
はじめに
自動音声認識(ASR)システムは音声をテキストに変換します。通常、変換後のテキストは単語の集まりになります。シスコは ASR システムを使用して Webex 会議にリアルタイムで字幕を表示しています。この場合に生じる問題の 1 つは、句読記号や大文字がないと、字幕として読みにくくなることです。句読記号の有無は、テキストの意味を正しく理解できるかどうかに影響します。たとえば、以下の単語の集まりには句読記号の付け方が 2 つ考えられます。“thank you your donation just helped someone get a job”.
オプション A: “Thank you! Your donation just helped someone get a job.”(ありがとうございます! あなたの寄付は誰かの就業を支援しました。)
オプション B: “Thank you! Your donation just helped someone. Get a job.”(ありがとうございます! あなたの寄付は誰かを支援しました。仕事に就いてください。)
句読記号 1 つでまったく違う意味になります。
そこで、後処理システム構築時の考慮事項について説明します。- 未加工テキストに句読記号の復元と大文字化を行う高精度のモデル。中間結果の高速推論で、リアルタイムの字幕に遅れないようにします。
- 少ないリソース消費量。音声認識はコンピューティング リソースを大量に消費します。句読記号モデルにまで大量のリソースを使用することはできません。
- 語彙外の語句を処理する能力。モデルにとって未知の単語についても、句読記号の復元や大文字化を行う必要があります。
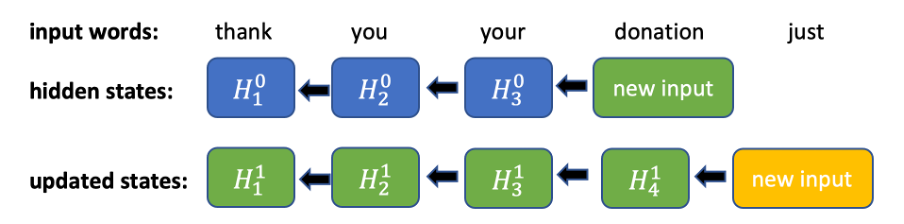
図 1. 双方向 RNN の逆方向パスの計算。新しい入力が加わるたびに、それまでのすべての入力の隠れ状態を順次更新する必要があります。
TruncBiRNN
句読記号モデルの構築において、後から加わるコンテキストが不可欠であることは、直観的にも実験結果からも明らかです。なぜなら、次にどのような単語が来るのか不明な状態で現在位置の句読記号を判別するのは難しいからです。次に来るトークンに関する情報を使用し、逆方向にさかのぼるすべてのトークンの隠れ状態を更新しなくても済むようにするために、逆方向の固定範囲より前を切り捨てることにしました。順方向では通常の RNN の処理になります。逆方向では、各トークンにおいて固定された範囲のみを考慮し、その範囲内で RNN を実行します(図 2)。この範囲を使用することにより、新しい入力トークンに対する一定時間内の推論を実現できます(順方向では 1 個の隠れ状態を、逆方向では n+1 個の隠れ状態を計算する必要があります)。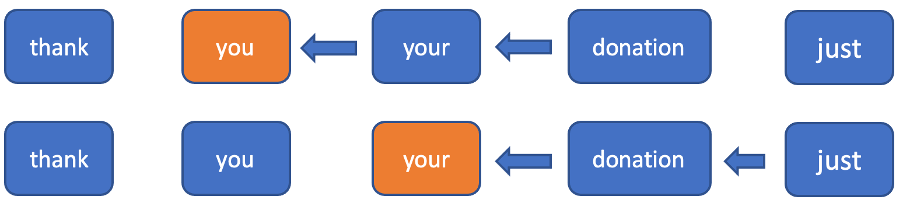
図 2. この例では、現在のトークンごとに、次に来る 2 つのトークンのみを考慮して逆方向の隠れ状態を計算します。
アーキテクチャ
このアーキテクチャは、埋め込み層、TruncBiGRU および単方向 GRU 層、全結合層で構成されます。出力には、句読記号用と大文字化用の 2 つのソフトマックス層を使用します(図 3)。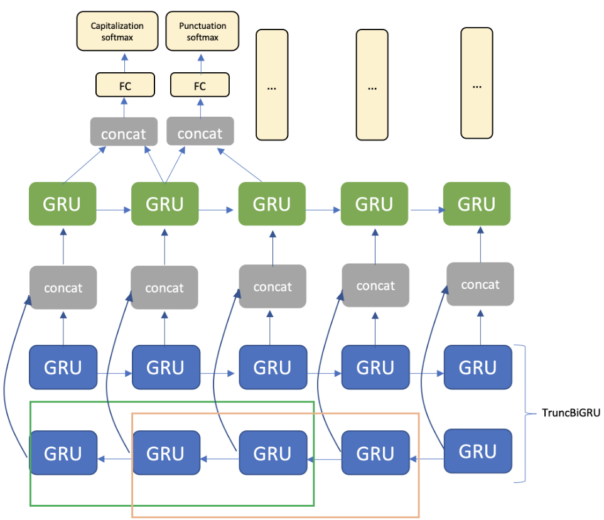
図 3. TruncBiGRU の範囲サイズがトークン 2 個に相当するモデル アーキテクチャ
ピリオド – センテンスの途中に出現するピリオドで、次に来る単語の語頭が必ずしも大文字になるとは限らない(“a.m.”、”D.C.” など)
コンマ
疑問符
省略記号
コロン
ダッシュ
文末ピリオド – センテンスの終了を示すピリオド
大文字化には次の 4 つのクラスがあります。小文字
大文字 – すべての文字を大文字にする(“IEEE”、“NASA” など)
語頭の 1 文字が大文字
大文字と小文字が混在 – “iPhone” など
文頭の 1 文字が大文字 – センテンスの最初の単語
“文頭の 1 文字が大文字” と “文末ピリオド” という 2 つのクラスは、一見すると重複しているように思えるかもしれませんが、この 2 つを使用することで大文字化と句読記号に関連する答えの一貫性を高めます。“文末ピリオド” は、次の大文字化の答えが “小文字” ではないことを意味し、“文頭の 1 文字が大文字” は、前の句読記号が “文末ピリオド” または疑問符であることを意味します。これらのクラスは、損失関数に重要な役割を果たします。損失関数: 大文字化と句読記号の両方を最適化する必要があります。そのために、次のような係数を使う log 損失関数の合計を使用します。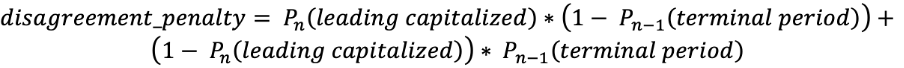 1 つ目の項は “文頭の 1 文字が大文字” が “文末ピリオド” 以外の後に発生する確率に対応し、2 つ目の項は “文頭の 1 文字が大文字” が “文末ピリオド” の後に発生しない確率に対応します。 このペナルティを、この誤りが発生するトークンの合計に加えます。また、前の層からソフトマックス層に 2 つの連続テンソルを渡します。これにより、ペナルティ項を効率的に削減できます。最終的には、次のような損失関数になります。
1 つ目の項は “文頭の 1 文字が大文字” が “文末ピリオド” 以外の後に発生する確率に対応し、2 つ目の項は “文頭の 1 文字が大文字” が “文末ピリオド” の後に発生しない確率に対応します。 このペナルティを、この誤りが発生するトークンの合計に加えます。また、前の層からソフトマックス層に 2 つの連続テンソルを渡します。これにより、ペナルティ項を効率的に削減できます。最終的には、次のような損失関数になります。 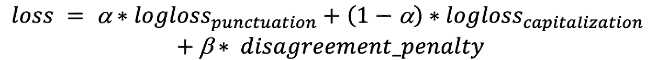
トレーニング
トレーニングには、社内の Webex 会議の文字起こしと Wikipedia のテキスト データを使用します。まず、トレーニング データをクリーンアップし、センテンスに分割します。トレーニング時には、連続するセンテンスから各サンプルを生成し、固定分布からランダムな長さに切断します。これにより、カットされたフレーズをトレーニング時に使用できるため、推論時にモデルで中間結果を処理できます。次に、約 300 メガバイト相当の Wikipedia テキストでトレーニングを行い、Webex 会議の文字起こしで微調整します。Wikipedia を使用して事前トレーニングを行うことは、すべての句読記号クラスの向上に役立ちますが、大文字化クラスには特に効果的です。これは Wikipedia コーパスに含まれる大量の固有名詞が役に立っているものと考えられます。同じデータ準備を評価セットにも適用し、センテンスの連結とランダムな長さへの切断を行います。これにより、中間状態の字幕の正確さを測定できます。まとめ
GRU の切り捨てと損失関数へのペナルティの追加など、比較的簡単な方法を使用してアーキテクチャをカスタマイズすることにより、オンラインで実行できるモデルを構築しました。リアルタイムで句読記号の挿入と大文字化を提供することにより、ライブ字幕の読みやすさが格段に向上します。 参考文献 [1] A. Gravano, M. Jansche, and M. Bacchiani, “Restoring punctuation and capitalization in transcribed speech,” in ICASSP 2009, 2009, pp. 4741–4744. [2] Monica Sunkara, Srikanth Ronanki, Kalpit Dixit, Sravan Bodapati, Katrin Kirchhoff, “Robust Prediction of Punctuation and Truecasing for Medical ASR” [3] Tilk, Ottokar & Alumäe, Tanel. (2016). Bidirectional Recurrent Neural Network with Attention Mechanism for Punctuation Restoration. 3047-3051. 10.21437/Interspeech.2016-1517. [4] Vardaan Pahuja, Anirban Laha, Shachar Mirkin, Vikas Raykar, Lili Kotlerman, Guy Lev “Joint Learning of Correlated Sequence Labelling Tasks Using Bidirectional Recurrent Neural Networks” [5] Wang, Peilu & Qian, Yao & Soong, Frank & He, Lei & Zhao, Hai. (2015). Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Recurrent Neural Network. [6] Lita, Lucian & Ittycheriah, Abe & Roukos, Salim & Kambhatla, Nanda. (2003). tRuEcasIng. 10.3115/1075096.1075116. [7] https://github.com/google/sentencepiece Webex にサインアップする 詳しくは、Webex のホームページをご覧いただくか、直接お問い合わせください。 Webex のサービスの詳細と無料アカウント登録については、こちらをクリックしてください。About The Author

Pavel Pekichev Machine Learning Scientist Cisco
Pavel Pekichev is a Machine Learning Scientist at Cisco working on speech recognition systems.
Learn more


