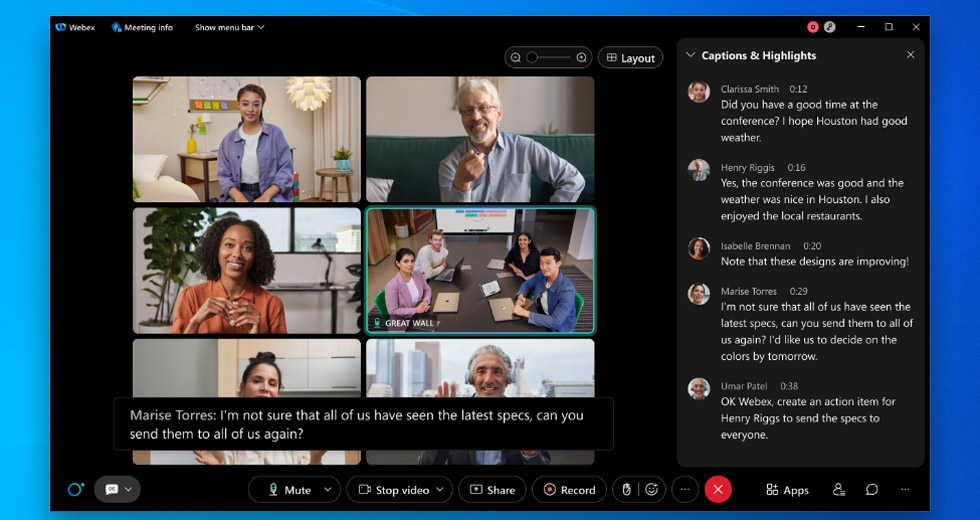
自 2020 年推出 Webex Assistant 以来,我们收到最多的客户疑问是:“它准确吗?”对此,我非常理解。当客户选择 Webex AI(人工智能)自动转录引擎时,客户希望该引擎可以兑现服务承诺,即保持准确的会议记录,帮助与会者专注于对话而不是做会议笔记,以及通过无障碍功能来提高会议包容性。人工智能承诺过多而未能兑现承诺的例子不胜枚举。对此,Webex 采取的行动卓有成效,可以保证对关键业务准确度的持续关注。 随着全球转向混合办公模式,隐藏式字幕、转录、获取待办事项等功能比以往任何时候都更加重要。无论用户使用何种语言,有着什么样的无障碍需求,是否想要跳过会议来平衡忙碌的生活以及使用 Webex Assistant 总结会议内容,他们都需要依靠这些功能来提供平等包容的会议体验。我们旨在利用 AI 和机器学习,为每个人提供更佳的会议体验。 构建最先进的 AI 转录引擎是实现上述目标的方法之一。 Webex 在构建强大的端到端标注、训练和机器学习管道方面投入了很多资源,这为我们推出英语转录引擎奠定了基础。和市场上其他的一流语音识别引擎相比,Webex 的英语转录引擎准确度更胜一筹,可以为您提供更出色的会议体验。对此,我们深感自豪。为将该技术的全球 Webex 客户覆盖率扩大到 98% 以上,我们计划内部开发并推出西班牙语、法语和德语 ASR(自动语音识别引擎),并在今年上半年免费向所有 Webex Assistant 用户提供。 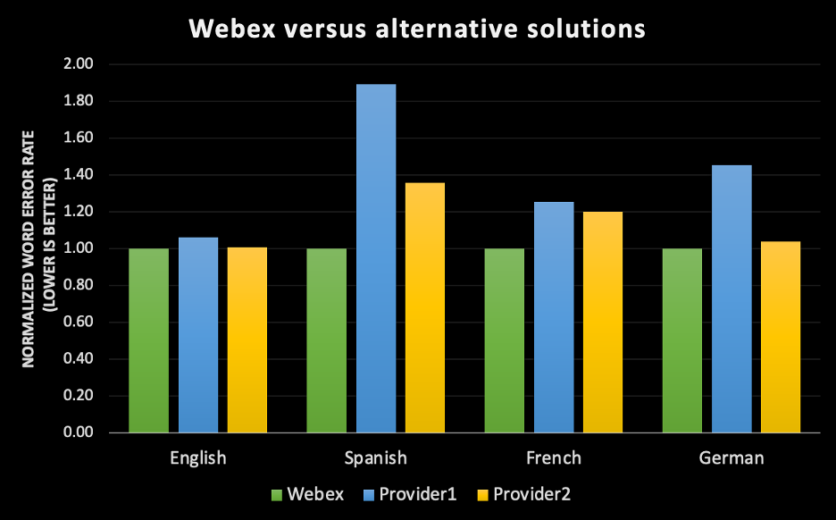


 请查看以下示例
请查看以下示例 





但“准确”的真正含义是什么?
通常,在思考对话转录的准确程度时,我们通常会假设,如果由某个人类转录员来听这个音频文件,我们的对话就可以得到准确的转录。可是,客观地讲,在基于“CallHome”等主流数据集测出的人类错误率中,最佳结果是 6.8% 的错误率,这意味着人类每转录 100 个词,就大约会有 7 个词出错。此外,这里有必要说明一下,“CallHome”是一个数据集,内容是英语母语者的 30 分钟无脚本电话交谈。[1]据估计,如果数据集中说话者的英语口音不同,误差百分比会更高。 更有趣的是,根据语言学数据联盟 (LDC) 的测量,转录员一致性在 4.1% 到 9.6% 之间,具体取决于是仔细的多次转录还是快速转录 [2]。也就是说,如果您给两个人分配了一份相同的音频文件,您也不会得到两份相同的转录。即使是在完美的环境条件下,也如此。 我们会持续优化 Webex 转录质量,使之不仅能够与人工转录相媲美,甚至可以超越人工转录,为每一种语言提供高度准确的转录,而不受口音、性别和声学环境的影响。 所以,现在来回答问题“它准确吗?”列出自动语音识别准确度的不同维度至关重要:1. 基于常用的字错率 (WER) 指标来衡量准确度
- WER 衡量机器对谈话内容的转录质量。
- 将机器学习 (ML) 模型转录的音频交由人类标注员再次转录,以为转录提供事实基础。
- 字错率 (WER) 的计算方法是将出错字数除以总字数。要计算 WER,需要先将识别单词序列中出现的替换、插入和删除加起来。 然后,将得出的字数除以事实基础下的总字数。所得到的结果就是 WER。这可以用简单的公式来表示,字错率 = (替换 + 插入 + 删除) / 说话总字数。[3]
- 替换是指一个词被另一个词替换了,比如,将“Carl” 转录为“Car”。
- 插入是指增加了没有说过的词语,比如,“middleware” 变成“model where”。
- 删除是指转录内容中完全缺少了某个词,比如,“come up with”变成“come with”。
- WER 越低,转录引擎准确度越高;WER 越低,代表错误越少。
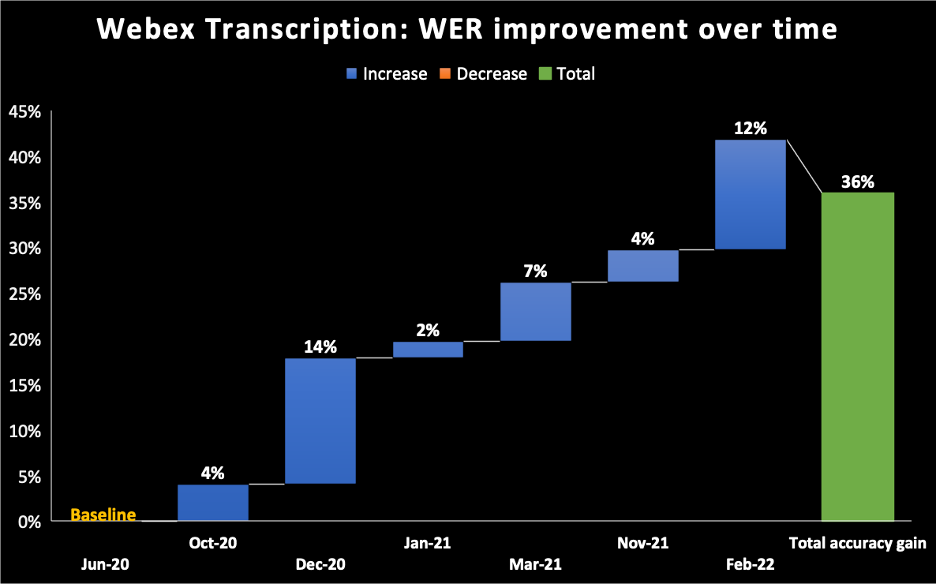
- 在下图中,我们将 2020 年 6 月作为 Webex Assistant 人工智能转录引擎模型的比较基准。可以看到,在过去这段时间,我们的 WER 在持续改善,到 2022 年 2 月,改善率达到 36%。
2. 一切取决于数据集
- 对于任何一个语音识别引擎,都没有绝对的 WER 衡量标准。 每个数据集都会有一些属性,比如方言、性别、声学环境和领域。因此,Webex 转录引擎基于有声读物数据集、Webex 会议数据和电话数据三者所得到的 WER,会各有不同。此外,在 Webex 会议中使用转录引擎时,基于本土英语口音用户的转录结果字错率,与基于与会者有口音的发言的转录结果字错率也会有所不同。
- 为了达到一流的准确率,我们只面向视频会议用例。人在视频会议中的说话方式,与打电话或和 Alexa 讲话都大有不同。我们的语音识别引擎可以捕捉到这些特定模式,使它们成为视频会议的最佳选择。与使用第三方供应商的引擎相比,内部开发 ASR 引擎使我们可以基于 Webex 会议体验的特定属性1 来训练 ML 模型。
3. 准确度在会议过程中有所提高
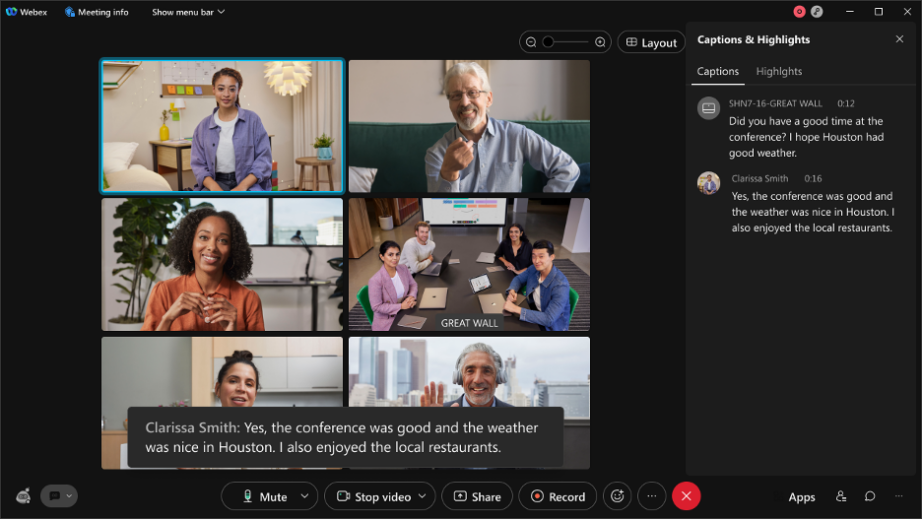
- 会议期间,我们的自动语音识别 (ASR) 会创建 3 个转录:
- 草拟/临时发言:草拟发言是指您实时看到的内容。如果您在发言时,启用了 Webex 会议的隐藏式字幕功能 [下方截图的黑框],您会在开始转录的几毫秒内看到第一份转录草稿。我们称之为在线/流媒体音频转录。
- 发言终稿:几毫秒后,会生成一份准确度更高的转录草稿。这是一个实时过程,肉眼难以分辨。
请查看以下示例 - 在这个示例中,针对我们团队在会议上的一句发言,自动语音识别创建了 13 份草稿。这是一个实时过程,旨在最准确转录最终发言,提供出色的实时用户体验。
- 优化:会议结束后,我们会重新运行一组另外的转录引擎,以提高转录稿的准确度。无论会议时长多久,转录优化稿平均在 10 分钟内生成。转录优化稿是最准确的一份会议转录稿。
4. 其他影响转录质量感知的转录问题
- 标点符号和大小写字母:
- 即使转录正确,但文本的标点符号或大小写字母也可能会不准确。每一种语言都有自己的标点符号和大小写规则,我们需要训练模型学会这些规则,使转录结果符合用户的阅读习惯。
- 标点符号和大小写字母:

- 发言人归属:
- 发言人归属是指将某段文本归属于某位发言人,并确定会议期间的发言人。如果发言人归属出现错误,质量感知能力就会下降。通过发言人归属,我们可以开发一些有趣的功能,比如关于与会人员发言时间的会议分析。
- 处理缩略词和名字:
- 通常,语音识别引擎是使用常规词汇来训练的。这不包括人名、公司缩写、医学术语等。例如,2020 年之前,缩略词“COVID-19”尚未面世,我们的 ASR 自然也无法识别出这个超纲词汇。针对超纲词汇,我们团队采取了几种方法来提供更准确的转录结果,比如,在会议期间学习与会人员名字、使用计算机视觉学习会议期间共享的演示文稿中的首字母缩略词。
- 处理缩略词和名字:
- 处理数字和特殊格式:
- 有些数字需要特定格式,如电话号码 (+1 203 456 7891)、邮箱 (someone@email.com)、日期(2021 年 4 月 15 日)等。基于这些特殊格式来训练的 ML 模型可以识别出发言内容,并在后台处理文本,以便以正确格式呈现文本。这是一个实时过程。
- 处理数字和特殊格式:
- 串音:
- 当多名发言人在同一时间讲话或发言人被对方打断讲话时,即使转录准确,文本也可能会令人费解,从而影响质量感知。为解决这个问题,我们在开发一些功能,利用人脸识别和声纹来区分不同的发言者。
我们成功了吗?
还没有。但是,这条路会很漫长,不能一蹴而就。我们深信,只要持续基于特定领域的数据来训练引擎,同时减少偏见和保护客户的数据隐私和安全,我们内部为 Webex 开发的人工智能转录引擎一定能达到与人工转录相近的字错率,甚至可以低于人工转录的字错率。
阅读更多文章 加入 Webex 担任机器学习工程师:访谈 Ritvik Shrivastava 我们对包容性音频/视频人工智能技术的不懈追求将如何赋能未来的协作 Webex 助力重塑办公体验如果您想要亲自体验一下,欢迎马上注册,参加免费试用
About The Author

Mayada Abdelrahman Director of Product Management, AI/ML Cisco
Mayada Abdelrahman, leads product management for Speech AI/ML features designed for Webex including Cisco’s Webex Assistant, the first-of-its-kind enterprise digital meeting assistant.
In this role, Mayada drives the strategy and roadmap for speech AI/ML features for Webex with the goal of transforming the meeting experience and revolutionizing the way we work providing an inclusive meeting experience for everyone.
Prior to joining Cisco, Mayada led product and program management at Voicea, an AI/ML startup that built “Eva” the meeting assistant which was later acquired by Cisco in 2019.
Learn more


