2020 年に Webex Assistant をリリースしてからというもの、お客様からよくいただくようになったのが「精度は良いのか?」という質問です。これはもっともな疑問です。お客様としては、Webex AI (人工知能) の自動音声テキスト変換エンジンを導入すればミーティングの内容が正確にレコーディングされ、出席者がメモをとることに気を取られずにミーティングに集中できるようになり、さらにアクセシビリティの機能を利用して多様な人がミーティングに参加できるようになるという保証を得たいのです。人工知能がもたらす効果を過剰に謳った例や期待外れだったという例は枚挙にいとまがありませんが、Webex ではビジネスクリティカルなタスクにおける精度を確保することに妥協なく取り組んできた結果、著しい進歩を遂げています。 ハイブリッド ワーク モデルへと向かう世界的な潮流の中、字幕作成や音声テキスト変換、アクション事項のキャプチャーなどの機能の重要性が今まで以上に高まっています。そうした機能があれば、ユーザーの話す言語が違うとしても、アクセシビリティに対するニーズが異なるとしても、あるいは多忙を理由にミーティングに参加せず、要点の確認は Webex Assistant の機能に任せるという選択をする人がいたとしても、多様な人が公平にミーティングの場を体験できるようになるからです。シスコの目標は、AI や機械学習を活用してあらゆるミーティング体験をすべての人により適したものにすることです。 その目標を達成する方法の 1 つは、AI を駆使した最新の音声テキスト変換エンジンを開発することです。 信頼できるエンドツーエンドでのラベル付け機能やトレーニング、機械学習パイプラインを開発するために Webex で行ってきた投資を考えると、その経験を基盤に英語の音声テキスト変換エンジンをリリースし、市場に出回っている他社製の同等の音声テキスト変換エンジンと比べても業界随一と言える精度を Webex ミーティングに提供できるのは喜ばしい限りです。シスコでは、世界中で Webex を利用しているお客様の 98% 以上をカバーできるように、この技術の対応範囲を広げるべく取り組んでいます。今年はスペイン語、フランス語、ドイツ語に対応した自社開発の ASR (自動音声認識エンジン) のリリースを控えており、上半期に全 Webex Assistant ユーザーを対象に無償で提供予定です。 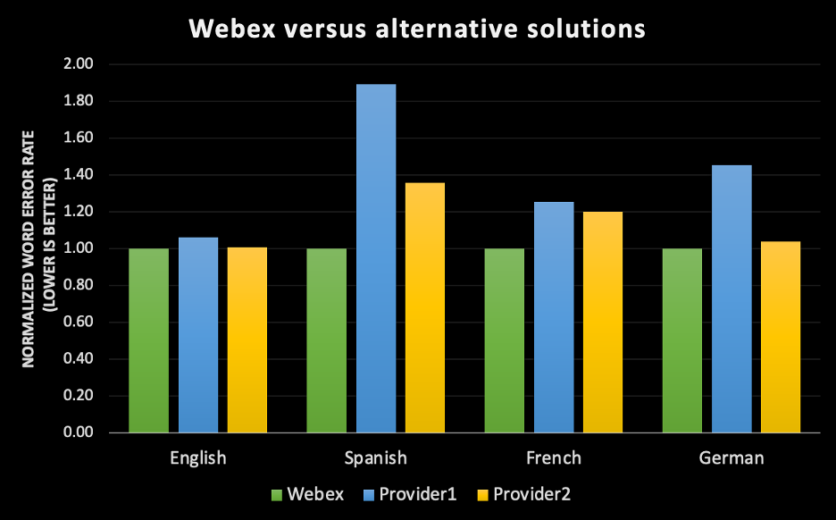


 次の例をご覧ください
次の例をご覧ください 





「精度」という言葉の意味
会話内容を正確にテキストに変換することを考えた場合、私たちはもし音声ファイルを聞き取って記録する議事録係がいたなら、話された内容がそっくりそのまま反映された記録ができるだろうと考えがちです。ですが物事を正しく判断するために「CallHome」のような一般的なデータセットから人為的なミスの発生率を計算してみると、最も良い数値で 6.8% という結果になります。人の手で議事録を作成した場合、100 文字中のおよそ 7 文字は不正確に記録されてしまうということです。ここで、「CallHome」というデータセットが、英語を母国語とする話者同士による台本のない 30 分間の通話記録であることに触れておいても損はないでしょう。[1] 同じ英語でも訛りが異なる話者同士の会話が記録されたデータセットでは、ミスの発生率が増加することが予想されます。 さらに興味深いのは、Linguistics Data Consortium (LDC) が測定したデータによると、議事録係の間のテキスト一致率には 4.1% から 9.6% の開きがあったということです。数値に幅があるのは、注意しながら複数の書き取りを行っていたか速さ重視で書き取りを行っていたかによって違いが出るためです。[2]これはつまり、申し分のない環境条件を整えた上で 2 人の人間にまったく同じ内容の音声を聞いてもらったとしても、それぞれが書き起こした記録には差異が生じるということです。 Webex の音声テキスト変換の改善を続け、その機能を人間による音声の書き起こしと遜色のないレベルに引き上げるにとどまらず、さらにその上を行き、あらゆる対応言語で発音や性別、音響環境に違いがあってもクラス最高の精度を実現することがシスコの目標です。 そこで、「精度は良いのか?」という質問に答えるには、自動音声認識の精度にはさまざまな側面があるという事情を説明することが重要になります。1. 精度は一般的な指標である単語誤り率 (WER) で測定
- WER は機械が話者の発言をどれだけ正確に書き取れたかを測定するものです。
- 機械学習モデルが書き取りに使ったのと同じ音声を人間がラベル付けし、音声テキスト変換の正解を定めます。
- 単語誤り率 (WER) は、正しく認識できなかった誤りの数を単語の総数で除算することで算出します。WER を計算するには、まず単語認識の一連の過程で起きた置換単語数、挿入単語数、削除単語数を合計します。その合計数を、正解の単語の総数で除算します。計算して出た結果が WER です。簡単な計算式で表すと、次のようになります: 単語誤り率 = (置換単語数 + 挿入単語数 + 削除単語数) / 正解単語数。[3]
- 単語の置換とは、単語を取り違えた (例えば本来は「再開」だが「最下位」と書き取った) 場合を指します。
- 単語の挿入とは、実際には含まれない単語を書き加えた (例えば本来は「またミスが」だが「決まったミスが」になった) 場合を指します。
- 単語の削除とは、書き取りの際に単語が欠落してしまった (例えば本来は「あちらに車で行くには」だが「あちらに行くには」になった) 場合を指します。
- WER の数値が小さい方が、音声テキスト変換エンジンが高精度である (誤りの数が少ない) ことを意味します。
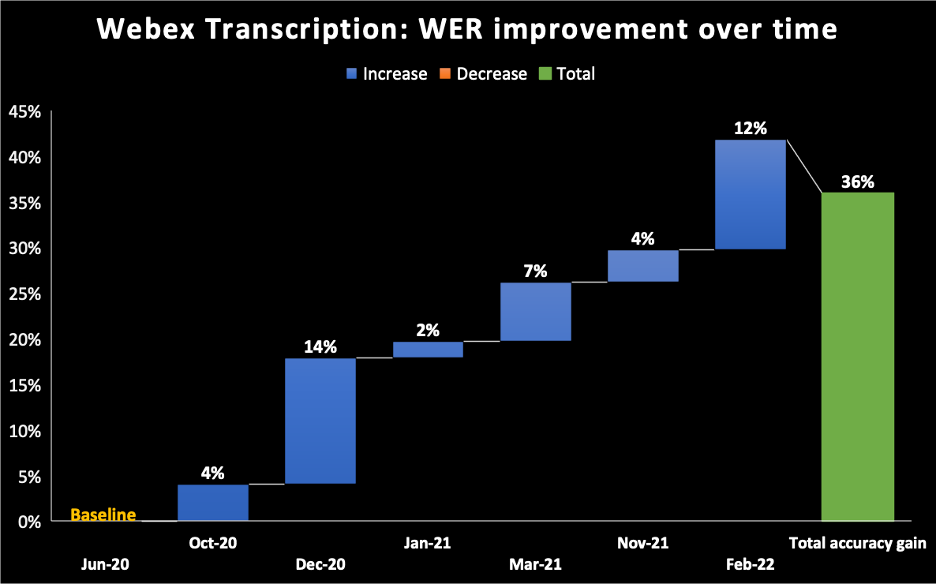
- 次の図は 2020 年 6 月の時点を、Webex Assistant の AI 搭載型音声テキスト変換エンジンモデルの基準点にしています。WER の数字は徐々に改善され、2022 年 2 月には全体で 36% の改善を達成しています。
2. 結果はデータセット次第
- 既存の音声認識エンジンの WER を測定するにあたって完璧な方法は存在しません。どのデータセットにも複数の属性があり、方言や性別、音響環境、地域などにばらつきがあります。そのため Webex の音声テキスト変換エンジンをオーディオ ブックのデータセットに対して実行すると、WER は Webex ミーティングのデータセットの場合とは異なる結果になると考えられます (また、Webex ミーティングは電話とは異なります)。同様に、同じ音声テキスト変換エンジンを、英語を母国語とするユーザーの Webex ミーティングに対して実行すると、その誤り率は、訛りのある出席者のミーティングに対して実行した場合とはやはり異なる結果になると考えられます。
- クラス最高水準の精度を実現するために、シスコではビデオ会議のユースケースのみを対象としています。ビデオ会議での話し方には、電話で話す場合や Alexa に話しかける場合とは異なる特徴がいくつもあります。シスコの音声認識エンジンはそうした特定のパターンを捕捉してビデオ会議という条件に最適化します。内製の ASR エンジンの開発では、Webex ミーティングの体験特有の特徴1 に合わせて機械学習モデルをトレーニングできます。それができることは、サードパーティのプロバイダーを利用する場合と比べて有利な点です。
3. ミーティングの過程で精度を向上
- シスコの自動音声認識 (ASR) 機能はミーティングが終了するまでの間に、次の 3 種類の音声テキスト変換を作成します。
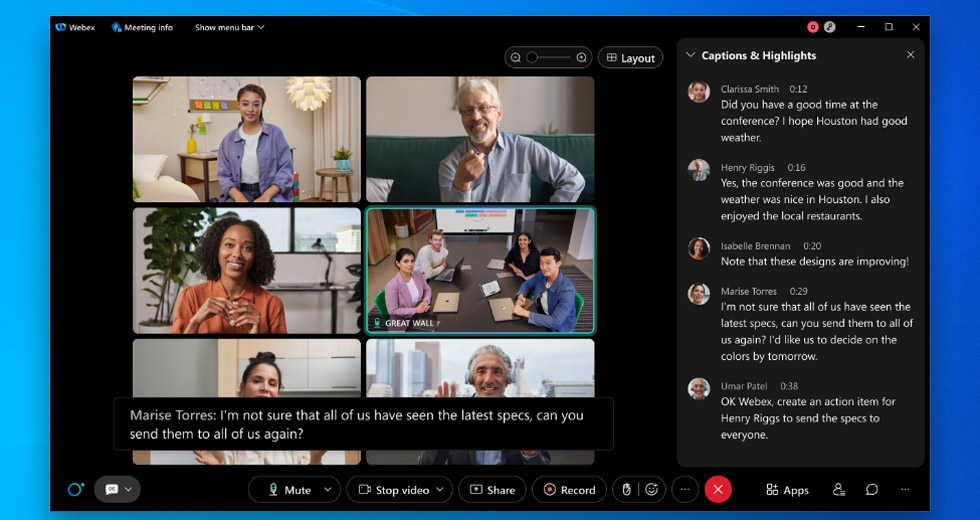
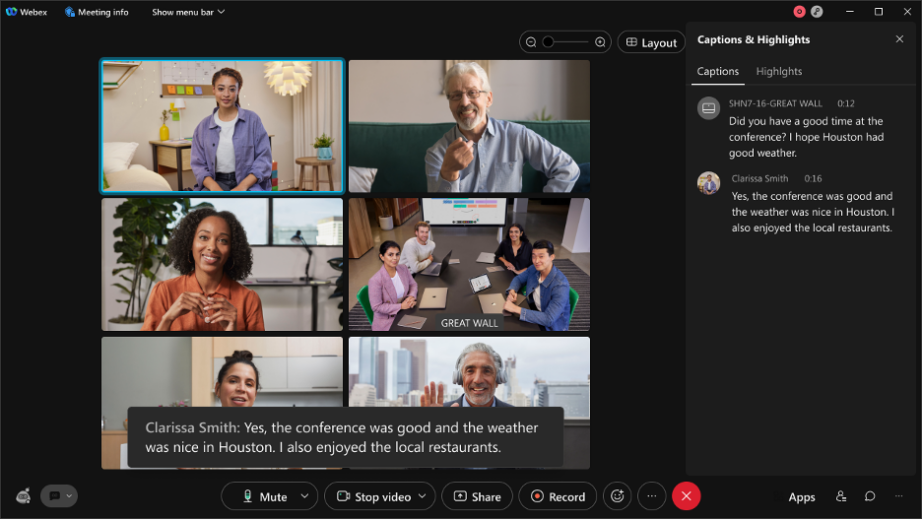
- 下書き/暫定の発言記録: リアルタイムで表示されるのが暫定の発言記録です。何か話しながら Webex ミーティングの字幕 (次のスクリーンショットに映っている黒いボックス) を観察していると、音声テキスト変換が動作した最初の数ミリ秒のうちに、ボックス内に下書きの字幕が作成されるのがわかります。これが一番最初の音声テキスト変換です。シスコではこのテキストを、オンライン音声テキストやライブ音声テキストと呼んでいます。
- 最終的な発言記録: 最初のテキストから数ミリ秒遅れて、下書きがもう 1 つ作成されます。こちらは最初のものよりさらに精度が上がっています。処理はすべてリアルタイムで行われ、肉眼では容易に見分けられないほどです。
次の例をご覧ください - これはとあるチーム ミーティングでの発言を一例として挙げたもので、1 つの発言に対して 13 段階で下書きが作成されています。一連の変化はリアルタイムで起こり、ユーザーは最も正確な最後の 1 文をすぐその場で目にすることができます。
- 改良版: ミーティングの終了後に複数の音声テキスト変換エンジンを掛け合わせて再度変換処理を実行し、音声テキスト変換の精度に磨きをかけます。改良版の音声テキスト変換は、ミーティングの長さにかかわらず平均 10 分以内に完成します。これが最も高精度なバージョンのミーティングの音声テキスト変換になります。
4. 精度に対する認識に影響を与える音声テキスト変換のその他の問題
- 句読記号と大文字の使用:
- 音声テキスト変換は正確だとしても、テキストの句読記号や大文字の処理も正確であるとは限りません。どの言語にも句読法や大文字の使用に関する規則があり、その規則を考慮して機械学習モデルをトレーニングしなければ、ユーザーが読みやすい音声テキストにはなりません。
- 句読記号と大文字の使用:

- 発言者の特定:
- 発言者の特定機能はテキストの断片と発言者を関連付け、ミーティング中に誰が発言したかを判断するものです。発言が誤った発言者に関連付けられれば、品質に対する認識は低下します。ミーティングの出席者の発言時間に関する分析のような機能を開発できるのは、発言者を特定できる機能のおかげです。
- 頭字語と名前の扱い:
- 音声認識エンジンは通常、一般的な語彙に対してトレーニングを行います。この語彙には人名や企業名の頭字語、医療用語などは含まれません。例えば頭字語である「COVID-19」は 2020 年よりも前には使われていなかった新語でした。シスコの ASR 機能も語彙として一般的でないこの語を認識することはできなかったでしょう。私たちのチームでは語彙として一般的でない語をより正確にテキスト化できるように、いくつかの手法を取り入れています。例えばミーティング出席者の氏名を学習させたり、ミーティング中のプレゼンテーションで使われた頭字語をコンピューター ビジョンによって学習させるなどの方法です。
- 頭字語と名前の扱い:
- 数字や特殊な書式の扱い:
- 数字の中には電話番号 (+1 203 456 7891)、電子メール (someone@email.com)、日付 (April 15th, 2021) のように特殊な書式で記述しなければならないものがあります。こうした特殊な書式に対してトレーニングを行った機械学習モデルはそれらの単語が使われたことを識別し、後処理でテキストを適切な書式に変換して表示します。もちろんすべてリアルタイムで処理されます。
- 数字や特殊な書式の扱い:
- クロストーク:
- 複数の発言者が同時に発言したり、他の発言者を遮って発言をした人がいた場合、音声テキスト変換自体は正確に機能しても、テキストは判読が困難なものとなり、品質に対する認識に影響する可能性があります。この問題を解決するために、シスコでは顔認識と音声プリントを利用して発言者を区別する技術を開発中です。
技術の完成度について
今の段階では、まだ完成した技術とは言えません。ですがこれは短距離走ではなく、マラソンなのだと考えてください。偏りを減らすように配慮することと、お客様のデータにおける個人情報保護と安全性の維持を両立させつつ地域特有のデータを使ってトレーニングを続けていけば、いずれは人間にも引けを取らない、あるいは人による誤り率を上回る精度の自社開発の AI 音声テキスト変換エンジンを Webex で提供できると考えています。
Citations 1Training data is only collected under strict privacy and confidentiality terms for users who opt-in to share their data to help improve the quality of the product [1] G. Saon, G. Kurata, T. Sercu, K. Audhkhasi, S. Thomas, D. Dim- itriadis, X. Cui, B. Ramabhadran, M. Picheny, L.-L.Lim, B.Roomi, and P. Hall, “English conversational telephone speech recognition by humans and machines”, arXiv:1703.02136, Mar. 2017. [2] M. L. Glenn, S. Strassel, H. Lee, K. Maeda, R. Zakhary, and X. Li, “Transcription methods for consistency, volume and efficiency”, in LREC, 2010 [3] What is WER?What Does Word Error Rate Mean? – Rev https://www.rev.com/blog/resources/what-is-wer-what-does-word-error-rate-mean.その他の記事 機械学習エンジニアとして Webex に入社した Ritvik Shrivastava のインタビュー インクルーシブな音声とビデオの AI を追求して、コラボレーションの未来を豊かにする Webex で仕事を刷新ご自身の目で確かめたいとお考えの方は、今すぐ無料のトライアルにお申し込みください。
About The Author

Mayada Abdelrahman Director of Product Management, AI/ML Cisco
Mayada Abdelrahman, leads product management for Speech AI/ML features designed for Webex including Cisco’s Webex Assistant, the first-of-its-kind enterprise digital meeting assistant.
In this role, Mayada drives the strategy and roadmap for speech AI/ML features for Webex with the goal of transforming the meeting experience and revolutionizing the way we work providing an inclusive meeting experience for everyone.
Prior to joining Cisco, Mayada led product and program management at Voicea, an AI/ML startup that built “Eva” the meeting assistant which was later acquired by Cisco in 2019.
Learn more