo que la transcripción se lea bien para nuestros usuarios.
- Puntuación y mayúsculas:

- Atribución de oradores:
- La atribución de oradores asigna un fragmento de texto a un orador e identifica quién habló y cuándo durante una reunión. Si un enunciado se atribuye al orador equivocado, la percepción de la calidad disminuye. La atribución de oradores nos permite crear características interesantes, como el análisis de reuniones en torno al tiempo de habla de los asistentes.
- Manejo de acrónimos y nombres:
- Los motores de reconocimiento de voz suelen estar entrenados para utilizar palabras comunes. Eso no incluye nombres de personas, acrónimos de empresas, jergas médicas, etcétera. Por ejemplo, el acrónimo “COVID-19” era un término nuevo para el mundo antes de 2020 y nuestro reconocimiento automático del habla no habría sido capaz de reconocerlo ya que es una palabra fuera del vocabulario. Nuestro equipo adopta varios enfoques para proporcionar una transcripción más precisa de las palabras fuera del vocabulario, como el aprendizaje de los nombres de las plataformas de reuniones durante una reunión o el uso de la visión por computadora para aprender los acrónimos de una presentación que se está compartiendo durante una reunión.
- Manejo de acrónimos y nombres:
- Manejo de números y formatos especiales:
- Algunos números necesitan un formato específico, como los números de teléfono (+1 203 456 7891), los correos electrónicos (someone@email.com), las fechas (15 de abril de 2021) y otros. Los modelos de aprendizaje automático entrenados en esos formatos especiales identifican las palabras pronunciadas y procesan el texto para que se muestre en el formato correcto. Todo esto ocurre en tiempo real.
- Manejo de números y formatos especiales:
- Superposición:
- Cuando los oradores hablan al mismo tiempo o se interrumpen entre sí, la transcripción (incluso cuando es precisa), puede no ser legible, lo que afecta la percepción de la calidad. Para resolver este problema, estamos creando características que utilizan el reconocimiento facial y la impresión vocal para distinguir a los distintos oradores.
¿Ya llegamos a eso?
Todavía no. Sin embargo, se trata de una maratón, no de una carrera. Creemos que, si continuamos entrenando con datos específicos del dominio, mientras nos esforzamos por mitigar el sesgo y mantener la privacidad y la seguridad de los datos de nuestros clientes, nuestro motor de transcripción de IA desarrollado internamente para Webex llegaría a igualar, si no a superar, la tasa de error de las palabras humanas.
Más información Unirse a Webex como ingeniero de aprendizaje automático: una entrevista con Ritvik Shrivastava Cómo nuestra búsqueda de una IA de audio y vídeo inclusiva está impulsando el futuro de la colaboración Reinventar el trabajo con WebexSi desea experimentarlo usted mismo, inscríbase para obtener una prueba gratuita hoy
About The Author

Mayada Abdelrahman Director of Product Management, AI/ML Cisco
Mayada Abdelrahman, leads product management for Speech AI/ML features designed for Webex including Cisco’s Webex Assistant, the first-of-its-kind enterprise digital meeting assistant.
In this role, Mayada drives the strategy and roadmap for speech AI/ML features for Webex with the goal of transforming the meeting experience and revolutionizing the way we work providing an inclusive meeting experience for everyone.
Prior to joining Cisco, Mayada led product and program management at Voicea, an AI/ML startup that built “Eva” the meeting assistant which was later acquired by Cisco in 2019.
Learn more


