
前言
「自動語音辨識」(ASR) 系統會提供文字轉錄。這多半是一系列的文字。思科會使用 ASR 系統,在 Webex Meetings 中提供即時隱藏式輔助字幕。這個系統會出的問題其中之一,是難以閱讀缺少標點符號與大小寫的字幕。對文字意義的瞭解會受到標點符號的影響。以下提供一組文字,並提供兩種標點符號選項:「thank you your donation just helped someone get a job」
選項 A:「Thank you! Your donation just helped someone get a job.」(感謝您!您的貢獻讓某人能完成工作。)
選項 B:「Thank you! Your donation just helped someone. Get a job.」(感謝您!您的貢獻協助了某人。去找份工作吧。)
不過是一個標點符號,就讓整句的意思相差十萬八千里。
因此,我們要討論建構後期處理系統時的幾項考量:- 恢復原始文字的標點符號與大小寫的高精準度模型。針對臨時結果進行快速推論:趕上即時字幕。
- 使用少許資源:語音辨識屬與運算密集的技術,因此標點符號模式的運算量不需要如此密集。
- 有能力處理未列在字彙庫中的文字:有時,系統必須針對模型前所未見的文字加上標點符號或大小寫。
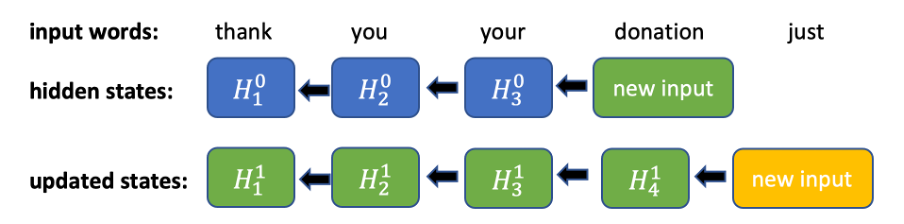
圖 1. 針對雙向 RNN 的反向推算所進行的運算。每次出現新的輸入時,所有之前隱藏的狀態都必須依序更新。
TruncBiRNN
直覺與實踐顯示,在建構標點符號模型時,對未來情境的瞭解必是不可或缺的,因為在不知道接下來文字內容的狀況下,會更難判斷將標點符號放置在哪個位置。為了使用關於接下來權杖的資訊,且不會被迫反向更新運算中所有權杖的隱藏狀況,我們決定截斷反向運算至固定視窗中。在順向運算中,只是一般的 RNN。在反向運算中,我們只會考量每個權杖的固定視窗,並在此視窗中執行 RNN(圖 2)。透過使用這個視窗,我們可以針對新的輸入權杖達成常數時間推論(我們需要在順向運算一個隱藏狀態,並在反向運算中運算 n+1 個隱藏狀態)。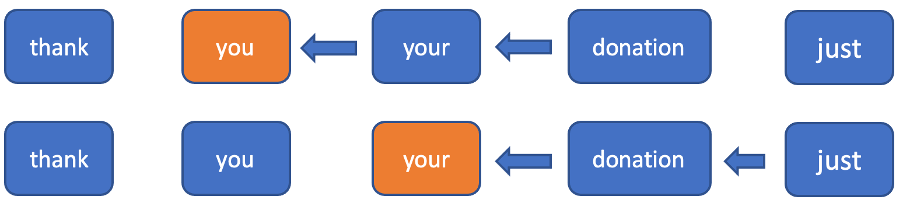
圖 2. 在這個範例中,針對每個現有權杖,只會考慮在反向式運算中運算接下來兩個隱藏狀態。
架構
整個架構包括嵌入層、TruncBiGRU 與單向 GRU 層,以及完整連線層。針對輸出的標點符號與大小寫,我們分別使用兩個 softmax 層(圖 3)。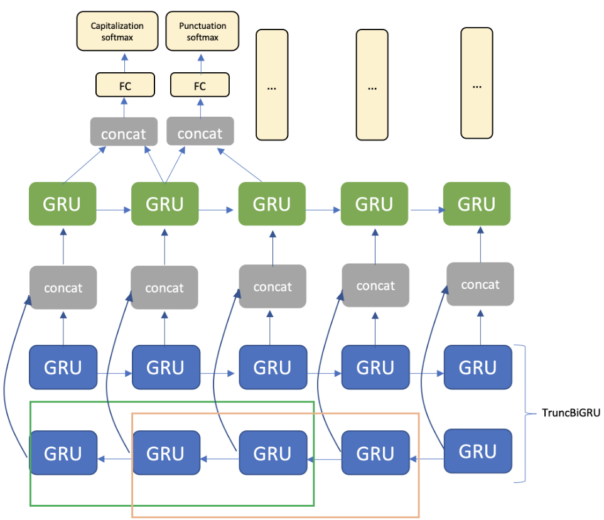
圖 3. 視窗大小與 TruncBiGRU 兩個權杖相等的模式架構。
period – 在句子中間出現句點,並不絕對表示下一個字必須大寫(「a.m.」、「D.C.」等)
comma
question mark
ellipsis
colons
dash
terminal period – 句子結尾的句點
至於大小寫,我們有四個類別:lower
upper – 所有字母都大寫(「IEEE」、「NASA」等)
capitalized
mix_case – 針對像「iPhone」這樣的詞彙
leading capitalized – 每個句子的第一個字
多出的兩個類別「leading capitalized」與「terminal period」,初見時看起來很累贅,但這兩個類別可以提高與大小寫和標點符號相關答案的一致性。「terminal period」意指下個大小寫答案就不能是「lower」,而出現「leading capitalized」則表示前一個標點符號是「terminal period」或問號。這些類別在損失函數中扮演相當重要的角色。損失函數:我們需要同時將大小寫與標點符號的使用狀況最佳化。為了達成這個目標,我們使用一組對數損失 (log loss) 函數,並搭配一個係數: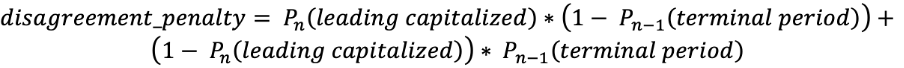 第一項是與在非「terminal period 」後出現「leading capitalized」的可能性相關,第二項則是與在「terminal period」後不會出現「leading capitalized」的可能性相關。 這個懲罰項能總結發生錯誤的權杖。此外,我們也會將前兩層的連續張量傳送到 softmax 層,才能有效降低懲罰項。最後,我們就得出了這個損失函數:
第一項是與在非「terminal period 」後出現「leading capitalized」的可能性相關,第二項則是與在「terminal period」後不會出現「leading capitalized」的可能性相關。 這個懲罰項能總結發生錯誤的權杖。此外,我們也會將前兩層的連續張量傳送到 softmax 層,才能有效降低懲罰項。最後,我們就得出了這個損失函數: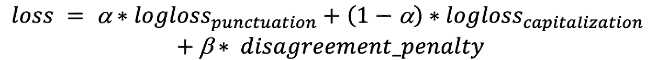
訓練
訓練時,我們會從內部 Webex Meetings 中選取一組轉錄文字,並從維基百科 (Wikipedia) 擷取文字資料使用。首先,我們會清除訓練資料,並分割為好幾個句子。訓練期間,每個樣本都是從連續句子產生,並經由固定散佈來截短成長度不定的短句。這能在訓練期間讓模型看到切割的片語,使模型能夠處理推論期間產生的臨時結果。接著,我們會使用約 300 MB 的維基百科文字來訓練模型,接著在 Webex Meeting 轉錄文字中進行微調。使用維基百科進行前期訓練能協助改善所有標點符號類別,不過對大小寫類別的訓練成效更為顯著。我們猜測這可能是因為在維基百科的文集中使用大量的代名詞。我們會將句子連接起來,然後隨機截短成不同長度,以便在我們的評估組上套用相同的資料準備程序。這讓我們能針對臨時轉錄文字狀態中可能看到的結果,評量其精準度。結論
使用相對簡單的技術,搭配針對架構進行的一些自訂,例如截短 GRU 與在損失函數中使用額外的懲罰項,我們才能建構一個可以在線上執行的模型。有了即時標點符號與大小寫功能後,就能大幅提升即時字幕的閱讀體驗。參考資料 [1] A. Gravano, M. Jansche, and M. Bacchiani, “Restoring punctuation and capitalization in transcribed speech,” in ICASSP 2009, 2009, pp. 4741–4744. [2] Monica Sunkara, Srikanth Ronanki, Kalpit Dixit, Sravan Bodapati, Katrin Kirchhoff, “Robust Prediction of Punctuation and Truecasing for Medical ASR” [3] Tilk, Ottokar & Alumäe, Tanel. (2016). Bidirectional Recurrent Neural Network with Attention Mechanism for Punctuation Restoration. 3047-3051. 10.21437/Interspeech.2016-1517. [4] Vardaan Pahuja, Anirban Laha, Shachar Mirkin, Vikas Raykar, Lili Kotlerman, Guy Lev “Joint Learning of Correlated Sequence Labelling Tasks Using Bidirectional Recurrent Neural Networks” [5] Wang, Peilu & Qian, Yao & Soong, Frank & He, Lei & Zhao, Hai. (2015). Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Recurrent Neural Network. [6] Lita, Lucian & Ittycheriah, Abe & Roukos, Salim & Kambhatla, Nanda. (2003). tRuEcasIng. 10.3115/1075096.1075116. [7] https://github.com/google/sentencepiece 請登入 Webex 請造訪我們的首頁或直接聯絡我們以獲得協助。請按一下這裡進一步瞭解 Webex 系列產品,並可註冊取得免費帳戶About The Author

Pavel Pekichev Machine Learning Scientist Cisco
Pavel Pekichev is a Machine Learning Scientist at Cisco working on speech recognition systems.
Learn more
