
This is a companion blog post to my talk at the REWORK conference on April 28th, 2021. The talk slides are available here.
Natural language understanding (NLU) is a key component in any conversational AI system. Typically, in a task-oriented dialogue system, the NLU consists of classifiers to identify the user’s intent and the slots or entities present. The dialog manager uses this output to select the appropriate dialog state and take the corresponding actions to saftisfy the user’s request. In some cases, it may not be possible to clearly define an intent, or simply knowing the intent and entities present in the user request may not provide enough information for the dialog manager to take the optimal action. For example, consider the following interaction of a user with a bot for a retail clothing website:
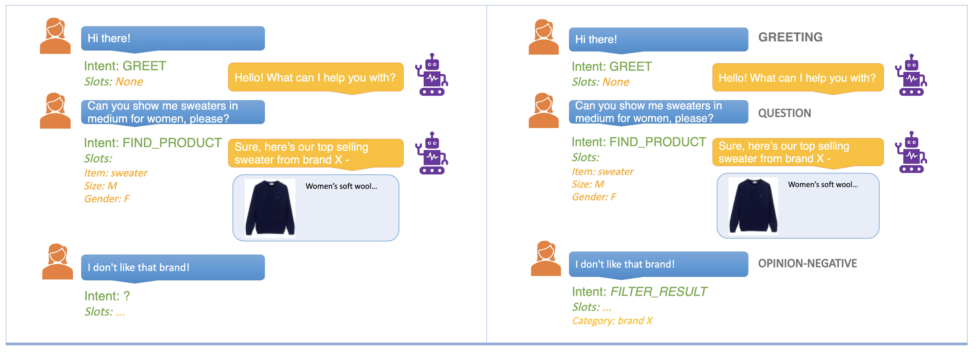
The user starts the interaction with a greeting, followed by a request to find a specific product. In both these cases, the identified intent and slots are sufficient for the bot to respond intelligently and successfully provide a relevant recommendation to the user. The problem arises when the user responds to the recommendation with their impression of the product. What intent should such queries be mapped to, and what entities should be detected? Usually, we’d handle such situations with a prompt to the user to redirect the conversation to something more actionable, like “Hmm, I didn’t understand that. To see more options, say ‘show me more.’”
While this isn’t a terrible user experience, we can make the bot more intelligent by adding an additional classifier module to the NLU system to identify speech acts or dialogue acts.
What are speech acts?
A speech act captures the context and intent of the user in each utterance of a conversation. These intents are different from the regular dialog intents in that they are more general in nature. For example, “How much does this cost?” and “What’s the weather today?” may belong to “GET_COST” and “GET_WEATHER” intents respectively, but they have the same speech act: “QUESTION,” or if you want more granularity, a “WH-QUESTION.” There are different speech act taxonomies defined in literature, and we can use the subset that works for our application. To get a better idea of what these tags can be, refer to the SWBD-DAMSL taxonomy, which provides a rich set of 42 tags.
Speech acts for dialog management
In the user-bot example we presented before, we could have speech act labels of “GREETING” (or “CONVENTIONAL-OPENING”), “QUESTION,” and “OPINION-NEGATIVE” for the three user queries. Now that we know that the last user turn expressed a negative opinion for the brand (tagged as belonging to the entity type “category”), the dialog manager can filter the recommended list to exclude options from the disliked category.
Speech acts to identify actionable items in conversations
Another interesting application of speech acts that we have been experimenting with is using them to extract highlights of a meeting. Unlike summarizing news articles, a well-studied problem, providing an extractive summary of a meeting (i.e., meeting highlights) is difficult since annotated data is hard to come by. There is a lot of subjectivity in what consists of a highlight. For example, an engineer might focus on the implementational details discussed in the meeting, while a product manager may not need the nitty-gritty technical details. This subjectivity, along with the sensitive nature of meeting data, makes it hard to get annotated data to train a model.
Literature and internal surveys have shown that if there is anything people agree on, it’s that action items and follow-ups should be part of the key takeaways of a meeting. Motivated by this, we narrow our focus to identifying actionable items in meetings. Below are examples of what we mean by actionable items. There seem to be two broad categories of how action items are expressed: a speaker promises an action, and a speaker issues a command. This observation makes speech acts a perfect fit to solve this problem.
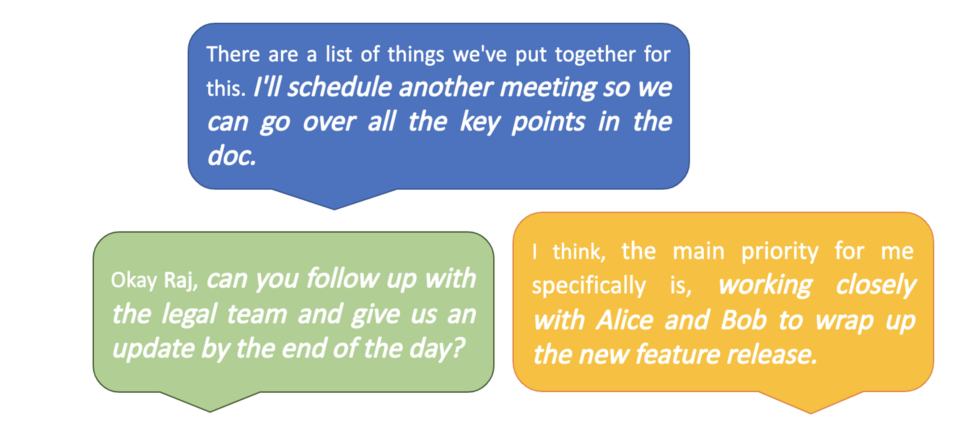
We define our speech act taxonomy for the task as follows:
- Commitments [COM] – A speaker promises to do something
- “I’ll send you an email with the details”
- “I will set up a meeting with Jerry on Monday”
- Directives [DIR] – Speaker asks listener to do something as a response
- “Can you sync up with them tomorrow?”
- “What is your estimate like for this project?
- Elaboration [ELB] – Speaker adds more information to a COM or DIR
- “I will set up a meeting Emma today. The main agenda is to discuss this project with her for more clarity.” (COM followed by ELB)
- “You should start working on the documentation. It will just make the sharing process easier.” (DIR followed by ELB)
- Acknowledgement [ACK] – Speaker acknowledges something
- “Yeah, sounds good”
- “That works for me”
Some commitments and directives aren’t necessarily takeaways since the scope of their actions are limited to the duration of the meeting. For example: “Let me share my screen” or “Can you see my chrome window?” To take care of such cases, we further divide COMs and DIRs into in-meeting (IM) and post-meeting (PM) classes. Sentences that are classified as COM-PM or DIR-PM are the ones we’re interested in capturing for the user as actionable items.
We fine-tune a pre-trained RoBERTa (a transformer variant) model on 50,000 sentences from meetings annotated with these tags. The model has an accuracy of around 82% for predicting the correct speech act when tested on a set of 3000 held-out sentences. To evaluate the end goal of identifying key takeaways in meetings, we asked two expert annotators to annotate 12 meetings with binary labels of whether each sentence in the meeting should be a highlight or not. The model has a high precision of 88%, i.e., 88 out of 100 highlights predicted by the model were correct. The recall, however, is 42%—which means over 50% of highlights are either missed by the model or don’t fit into this schema of commitments or directives. While this leaves a lot of room for improvement, the high precision is very encouraging.
Other applications
We’ve shared only two applications where speech acts are useful, but there are many other real-world use cases. Speech acts help understand the overarching structure of a conversation that can be useful in analyzing call center conversation logs. A recent publication that aimed to automatically make sentences polite used a speech act classifier to identify impolite sentences, then made the required corrections. There are also a few open datasets that you can explore, like the Switchboard corpus and the ICSI Meeting Recorder corpus, which have conversations annotated with a wide range of speech act tags.
At Webex, we encounter conversational speech in multiple forms: in our calling, messaging, and meeting applications, as well as our contact center solutions. We’ve only begun to scratch the surface of how NLP models based on speech acts can help our customers unlock insights from their own data. Stay tuned for more on this topic in the months to come.
Interested in joining the MindMeld team? Send a mail to mindmeld-jobs@cisco.com!
About the author
Varsha Embar is a Senior Machine Learning Engineer on the MindMeld team at Cisco, where she builds production-level conversational interfaces. She works on improving the core Natural Language Processing platform, including features and algorithms for low-resource settings, and tackles challenging problems such as summarization and action item detection in noisy meeting transcripts. Prior to MindMeld, Varsha earned her Master’s degree in Machine Learning and Natural Language Processing from Carnegie Mellon University.
Visit our home page or contact us directly for assistance.
Click here to learn more about the offerings from Webex and to sign up for a free account.
About The Author




