
Introduction
Les systèmes ASR de reconnaissance automatique de la parole fournissent des transcriptions de texte, généralement sous la forme d’une séquence de mots. Cisco utilise des systèmes ASR pour afficher des sous-titres en temps réel pendant les réunions Webex. Mais la lecture de texte sans ponctuation ni lettres majuscules peut s’avérer problématique. En effet, un même texte peut être compris différemment selon sa ponctuation. Imaginez les deux possibilités de ponctuation pour la séquence de mots suivante :« thank you your donation just helped someone get a job »
Option A : «Thank you! Your donation just helped someone get a job. » (Merci ! Votre don vient d’aider quelqu’un à trouver du travail.)
Option B : « Thank you! Your donation just helped someone. Get a job. » (Merci ! Votre don vient d’aider quelqu’un. Allez vous faire voir.)
Un seul signe de ponctuation et tout peut basculer.
Lors du développement d’un système de post-processing, plusieurs facteurs sont à prendre en compte :- Des modèles d’une grande exactitude pour la restauration de la ponctuation et l’application de majuscules à partir du texte brut. Une inférence rapide sur les résultats intermédiaires : pour assurer la génération de sous-titres en temps réel.
- L’utilisation de ressources de petite capacité : la reconnaissance de la parole requiert des calculs intensifs ; nos modèles de ponctuation ne doivent donc pas être eux aussi gourmands en calcul.
- La capacité à traiter des mots ne figurant pas au vocabulaire : la ponctuation ou l’utilisation de majuscules doit parfois s’appliquer à des mots jamais rencontrés par notre modèle.
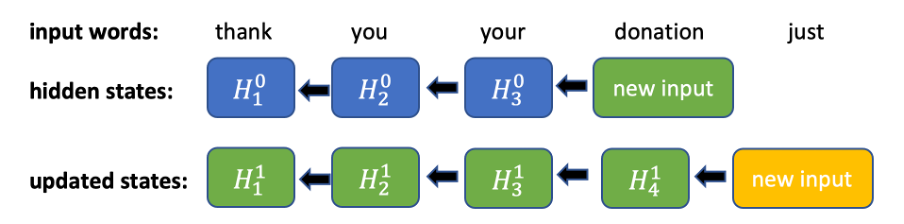
Figure 1. Calculs lors du passage arrière d’un RNN bidirectionnel. Pour chaque nouvelle entrée, tous les précédents états masqués doivent être mis à jour de manière séquentielle.
TruncBiRNN
L’intuition et l’expérimentation ont montré qu’il est essentiel de disposer du contexte à venir pour créer un modèle de ponctuation : si l’on ignore quels seront les prochains mots, il est très difficile de déterminer le signe de ponctuation pour un emplacement donné. Pour utiliser les informations des prochains jetons et ne pas être obligés de mettre à jour tous les états masqués de tous les jetons vers l’arrière, nous avons décidé de limiter le passage en sens inverse à une fenêtre fixe. Dans le sens avant, nous appliquons un RNN ordinaire. Pour le passage en sens inverse, nous prenons seulement en compte une fenêtre fixe au niveau de chaque jeton, en exécutant le RNN sur cette fenêtre (figure 2). L’utilisation de cette fenêtre nous permet d’obtenir une inférence temporelle constante pour chaque nouveau jeton d’entrée (nous devrons calculer un état masqué en sens avant et n+1 en sens inverse).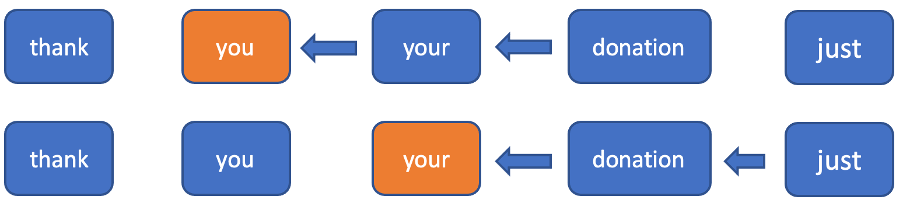
Figure 2. Dans cet exemple, pour chaque jeton actuel, seul les deux prochains jetons sont pris en compte pour le calcul de l’état masqué en sens inverse.
Architecture
L’architecture comprend une couche d’embedding, la couche GRU unidirectionnelle et TruncBiGRU, et la couche entièrement connectée. Pour la sortie, nous utilisons deux couches softmax pour la ponctuation et l’application de majuscules, respectivement (figure 3).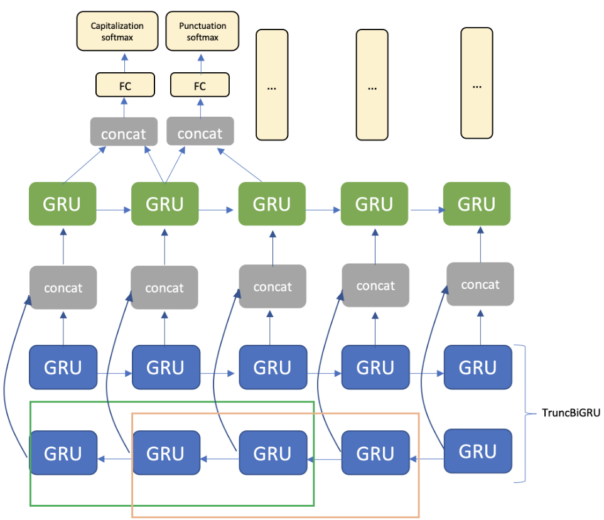
Figure 3. Architecture du modèle avec une taille de fenêtre égale à deux jetons pour la couche TruncBiGRU.
point– un point au milieu d’une phrase qui n’implique pas nécessairement que le mot suivant commence par une majuscule (« a.m. », « D.C. », etc.)
virgule
point d’interrogation
points de suspension
deux-points
tiret
point final – un point à la fin d’une phrase
Concernant l’application de majuscules, nous avons quatre catégories :minuscules
majuscules – toutes les lettres sont mises en majuscules (« IEEE », « NASA », etc.)
capitale
mix_minuscules_majuscules – applicable aux mots tels que « iPhone »
capitale au début – mots commençant une phrase
Les catégories additionnelles, « capitale au début » et « point final » peuvent sembler redondantes au premier abord, mais elles augmentent la cohérence des réponses liées à l’application de majuscules et à la ponctuation. Le « point final » implique que la prochaine réponse d’application de majuscules ne pourra pas être « minuscule » tandis que « capitale au début » signifie que le signe de ponctuation précédent est un « point final » ou un point d’interrogation. Ces catégories jouent un rôle important dans la fonction loss. Fonction loss : Nous devons optimiser à la fois l’application de majuscules et la ponctuation. Pour y parvenir, nous utilisons une somme de fonction log-loss avec un coefficient :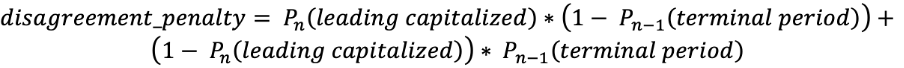 La première condition correspond à la probabilité de trouver « capitale au début » après l’absence de « point final » et la deuxième correspond à la probabilité de ne pas trouver « capitale au début » après « point final ». Cette pénalité s’additionne pour les jetons avec cette erreur. De plus, nous faisons passer deux tenseurs consécutifs de la couche précédente vers les couches softmax. Ceci nous permet de réduire efficacement les conditions de pénalité. Enfin, nous disposons de la fonction loss :
La première condition correspond à la probabilité de trouver « capitale au début » après l’absence de « point final » et la deuxième correspond à la probabilité de ne pas trouver « capitale au début » après « point final ». Cette pénalité s’additionne pour les jetons avec cette erreur. De plus, nous faisons passer deux tenseurs consécutifs de la couche précédente vers les couches softmax. Ceci nous permet de réduire efficacement les conditions de pénalité. Enfin, nous disposons de la fonction loss : 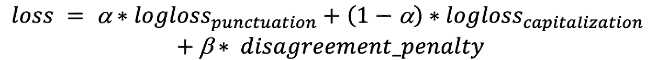
Entraînement
Pour l’entraînement, nous utilisons des transcriptions de texte provenant d’un ensemble de réunions internes à Webex et de données de texte issues de Wikipédia. Pour commencer, les données d’entraînement sont nettoyées et divisées en phrases. Pendant l’entraînement, chaque échantillon est généré depuis des phrases consécutives, puis coupé à une longueur aléatoire depuis une distribution fixe. Le modèle peut ainsi identifier les expressions coupées pendant l’entraînement et donc gérer les résultats intermédiaires durant l’inférence. Ensuite, nous entraînons un modèle sur environ 300 mégaoctets de texte Wikipédia, puis l’affinons avec des transcriptions de réunions Webex. Le pré-entraînement sur Wikipédia aide à améliorer toutes les catégories de ponctuation, mais il est particulièrement utile pour les catégories d’application de majuscules. Nous pensons que cela est dû au grand nombre de noms propres mentionnés dans Wikipédia. Nous appliquons la même préparation des données à nos ensembles d’évaluation en concaténant des phrases, puis en les coupant à des longueurs aléatoires. Nous pouvons ainsi mesurer l’exactitude de ce que nous obtenons généralement aux états de transcription intermédiaires.Conclusion
En ayant recours à des techniques relativement simples et quelques personnalisations de l’architecture, telles que le GRU coupé et une pénalité additionnelle dans une fonction loss, nous avons créé un modèle qui peut être exécuté en ligne. L’expérience de lecture des sous-titres en direct est largement améliorée grâce aux signes de ponctuation et à l’application de majuscules en temps réel. Références [1] A. Gravano, M. Jansche et M. Bacchiani, « Restoring punctuation and capitalization in transcribed speech », ICASSP 2009, 2009, pp. 4741–4744. [2] Monica Sunkara, Srikanth Ronanki, Kalpit Dixit, Sravan Bodapati, Katrin Kirchhoff, « Robust Prediction of Punctuation and Truecasing for Medical ASR » [3] Tilk, Ottokar & Alumäe, Tanel. (2016). Bidirectional Recurrent Neural Network with Attention Mechanism for Punctuation Restoration. 3047-3051. 10.21437/Interspeech.2016-1517. [4] Vardaan Pahuja, Anirban Laha, Shachar Mirkin, Vikas Raykar, Lili Kotlerman, Guy Lev « Joint Learning of Correlated Sequence Labelling Tasks Using Bidirectional Recurrent Neural Networks » [5] Wang, Peilu & Qian, Yao & Soong, Frank & He, Lei & Zhao, Hai. (2015). Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Recurrent Neural Network. [6] Lita, Lucian & Ittycheriah, Abe & Roukos, Salim & Kambhatla, Nanda. (2003). tRuEcasIng. 10.3115/1075096.1075116. [7] https://github.com/google/sentencepiece Inscrivez-vous à Webex Accédez à notre page d’accueil ou contactez-nous directement si vous avez besoin d’aide. Cliquez ici pour en savoir plus sur les offres de Webex et créer un compte gratuit.About The Author


