Since we launched Webex Assistant in 2020, the most common question we have received from our customers is: “Is it accurate?” And I get it; customers want to make sure that if they opt-in to use Webex AI (Artificial Intelligence) automated transcription engine, it will deliver on its promise to keep an accurate record of the meeting, lets meeting attendees focus on the conversation instead of typing meeting notes, and make meetings more inclusive through accessibility features. There are so many examples where artificial intelligence over-promises and under-delivers, and for business-critical tasks, Webex has taken great strides to ensure a relentless focus on accuracy. Machine Learning
As the world moves into a hybrid work model, features like closed captioning, transcription, and capturing action items have become more important than ever in driving equal and inclusive meeting experiences, regardless of what language users speak, what accessibility needs they might have or whether they choose to skip a meeting to juggle their busy lives and lean on Webex Assistant to provide a recap. Our goal is to leverage AI and Machine Learning to make every meeting experience better for everyone.
Webex’s state-of-the-art AI transcription Machine Learning
Given the investment Webex has made in building out robust, end-to-end labeling, training, and machine learning pipelines, we are proud to be able to use this foundation to roll out an English transcription engine that has industry-leading accuracy for the Webex meeting experience when compared to some of the best-in-class speech recognition engines in the market. In an effort to expand the reach of our technology to cover more than 98% of Webex customers worldwide, we will be rolling out Spanish, French, and German ASRs (Automatic Speech Recognition engines) built entirely in-house, which will be offered for free for all Webex Assistant users in H1 of this year.
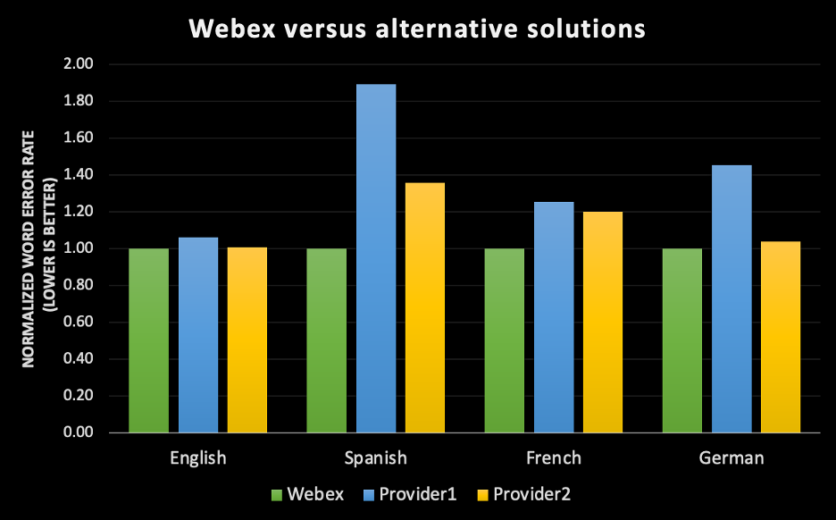
But what does “accurate” really mean? Machine Learning
When we think of an accurate transcription of a conversation, we often envision that if we have a human transcriber listen to this audio file, the transcript will reflect an exact record of what was said. However, to put things in perspective, the human error rate has been measured on some of the popular datasets such as “CallHome” and the best result reported so far is 6.8% error rate; meaning if you have a transcript of 100 words, approximately 7 of them would be transcribed inaccurately by a human. It is also worth mentioning that “CallHome” is a dataset that constitutes unscripted 30-minute telephone conversations between native speakers of English. [1] It is expected that the percentage error for a dataset with speakers of different English accents to be higher.
What is even more interesting is that inter-transcriber agreement as measured by the Linguistics Data Consortium (LDC) ranges between 4.1% and 9.6% depending on whether it is careful multiple transcriptions versus quick transcription [2]. What that means is that if you give an identical audio file to 2 humans, they will still not produce an identical record of what was said even in perfect environmental conditions.
Our goal as we continue to improve Webex transcription to not only be on par with human transcription but to surpass it and achieve the best-in-class accuracy for every language we ship across different accents, genders, and acoustic environments.
So, is the Webex Assistant accurate?
To answer the question “is it accurate?” it’s critical to outline the different dimensions of accuracy in automatic speech recognition:
Accuracy is measured using a common metric called Word Error Rate (WER)
- WER measures how well the machine has performed in transcribing what speakers said.
- The same audio that the machine learning (ML) model has transcribed is given to human labelers to provide a ground truth for the transcription.
- Word error rate (WER) is calculated by dividing the number of errors by the total number of words. To calculate the WER, start by adding up the substitutions, insertions, and deletions that occur in a sequence of recognized words. Divide that number by the total number of words according to the ground truth. The result is the WER. To put it in a simple formula, Word Error Rate = (Substitutions + Insertions + Deletions) / Number of Words Spoken. [3]
- A substitution occurs when a word gets replaced (for example, “Carl” is transcribed as “Car”).
- An insertion is when a word is added that was not said (for example, “middleware” becomes “model where”).
- A deletion happens when a word is left out of the transcript completely (for example, “come up with” becomes “come with”).
- The lower the WER, the better the accuracy of the transcription engine; it means it is making fewer errors.
- In the chart below, we take June 2020 as the baseline for the model we shipped for the Webex Assistant AI transcription engine. You can see that over time we have kept improving our WER reaching 36% incremental improvement by Feb 2022.
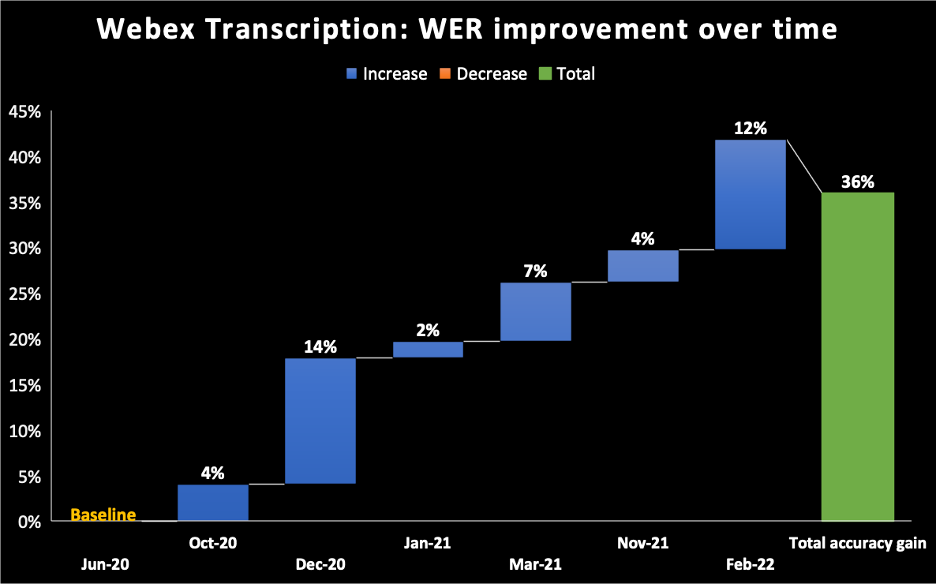
It all depends on the dataset
- There is no absolute measure of WER for any given speech recognition engine. Every dataset has several attributes such as distribution of dialects, genders, acoustic environment, and domains. So, running Webex transcription engine on a dataset of audio books would result in WER that is different from Webex meetings which would be different from telephone calls. Also, running the same transcription engine on Webex meetings for users with native English accents would result in a different error rate if it were run on a Webex meeting where the attendees had accented speech.
- To achieve best in class accuracy, we are solely targeting the video conferencing use case. There are many things that are different about the way people speak in video conferences compared to speaking over the phone or to their Alexa. Our speech recognition engines pick up on those specific patterns and make them optimal for video conferencing. Building an ASR engine in-house versus using a 3rd party provider enables us to train our ML models on those attributes1 specific to the Webex meeting experience.
Accuracy improves over the course of the meeting
- Our Automated Speech Recognition (ASR) creates 3 kinds of transcripts during the lifetime of the meeting:
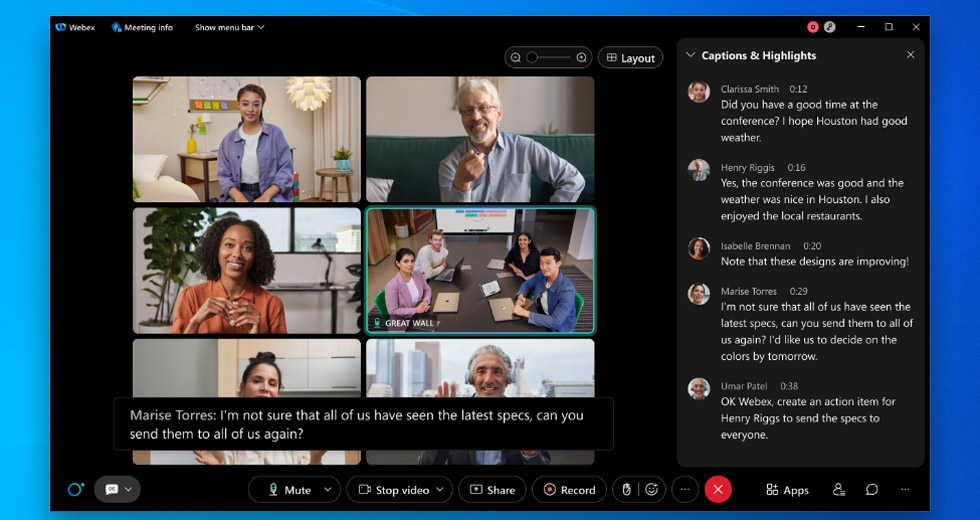
- Draft/interim utterance: draft utterance is what you see in real-time. If you are looking at close captioning in a Webex meeting [black box in the screenshot below] while you are speaking, draft transcript is created in the first milliseconds of transcription and that is the first transcript you see. We call this online/streaming audio transcription.
- Final utterance: After a few milliseconds, another draft of the transcript is created that has better accuracy. All this is happening in real time and can’t be easily distinguished by the naked eye.
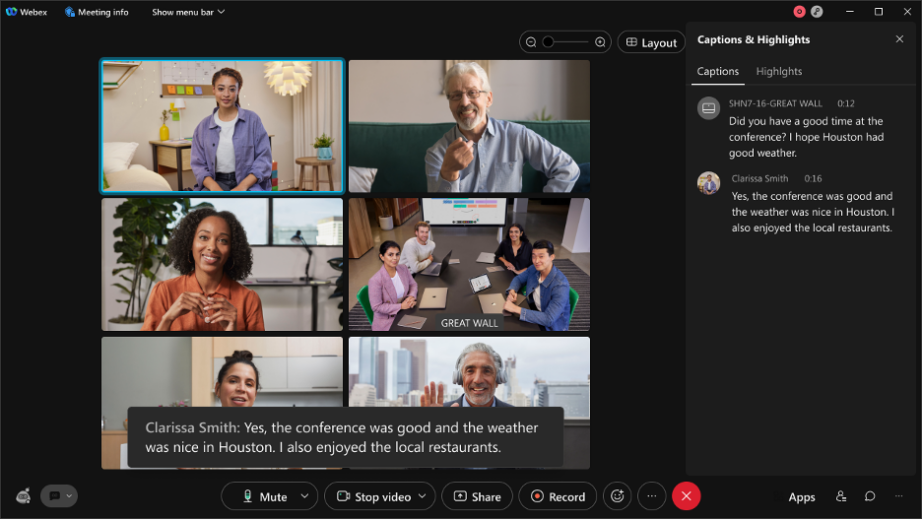
See below example

- In this example for an utterance spoken in one of our team meetings: 13 drafts were created for one statement. All this is happening in real-time to achieve the best accuracy of the final sentence and the real-time user experience.
- Enhanced: After the meeting ends, we re-run an ensemble of additional transcription engines to further enhance the accuracy of the transcript. Enhanced transcripts are available within 10 mins on average regardless of the duration of the meeting. This transcript is the most accurate version of a meeting transcript.
Other transcription issues impact the perception of transcription accuracy
- Punctuation and Capitalization:
- Even though transcription might be accurate, text might not be punctuated or capitalized accurately. Every language has its own punctuation and capitalization rules, and we have to train our models to respect those roles so that the transcript reads well for our users.

- Speaker attribution:
- Speaker attribution attributes a snippet of text to a speaker and identifies who spoke when during a meeting. If an utterance is attributed to the wrong speaker, the perception of quality regresses. Speaker attribution enables us to build interesting features such as meeting analytics around meeting attendees’ speaking time.
- Handling acronyms and names:
- Speech recognition engines are usually trained on common-vocabulary words. That doesn’t include people’s names, company acronyms, medical jargons… etc. For example, the acronym “COVID-19” was a new term to the world before 2020 and our ASR would not have been able to recognize it since it is an out-of-vocabulary word. Our team takes on several approaches to provide a more accurate transcription of out-of-vocabulary words such as learning meeting attendees’ names during a meeting or using computer vision to learn acronyms from a presentation that is being shared during a meeting.
- Handling numbers and special formats:
- Some numbers need specific formatting like phone numbers (+1 203 456 7891), emails (someone@email.com), dates (April 15th, 2021) and others. ML models trained on those special formats identify the words spoken and post-process the text to be displayed in the correct format. All this happens in real time.
- Crosstalk:
- When speakers talk at the same time or interrupt each other, the transcript (even when accurate), might not be readable — impacting quality perception. To solve this problem, we are building features that leverage face recognition and voice print to distinguish different speakers.
Are we there yet? Machine Learning
Not quite. However, it is a marathon not a sprint. We believe that by continuing to train on domain-specific data while striving to mitigate bias and maintain our customer’s data privacy and security, our in-house developed AI transcription engine for Webex would get on par, if not, exceed human word error rate.
If you would like to experience it for yourself, sign up for a free trial today
Citations
[1] G. Saon, G. Kurata, T. Sercu, K. Audhkhasi, S. Thomas, D. Dimitriadis, X. Cui, B. Ramabhadran, M. Picheny, L.-L. Lim, B. Roomi, and P. Hall, “English conversational telephone speech recognition by humans and machines”, arXiv:1703.02136, Mar. 2017.
[2] M. L. Glenn, S. Strassel, H. Lee, K. Maeda, R. Zakhary, and X. Li, “Transcription methods for consistency, volume and efficiency”, in LREC, 2010
[3] What is WER? What Does Word Error Rate Mean? – Rev https://www.rev.com/blog/resources/what-is-wer-what-does-word-error-rate-mean.
Learn more
About The Author